2021年12月30日15:45,哈尔滨工业大学社会计算与信息检索研究中心(哈工大SCIR)举行了Poster交流大会。
自2019年7月以来,哈工大SCIR每学期举办一次学术Poster交流大会,如今已举行至第六届。
本活动的初衷是在提升学生自身综合素质以及学术热情的同时,拓宽学生的知识面,并向不同研究方向的学科组之间提供有效的交流平台。
在学术Poster展创新交流活动中参加同学
张贴学术海报并
讲解相关领域学术成果,同时现场参与及围观的同学进行现场交流。
![]()
本次Poster交流大会的地点为科创大厦,共有9篇Poster参加了此次的交流:
1.
Logic-level Evidence Retrieval and Graph-based Verification Network for Table-based Fact Verification
(EMNLP 2021)
面向表格的事实验证任务的主要目的是根据给定的表格来判断自然语言输入的正确性。不同于其他形式的事实验证系统,表格事实验证任务需要对表格中单元格之间的逻辑关系进行推理,带有逻辑操作的符号推理在这一任务中起到了非常重要的作用。逻辑表达式中包含着必要的逻辑操作,从而可以对表格中观测到的事实进行总结与描述,利用逻辑表达式传达的信息可以更好的理解表格,从而提升表格事实验证任务的性能。本文提出了一种简单有效的范式,利用自动化的方式获取表格中的证据来加强对表格数据的理解,并通过基于图神经网络的方法来对获取到的证据进行建模,获得了显著的性能提升。
2.
Don't be Contradicted with Anything! CI-ToD: Towards Benchmarking Consistency for Task-oriented Dialogue System
(EMNLP 2021)
我们认为生成回复的一致性特性在神经网络为黑盒的对话模型中非常重要, 相比于开放域对话系统的一致性研究,任务型对话系统更为重要,因为它影响最终的用户实际体验。我们贡献了一个数据集,希望促进这块的研究,相比于大部分的开放域对话一致性工作,它有如下几个特点:(1) 考虑真实多轮对话,相比之前单轮一致性更真实(2) 考虑任务型对话系统特定的数据库是否一致的问题(3) 三种细粒度标注,帮助模型诊断当前回复是否与对话历史不一致,用户query不一致,还是对应的知识库不一致。所有数据集,相关baseline代码开源在
https://github.com/yizhen20133868/CI-ToD
。
3.
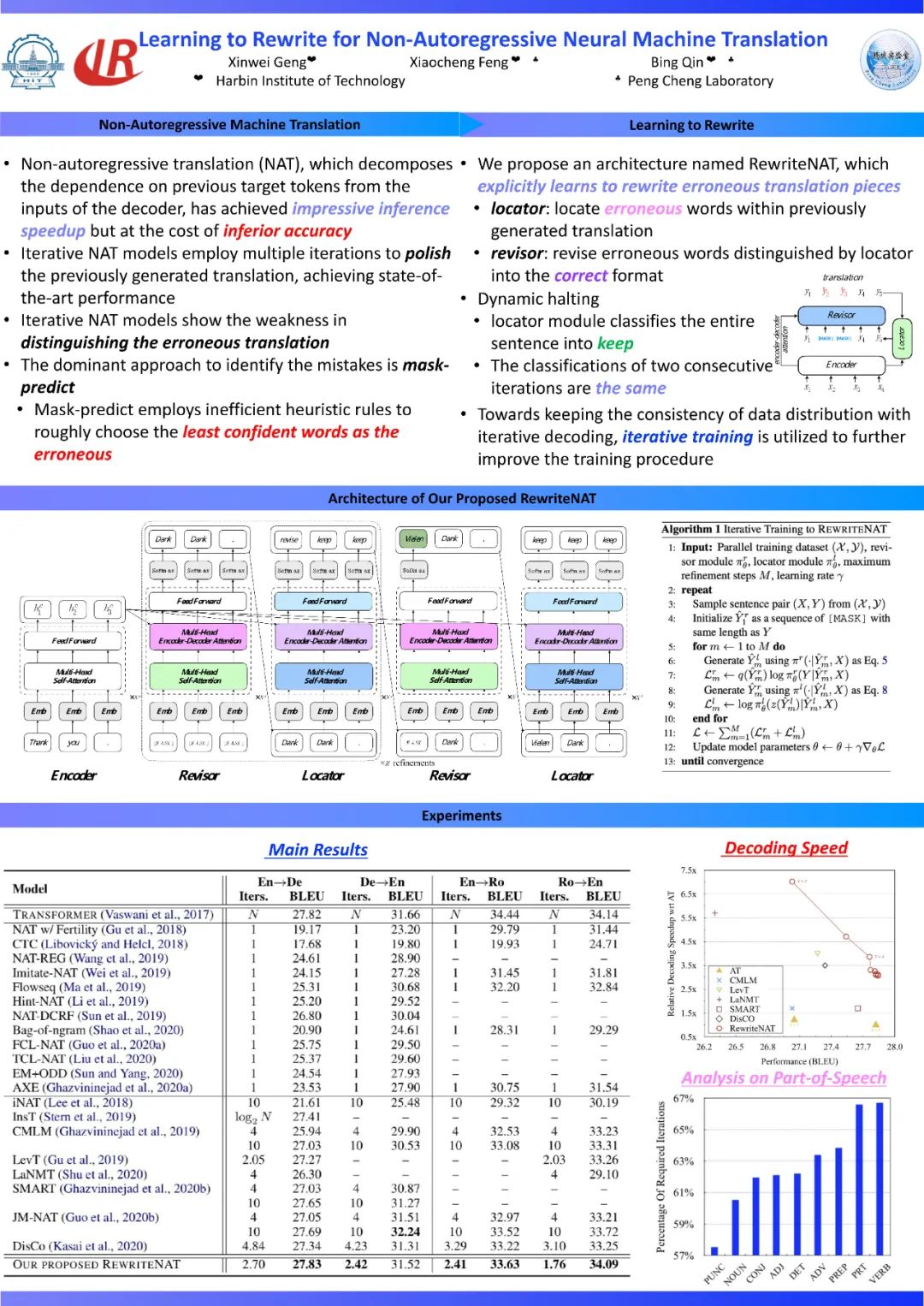
Learning to Rewrite for Non-Autoregressive Neural Machine Translation
(EMNLP 2021)
非自回归机器翻译由于其解码过程不依赖于之前翻译结果从而获得很高的推理速度,但是其翻译质量相对较差。近期许多工作将迭代式的解码策略引入非自回归机器翻译中,其通过多次优化先前的翻译结果从而提升最终翻译质量。但是,其中一个显著问题是在迭代式解码过程中这些方法并不能显示区分翻译结果中的错误。在本工作中,我们提出一个新的非自回归机器翻译架构,其可以学习改写翻译结果的错误内容。该架构使用一个定位模块识别翻译中的错误,而后使用另一个改写模块将其改写成正确翻译内容。此外,为了保证训练和迭代式解码过程中输入数据分布的一致性,我们采用迭代式的训练方法进一步提升模型的改写错误能力。在多个广泛使用的翻译数据上的实验结果显示,相比多个传统的迭代式非自回归方法,我们提出方法可以获得更好的翻译性能,同时显著的减少解码时间。
4.
Allocating Large Vocabulary Capacity for Cross-lingual Language Model Pre-training
(EMNLP 2021)
与单语模型相比,跨语言模型需要更大的词表来充分表示所有语言。在近期的跨语言模型中,许多语言没有被分配足够的词汇量,导致这些语言不能被很好的表示。为此,我们提出了VoCap,该方法通过分别评估每种语言所需的词汇量来生成更大的多语言词表。然而,增加词汇量会减慢预训练速度,并使模型参数量更大。为了解决这些问题,我们首先提出了基于 k-NN 的目标采样(k-NN-based Target Sampling),通过估计Softmax 来加速大词表模型的预训练。同时我们减少输入和输出词向量维度以保持模型参数量不变。我们在XTREME上进行了实验,结果表明使用VoCap得到的多语言大词表有益于提升跨语言模型的性能。此外,基于 k-NN 的目标采样和减少词向量维度的策略减轻了增加词表大小的副作用,在实现了可比性能的同时大幅度提升了预训练速度。
5.
DuRecDial 2.0: A Bilingual Parallel Dataset for Multilingual and Cross-lingual Conversational Recommendation
(EMNLP 2021)
在本文中,我们构建了首个中英双语平行的包含多种对话类型、多领域和丰富对话逻辑(考虑用户实时反馈)的human-to-human对话推荐数据集DuRecDial 2.0,使研究人员能够同时探索单语言、多语言和跨语言对话推荐的性能差异。DuRecDial 2.0与现有对话推荐数据集的区别在于,DuRecDial 2.0中的数据项(用户Profile、对话目标、对话所需知识、对话场景、对话上下文、回复)都是中英平行的,而其他数据集都是单语设定。DuRecDial 2.0包含8.2k个中英文对齐的对话(总共16.5k个对话和255k个utterance),这些对话都是通过严格的质量控制流程,由众包人员标注而成。然后,我们基于DuRecDial 2.0,设定了5个任务(包含单语言、多语言和跨语言对话推荐),并基于mBART和XNLG构建单语、多语和跨语言对话推荐基线,支持未来研究。实验结果表明,使用英语对话推荐数据可以提高中文对话推荐的性能。
6.
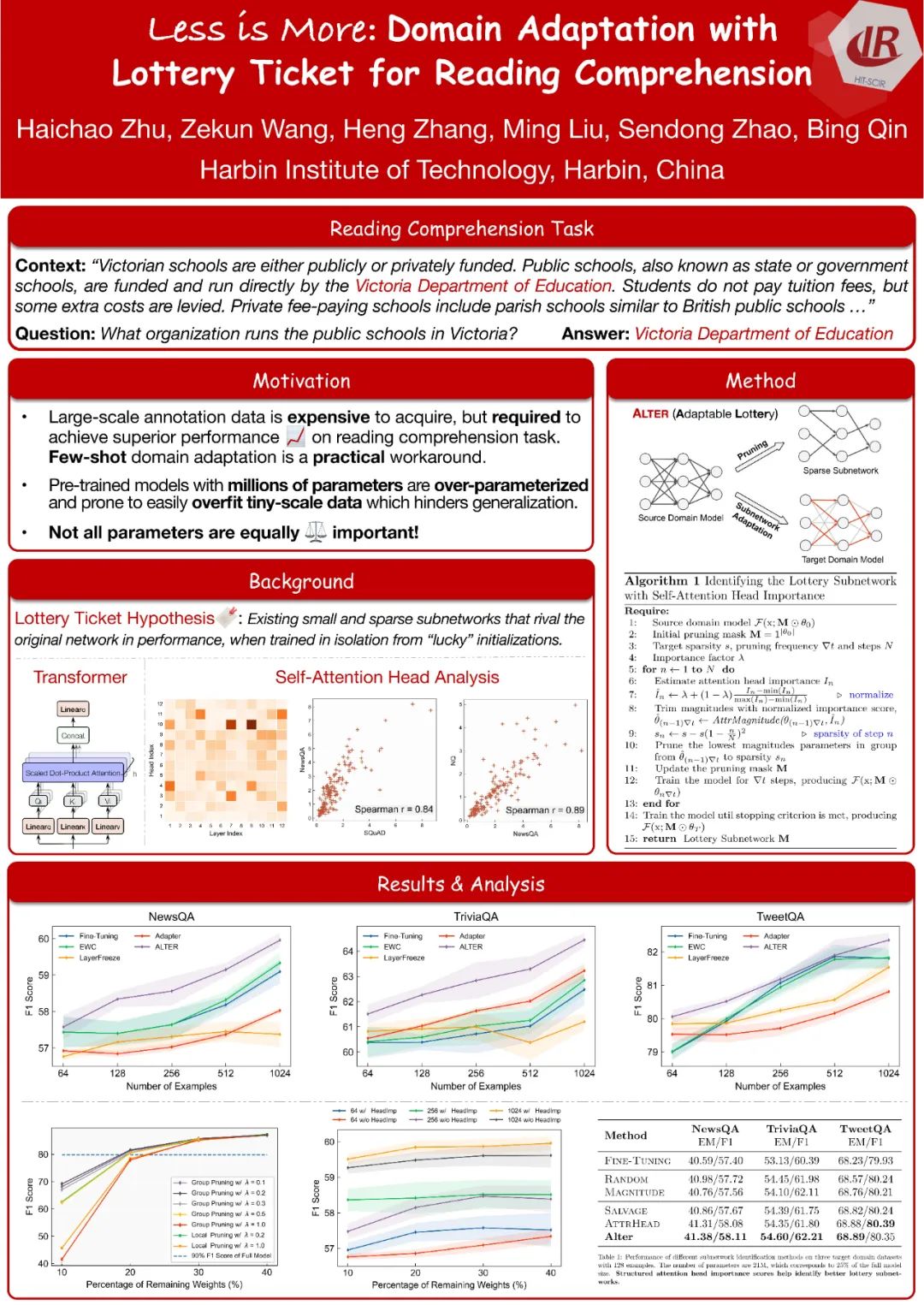
Less Is More: Domain Adaptation with Lottery Ticket for Reading Comprehension
(EMNLP 2021)
在本文中,我们提出了一种用于阅读理解的简单的小样本域适应方法。我们首先识别出基于 Transformer 的源域模型中的子网络。然后,使用目标领域上的标注数据来更新子网络的参数(占整个模型参数的一小部分)来进行领域迁移。为了获得更具迁移性的子网络,我们引入了自注意力归因来帮助识别子网络,通过这种方法,我们同时考量参数的结构化与非结构化重要性。实验结果表明,进行少样本领域迁移时,我们的方法在四个目标领域上优于微调全部参数及三个基线方法。此外,引入自注意力归因后,子网络包含了更多的来自重要的自注意力头(Self-Attention Head)的参数,提高了领域迁移的性能。进一步分析表明,除了利用较少的参数进行领域迁移外,子网络的选择对有效性有非常重要的影响。
7.
Retrieve, Discriminate and Rewrite: A Simple and Effective Framework for Obtaining Affective Response in Retrieval-Based Chatbots
(EMNLP 2021)
获得情感回复是建立共情对话系统的关键步骤。这个问题在生成式聊天机器人中已经有很多研究,但是在检索式聊天机器人中还未受到广泛关注。检索式聊天机器人中的现有相关工作基于"检索-重排序"框架,通常会优先满足情感目标而牺牲回复相关性。在本工作中,我们提出了一个简单有效的"检索-判别-重写"框架来解决这个问题。该框架在原有检索机制的基础上增加了两个新模块,其中新的判别模块用于判断高质量检索回复的情感,而新的重写模块用于实现对情感不一致回复的微调,三者共同作用使得回复情感和内容可以兼顾。此外,该领域目前缺乏合适的公开数据集,本工作在豆瓣对话语料库的基础上标注了一个新的情感回复数据集,以支持实验和后续工作的开展。实验结果表明,现有"检索-重排序"方法在情感目标满足时回复质量严重下降,而我们的"检索-判别-重写"方法则有效解决了这个问题,并在大多数评价指标上都明显优于现有方法。
8.
Text is no more Enough! A Benchmark for Profile-based Spoken Language Understanding
(AAAI 2022)
口语语言理解(SLU)的研究目前主要局限于简单的设置,也即基于纯文本的SLU系统,将用户话语作为输入并生成其相应的语义信息(如意图和槽位)。但这样的系统可能无法在复杂的现实世界场景中发挥作用,当语义存在歧义时,仅基于纯文本的SLU系统就无法产生正确的语义信息。本文首先介绍了一个重要的新任务——基于Profile的口语语言理解(ProSLU),它要求模型不仅要依赖纯文本,而且要充分利用辅助的特征信息来预测正确的意图和槽位。为此,我们人工标注一个大规模的中文数据集,其中有约五千条的用户话语及其对应的Profile信息(知识图谱(KG),用户配置(UP),环境感知(CA))。此外,我们评估了几个最先进的基线模型,并探索了一个多层次的知识适配器,以有效地利用Profile信息。实验结果显示,现有的基于纯文本的SLU模型在语义存在歧义的情况下都效果不佳,而我们提出的多层次的知识适配器可以有效地融合Profile信息,从而在句子级的意图检测和标记级的槽位填充任务中更好的利用Profile信息。最后,我们总结了关键的挑战,并为未来的发展方向提供了新的观点,希望能促进这方面的研究。
9.
Mitigating Reporting Bias in Semi-supervised Temporal Commonsense Inference with Probability Soft Logic
(AAAI 2022)
对以事件为核心的自然语言理解任务而言,使得模型掌握一定的时间相关的常识知识十分重要。但是由于“报告偏差”(Reporting Bias,即人们在日常交谈、书写时往往不会提及常见的情况而对不常见情况加以强调)问题的存在,从大规模文本中以无监督的方式抽取到时间常识知识往往是有偏的,基于这些有偏数据以简单方法训练得到的模型也往往不能达到理想的性能。为此,前人的工作中提出通过引入不同维度(如典型发生时间,持续时间,发生频率)的时间常识之间的互补关系来解决报告偏差的问题。本文认为,前人的隐式的建模互补关系的方式是数据驱动的,存在建模不充分且不可解释的问题。本文则是详细总结了不同维度时间常识的知识的互补关系,将之表示为一阶逻辑,然后以端到端的方式,使用逻辑约束损失显式优化对不同时间维度的表示,使得模型预测结果能够与逻辑知识一致。在intrinsic和extrinsic数据上的实验上均展现了我们的方法相较于前人工作的优越性。
此次Poster交流大会从15:45开始到17:00结束,参展的9篇Poster涉及对话、机器翻译、情感分析等多个领域。其间实验室全体师生在科创大厦展览区就参展Poster进行了热烈的讨论,在交流和创新中充实完善了自己的知识体系。
![]()
本期责任编辑:冯骁骋
理解语言,认知社会
以中文技术,助民族复兴