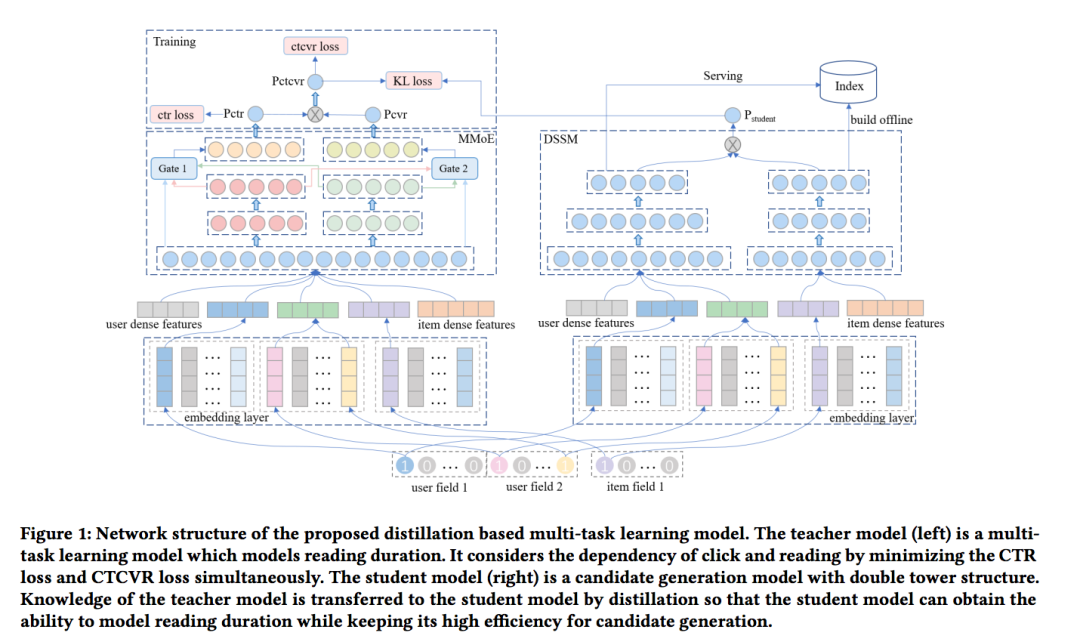
“互联网推荐一点通” 是火山引擎的智能推荐团队运营的公众号,定期从各大顶会精选推荐/搜索相关论文,并从背景、方法、实验、创新点以及点评等五个方面对论文进行解读。
1. 背景介绍
推荐系统中,点击率预估是很通用的排序方法。但是,在feeds流中,pCTR只能说明用户点击这个内容的概率,而不能说明用户有多喜欢或者说在点击之后是否有可能阅读或者停留的概率。有些低质量但是标题党的内容,用户就很容易点击。但其实点击完之后,可能并不会阅读。所以,只对点击建模不能保证用户对这些点击过的内容的满意度。在feeds流中,为了提升用户体验,阅读时长也应该被考虑进来。
这篇论文中,作者主要聚焦如何在召回中融入阅读时长。具体实现时,有两个挑战:
1)如果阅读时长为0,不一定是不喜欢,这个和正例里面的阅读时长比较短的还有差异。阅读时长比较短说明确实不怎么喜欢,但是阅读时长为0可能仅仅因为用户没有点击而已(比如因为位置、展示、标题等等原因,用户没有去点击)。直接用0来作为阅读时长的label有可能是有偏的。2)第二个挑战来源于第一个。如果用多任务类似于ESSM来debias的话,那么,如何把多任务用在召回模型上是有点困难的,因为大多数召回模型都是双塔结构的。另外,之前做阅读时长,大部分都是做成回归任务,用mse。这样就和第一个挑战里说的一样,是有偏的。
为了解决该问题,作者提出了名为 DMTL的多任务蒸馏模型。把阅读时长理解为cvr任务,click理解为ctr任务。然后把多任务的学习知识蒸馏到双塔网络中。
DMTL的目的就是同时建模 click和duration来提高候选的质量,而不是只看click。对于ctr任务,正例就是clicked,负例就是按频次全局随机采样。对于duration任务,正例是duration > 50s, 反之负例。
和
分别表示用户特征和内容特征。
表示
和
特征的concat,加上和其他一些特征的concat的embedding向量。
表示click的label,
表示duration的label。duration的建模就是,当给定
,
的概率,即
。和上面提及到的一样,duration是依赖click行为的。因此可以重写成:
。其中,
表示pCTR,
表示pCVR,
表示pCTCVR。为了解决样本选择偏差和数据稀疏性问题,作者借鉴了ESSM论文中的做法。
作者利用MMoE来建模CTR和CVR。用
表示第k个expert网络, 对应的
表示第k个expert的输出。对于CTR任务,门控网络的门函数是
。其中
表示门函数。
表示训练的matrix,
表示
expert的数量。
就是
的第k个值。CTR任务的输出值就是,
。对于CVR任务,门控网络的门函数是
,CVR任务的输出值就是
。
对于一个样本
,
pCTR被定义
,pCVR被定义为
。其中,
和
都是最后一层维度=1的nn网络,
就是所有的网络参数。根据上文推导结果,pCTCVR可以被改写成
。
用二分类的交叉熵损失来算pCTCVR任务(duration任务)的loss:
pCTCVR中引用了pCTR。但是如果只去拟合
,是不能保证
拟合到CTR的。所以,作者加了个辅助loss:
综上,整个teacher网络的loss为上述loss之和,具体通过两个权重调整:
大多数的深度召回都是用的双塔结构,离线把item 的向量构造好索引。线上给定一个user的vector,用user和item向量做内积,然后用ANN在索引中检索TopK返回。而由于内积只能建模单任务,如果想用多任务建模duration,这样的方法就不能满足了。因此,为了让双塔结构能够具有额外建模duration的能力,作者用了蒸馏来把多任务的知识迁移到双塔网络中。
具体还是利用双塔结构来分别生成user和item的向量,用
和
分别表示user和item的向量,
和
是nn层,用来把输入的embedding输出成vector。给定
和
,基于CTCVR预估生成的候选则定义为:
,其中
表示
和
的内积,
是双塔网络的网络参数。期望
和teacher网络输出的
尽可能相似。若能如此,则既能使用双塔输出的user和item的内积来预估CTCVR,同时又能高效的做召回了。
为了达到上述目标,则把左边的多任务学习任务当做teacher网络,右边的双塔结构当做student网络,用蒸馏把teacher网络的知识迁移到student网络。student网络的loss用KL-散度来定义:
整个模型的loss就是teacher网络和student网络的loss相加,即
训练时为了防止teacher网络被student网络影响,student网络的参数独立于teacher网络训练的。因此当
被引入到stdudent的loss中时,被暂停了梯度。线上serving时,只用student部分来计算user和item的向量,同样,还是离线计算好item的vector和索引。具体使用user的vector作为query,用ANN检索topk的item返回。
腾讯看点feeds流上收集的大概亿级的训练样本,百万的测试样本。对于每个用户,正例是曝光点击过的item,负例是从全局按照点击频次随机采样。每个曝光点击的item都有大于等于0的阅读时长,每个负例的duration=0。
双塔-回归:把user和item的vector内积后,和duration做回归任务,squared_loss作为损失。
双塔-分类:把user和item的vector内积后,和duration(>50s正例,<=50s负例),做分类任务。
双塔-click:把user和item的vector内积后,和click做(曝光点击正例,其余负例)分类任务。
对所有方法都评估二分类auc的表现,正例是 点击过且duration 大于50s的是正例,其他是负例。
teacher网络:experts [1024, 512, 256], 2个experts。其他的nn层是[256, 256]。student网络:隐层 [512, 256, 128]。两个网络的embedding szie都是 30。
![]()
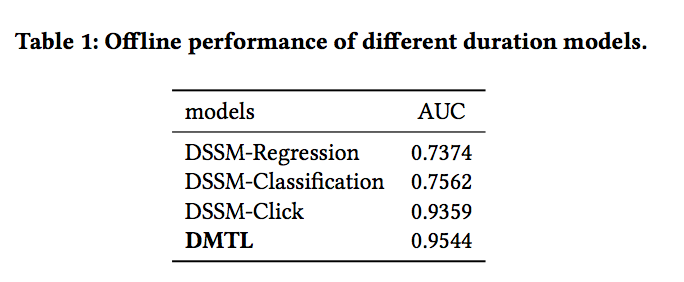
DSSM-Regression最差:因为它直接拟合了大量的duration=0的负例。
DSSM-Classification其次:因为它的负例直接是duration=0,对于没点击和很短的duration的样本没有区分好。
DSSM-Click:表明了click对于duration的重要性。但它没学到duration方面的知识,因此比 DMTL还差了点。
![]()
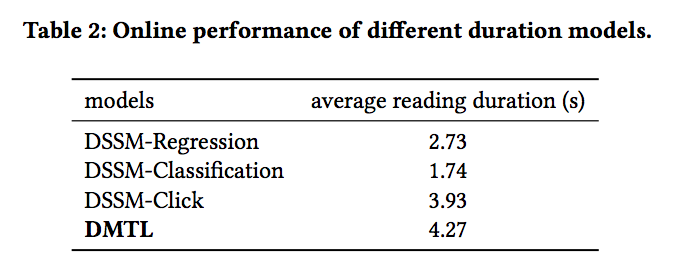
在线的ab实验用T / M(平均阅读时长)来评估,T 表示所有阅读时长的总和,M 表示所有曝光次数。可以看到在线表现和离线评估结果基本是一致的。其中比较特别的是DSSM-Classification的在线表现比DSSM-Regression更差。作者认为主要是因为缺乏对duration前置信息的建模导致线上预估不准,离用户真实兴趣相差较远。
这篇论文中,作者提出了基于蒸馏的多任务学习框架来建模阅读duration来进行召回。其中阅读时长和点击模型的融合方式有一定借鉴意义,召回蒸馏精排的方式也是一种通用的全链路一致性建模方式。
不过论文也存在一定不足。部分对效果影响比较大的因素如loss调权未做过多阐述。消融实验不够完善:例如精排模型的结构是否有必要这么复杂,对召回模型影响又有多大;又或者是否一定需要以蒸馏的方式来召回学习精排,直接引入精排预估分作为soft分效果如何。duration 50s作为阈值的正例判定规则也有些过于粗暴。