播放内核的“瘦身”,你只需要这样做!



概述
优酷播放内核是优酷自主开发的一个基于pipeline结构的SDK。它对上承接了优酷丰富灵活的业务逻辑,对下屏蔽了各端系统的差异,是一个高可靠、可扩展、跨平台的优秀播放SDK。
但是,跨团队协作及长时间的迭代,也使得当前播放内核显得有些“臃肿”。占用内存过高、使用线程太多等这些问题除了会影响用户的体验之外,也在一定程度上制约了一些业务的实现,例如针对短视频的多实例方案。所以,急需对内核各模块进行一次“轻量化”的改造。目标是:
1)更少的线程
2)更小的内存
3)更低的功耗

改造前的摸底
优酷播放内核实现了一套基于pipelie的框架,结构如下:
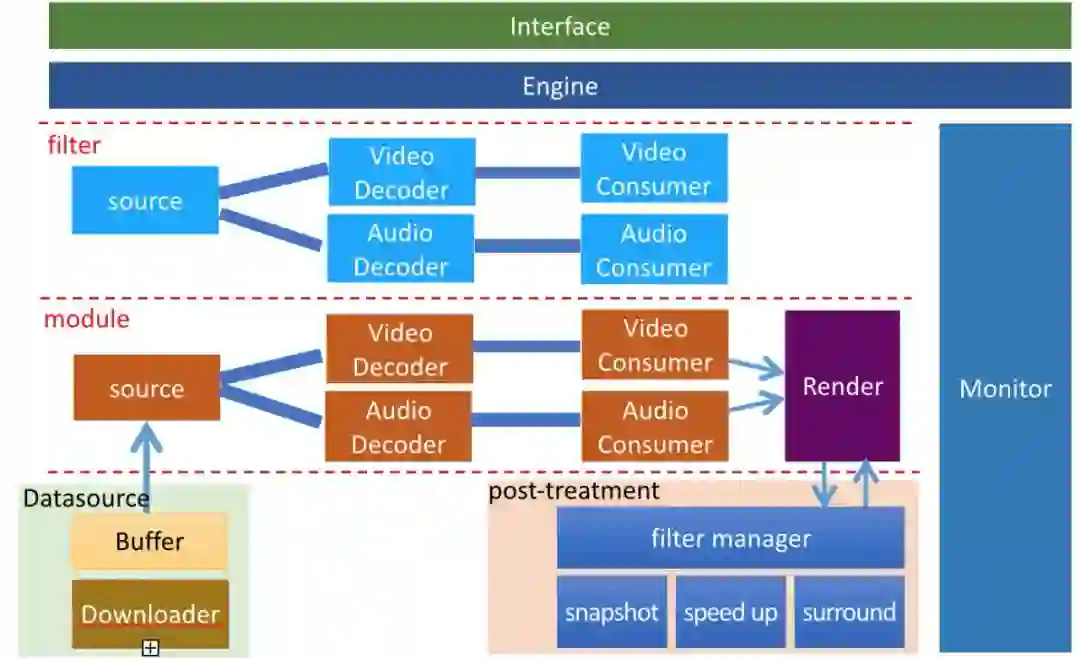
包含了接口层,处理命令和消息上报的engine,透传消息的filter层,主体干活的module层,数据下载模块以及渲染和后处理模块。
经过梳理跟测试,确认我们的播放内核使用的线程会比一些开源的播放内核(比如ijkplayer)多很多,内存使用量以及视频耗电量等数据相比竞品也处于劣势。所以我们亟需对我们的播放内核进行一轮改造。

改造的详细过程
我们改造的方向包含:线程、内存、功耗这三个方面。希望用最少的线程实现整个播放流程,用最小的内存使得播放依然流畅,占用最少的cpu资源使得播放更持久。
采用的策略是做“加法”。根据播放流程,保留必要的线程,去除冗余的线程,重用可复用的线程。然后review每一个保留下来的线程,测试使用内存及cpu占用率是否符合预期,如果异常再进行逐一排查。
▐ 线程精简
优化前内核使用的线程数有近30个,相比其他开源播放器多了很多。其中有些是必不可少,有些是可被其他线程复用,还有些是逻辑冗余,可以直接去除。在梳理要留下哪些线程的时候,我们考虑了一个播放过程所需要的线程“最小集”,应该会包括如下一些线程模块:
engine:用于接收接口命令,以及上报内核消息;
source:用于数据读取并驱动pipeline数据向后流动;
decoder:音视频各一个,用于音视频数据解码;
consumer:音视频各一个,用于同步及渲染;
hal buffer:用于解复用及缓存状态监控;
ykstream:用于控制下载模块并和切片解析模块交互;
render:用于渲染管理。
可以看到,播放流程必须用的线程其实就9个。而其他的线程除了预加载管理、播放质量监控以及字幕相关等在需要的时候会被启用之外,其余都可以去除。
精简步骤如下:
1)去除多余的filter线程
filter只有在创建module的时候用到,后面都是消息透传,显得有些多余,所以可以直接去除。将创建module的逻辑移到engine的prepare流程,打通engine与module之间的消息通道,上面下达的命令以及下面上报的消息不再经过filter。
2)去除消息传递器和时钟管理器
优化前消息上报通道比较混乱,有些直接上报给engine,有些上报给消息传递器进行一次中转,然后再上报给engine。消息传递器这层逻辑有些多余,所以去除了这个线程,所有消息上报都通过engine。
时钟管理器作为同步时间来用,这个不需要线程,线程的存在是用作一个定时器。目前内核使用到定时器的就一两个点,通过其他线程逻辑复用,去除了对定时器的依赖,这个线程也可以去除。
3)去除接口命令线程和消息上报线程
接口层加了一个线程中转一个下发的命令,目的是为了接口超时的时候内核有forcestop的机制。在经过多轮优化后,内核触发forcestop的情况大大减少,所以这个线程显得有些多余,就算还会出现卡住的情况,也会有anr来替代原先的crash,这个线程可以去除。
消息上报线程是为了内核层多实例上报消息加上的,实际上经过代码复用,这个线程也不是必须的,可以去除。
4)去除解复用线程和二级缓存线程
内核获取数据一直是逻辑最臃肿的地方,优化前有5个线程来实现这部分功能。优化后保留3个即可,解复用线程和二级缓存线程可以去除。
5)去除预加载管理器和字幕解码模块
预加载管理器不管有没有开启预加载都会运行,需要加上开关控制,只有在预加载开启情况下才会运行。
字幕的实现主要是数据读取、解析和render,其中不同于音视频,文本信息在读取后就可以直接去解析,所以字幕解码模块可以去除。
优化后,线程有9个必须的,加上播放质量监控,总共保留12个线程。没有字幕的视频只剩下10个。
▐ 内存裁剪
消耗内存地方主要有四处:缓存下载数据的buffer、pipe管线中的buffer、存msg信息的结构体、以及各class对象的内存。class对象除非不用,否则没有太多裁剪的空间,所以内存裁剪就从缓存、pipe管线及信息存储结构体三个角度去实行。
1)排查内存使用不符合预期的地方
扫描线程内存数据发现,读buffer的线程内存消耗高出设置值很多。分析每个es sample的数据,发现除了数据部分之外,还存了一个codec的context,每个packet都要存一个。各packet的codec context都应该是一样的,只需存一份即可。内核针对这部分不合理的逻辑进行了修复,内存使用降低了近1/3。
2)减少缓存buffer
缓存buffer相比竞品设置的有些大,考虑到下载模块也有一块不小的buffer,所以内核的buffer可以裁剪,平衡卡顿数据,可将buffer设置在较低的水位。
3)减少pipe管线内存使用
pipe管线内存加上内核二级缓存使用量达到3.5M,source重构后去除了二级缓存,加上对pipe buffer pool的优化,这部分内存可减小到0.5M。
4)优化部分数据结构
比如存放信息的AMessage结构,每一个AMessage会消耗4k bytes。针对hls智能档的场景,每一条记录都会创建一个AMessage,所以的记录加起来会超过6MB,这还不包括其他使用AMessage的地方。所以我们重写一个功能类似的结构体进行替换,接口上与AMessage保持一致,减少了内部不必要的内存开消。
优化后,播放内核峰值内存已经降到原来的1/3,大大减少了单个实例使用的内存数。
▐ 功耗优化
功耗的主要影响因素有:cpu占用率、网络请求时长、屏幕及audio等设备的耗电。屏幕亮度音量等这些因素是固定的,所以降低功耗主要从cpu占用率和网络请求时长这两个方面去考虑。
1)减少不必要的流程,裁剪多余线程
这部分在线程裁剪中已经完成,这里不再详述。
2)控制网络请求时长,避免过长的网络连接
移动设备在请求网络的时候,网络设备wifi/4G会及时通电,这部分耗电很大。所以大块的读取一段数据然后wait要好过频繁小段的请求数据。考虑卡顿等其他因素,内核默认设置在缓存消耗到低于2/3之后才重新启动下载。
3)替换数据存储结构,去除冗余存取逻辑
排查发现,每次数据写入buffer,cpu都会异常的繁忙,这与预期不符。review代码找到异常点:我们存储数据用的是vector数据结构,每次来数据都是push到front,当vector的size达到数万的量级之后,这个push_front的操作会非常的消耗cpu。修改的办法是将vector改成list,数据写入到tail,从header读取,该问题不再复现。
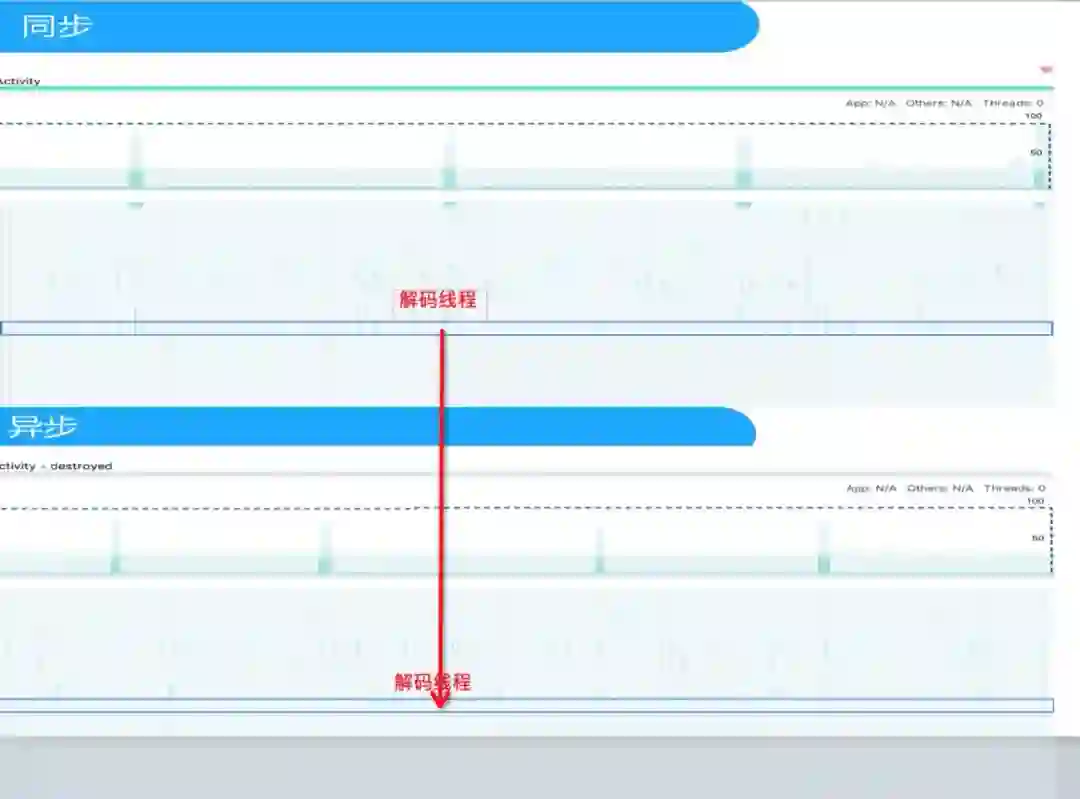
4)omx同步调用改成异步,减少解码cpu耗时
android平台上,硬解omx模块默认用的是同步调用模式。android9.0以下native层只提供了这种模式,会循环的进行queue/dequeue操作,cpu消耗较大。android9.0及以上,native层提供了omx的异步调用模式,会只在queue/dequeue完毕之后callback调用解码模块干活,所以cpu消耗比同步要小。如下图所示,异步比同步要明显稀疏一些。
5)减少倍速算法冗余计算
review发现audioconsumer线程cpu消耗比audio decoder多很多,不符合预期,检查发现当没有开启倍速情况下,也会走倍速相关的运算逻辑,导致cpu异常消耗,修复前后对比如下图:
6)内核层实现弹幕逻辑
弹幕的实现原先是应用层通过view来实现,在弹幕数据多的情况下,非常影响功耗,甚至会出现弹幕模糊的情况。所以考虑将弹幕的实现移到内核层,由内核接收弹幕数据实现render。经过验证,优化后弹幕的功耗降低了2/3.
优化后,播放运行时平均cpu占用率已经低于7%(android中端机测试),1080p/90分钟的视频耗电量降到12%,相比优化前有了30%的提升。


小结
至此,播放内核相比优化前已经大大的“瘦身”了。瘦身后内核的代码逻辑变得更加的清晰,数据传递也更加简洁高效,这让参与内核开发的同学可以更多的关注到自己的业务本身。内存使用量大幅降低,只从内存的角度讲,优化前两个实例的内核,现在可以创建6个,极大的拓宽了上层业务逻辑的边界。功耗也变得更低,大大提升了用户的播放体验。
需要注意的是:我们的业务复杂多变,参与开发的团队也有很多,版本迭代一段时间之后,难免会让内核变得越来越臃肿。所以我们需要对每个正式的版本进行内存、功耗等多个纬度的监测,发现问题立即修改,这样便不会将这些问题积累下去。内核也要定期进行小规模的重构,去除不合理的代码,统一通用的逻辑处理单元,这样才能让高质量的内核持续保持下去。
☞美团十年,支撑全球最大规模外卖配送的一站式机器学习平台是如何炼成的?
☞腾讯提结合ACNet进行细粒度分类,效果达到最新SOTA | CVPR 2020
☞返鄂复工人员自述:回武汉上班,要先飞合肥,再由公司包车接回去