为新研究准备好一块用武之地:最全任务型对话数据调研

合适的数据集或者语料是优秀的自然语言研究工作的基础,然而找寻合适的数据集通常是一件耗时耗力的工作。这时候一份优质的数据集汇总就能帮助科研人员,在研究开始的时候事半功倍。这篇文章就向你介绍一份优质的数据集汇总,帮助你的研究工作轻松选择一片合适的用武之地。
作者丨侯宇泰
学校丨哈尔滨工业大学博士生
研究方向丨任务型对话系统
本文主要介绍本人收集整理的一个任务型对话数据集大全。
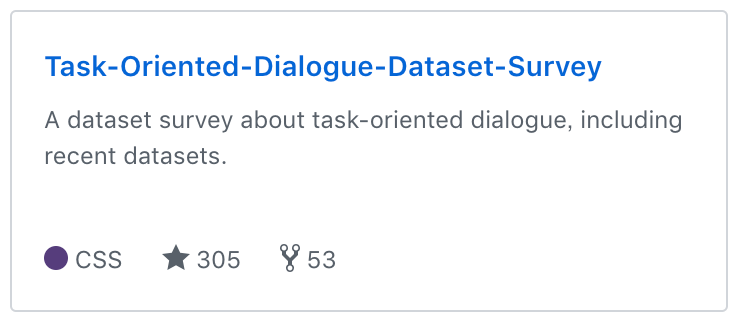
▲ 图1. 数据集汇总项目
这份数据集大全涵盖了到目前在任务型对话领域的所有常用数据集的主要信息。此外,为了帮助研究者更好的把握领域进展的脉络,我们以 Leaderboard 的形式给出了几个数据集上的 State-of-the-art 实验结果。
数据集的地址如下:
https://github.com/AtmaHou/Task-Oriented-Dialogue-Dataset-Survey
背景介绍:什么是任务型对话
我们收集的数据集主要针对任务型对话研究(Task-oriented Dialogue)。
任务型对话系统指在特定的情境下帮助用户完成特定任务的对话服务系统,例如帮助用户订餐、订酒店的对话系统。近年来,随着亚马逊 Alex,微软小娜,苹果 Siri 等个人语音助理业务的兴起,基于对话的人机交互方式得到了广泛的关注,相关的研究也越来越多,俨然成为一个富有潜力的研究方向。
▲ 图2. 语音助手
目前任务型对话的研究可以大体分为两类:基于流程的任务型对话(Pipeline)以及端到端的任务型对话(End-to-End)。
基于流程的任务型对话是相对较为传统的方法。这种任务型对话的系统通过一套 Pipeline 流程实现。如图 3 所示, 任务型对话系统的流程依次包括:自然语言理解、对话状态跟踪、对话策略学习,自然语言生成模块。
具体的,用户输入自然语言,对话系统按流程依次完成:分析用户意图,更新对话状态,根据对话策略做出动作,生成最终的自然语言回复。
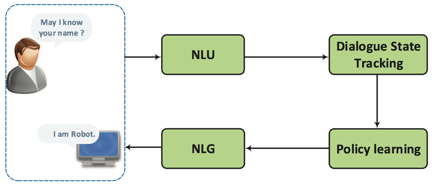
▲ 图3. Pipeline任务型对话
然而,Pipeline 流程式的对话系统存在错误级联和标注开销大的问题,为此最近有一部分研究尝试通过直接进行端到端的任务型对话学习来规避这些问题。端到端式对话系统根据用户输入句子直接给出自然语言回复。
为什么要做数据集汇总?
任务型对话任务并不是新课题,但是针对任务型对话的广泛研究在最近几年才兴起。任务型对话研究的方兴未艾反映在数据和语料上,就是目前现有的任务型对话数据集数量少,且其他成熟的任务已有的数据集在数据量上要少的多。
在这种情况下,尽可能多找到并有效的利用已有的数据资源就成为开展研究的关键之一。然而,搜罗并全面的寻找合适的数据集是一个费时费力的工作,所以整理统计目前已有的任务型对话领域的数据集的信息是有必要的,可以极大地为相关研究工作提供便利,让研究工作得以地快速开始。
除了数据本身的信息有价值之外,在重要数据集上的实验结果提升过程,可以很大程度上反映自然语言研究的前进脉络。所以,简单的数据集信息罗列并不能让我们满意,我们还计划提供一些常用数据上的实验结果和对应论文的信息。从而帮助研究人员了解和把握任务型对话领域研究的推进脉络。我们选择以 Leaderboard 的形式呈现数据集上的部分实验结果。
数据汇总的内容介绍
1. 数据集信息
针对每个数据集,我们统计并总结了如下几个方面的内容。
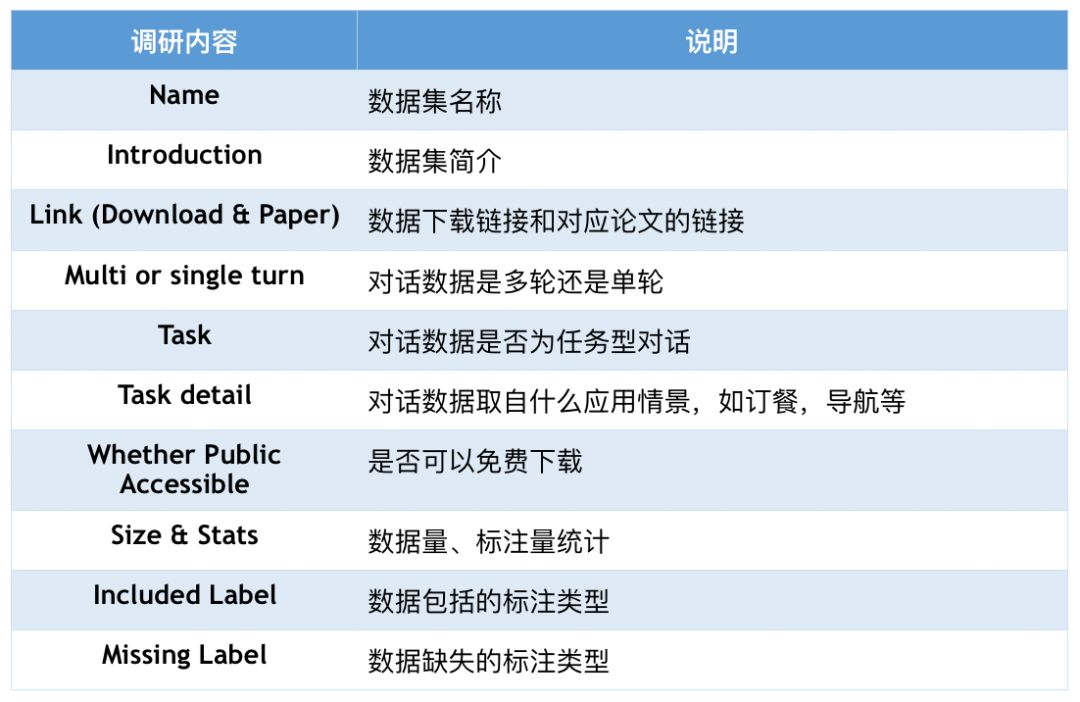
▲ 表1. 数据集内容及说明
类似其他常见数据集汇总工作,我们为每个数据集提供了名称,下载链接,简介,数据量等信息。除了这些基本信息,我们还涵盖了一些任务型对话数据的特有的研究内容,例如:
Multi or single turn:对话数据是多轮还是单轮是任务型对话数据的重要属性,单轮对话数据往往用于自然语言理解任务,多轮对话数据往往用于端到端任务、对话策略学习、对话状态跟踪。
Task detail:数据适用于什么应用情景也是一个独特的关键信息,通过这个信息,研究者可以快速理解数据,开展 Multi-domain 或 Domain-transfer 研究。
2. 实验结果Leaderboard
对于一些研究常用数据,我们提供了上面的一些 State-of-the-art 实验结果,并以 Leaderboard 的形式呈现,具体包括内容如下:

▲ 表2. Leaderboard内容及说明
其中我们的模型名称采用出处论文中的表述,分数的评价指标以具体的任务而定。实验结果列表配合上论文链接,可以让读者快速地了解一个任务。
此项信息内容仍在完善中。
数据集汇总内容样例
1. 数据集介绍样例
数据集的汇总目前以表格的形式,收录了 17 个数据的细节信息。读者可以在 Github 项目中 Excel 文件或者 Readme 中直接查看。数据的格式如图 4 所示。

▲ 图4. 数据细节样例
2. Leaderboard 样例
我们以 Leaderboard 的形式展示了语义槽抽取(Slot filling),用户意图识别(Intent detection),对话状态跟踪(Dialogue state tracking)三个任务上的一些领先结果。具体形式如图 5 所示。
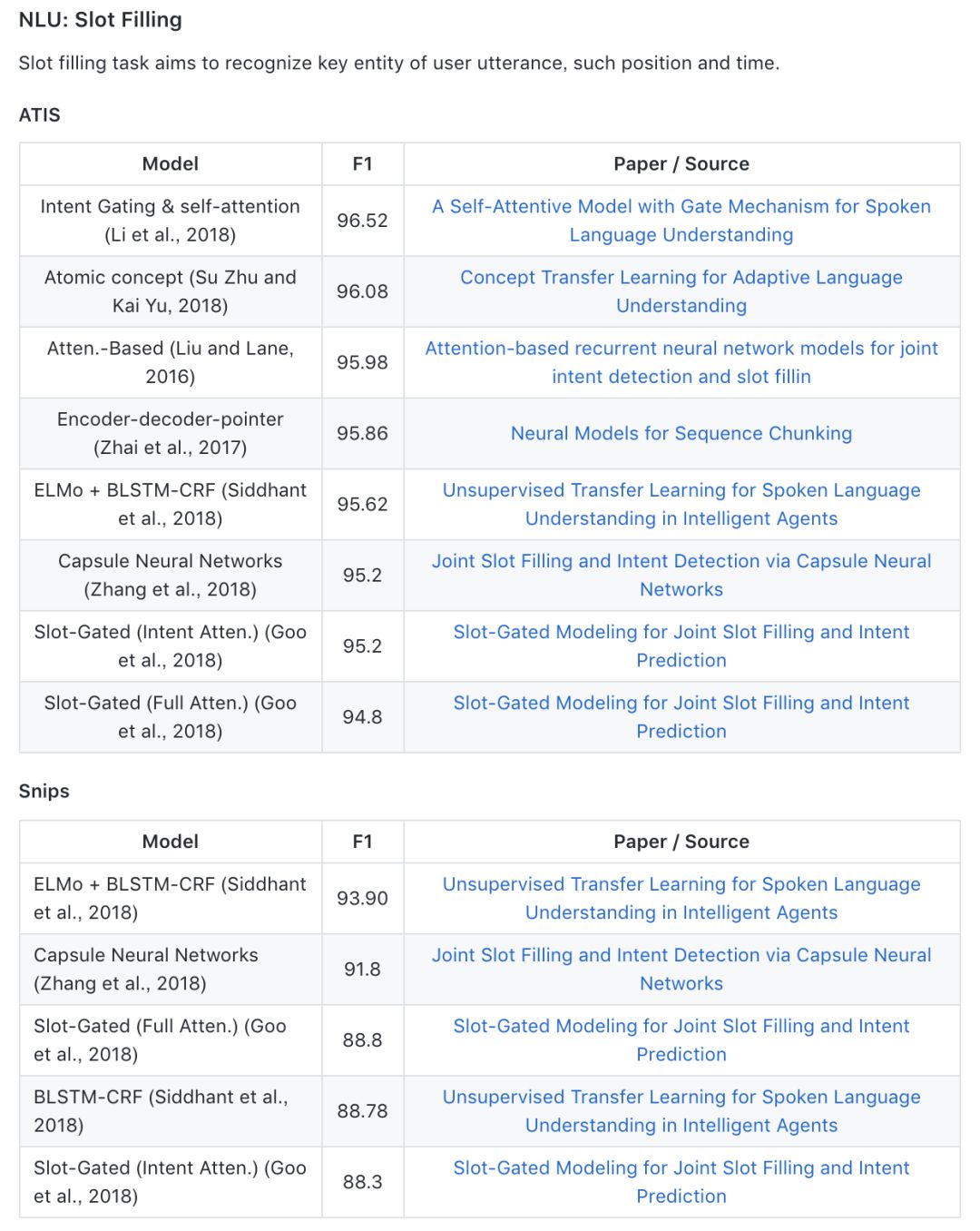
▲ 图5. Leaderboard的样例
关于内容补充的邀请
我们欢迎各种形式的内容完善,包括但不限于:
直接提交 Pull Request
向我们发送新数据
向我们发送新的实验结果(已发表论文)

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 获取最新论文推荐


