【CVPR2020-斯坦福】知识蒸馏时空图的视频描述,Spatio-Temporal Graph

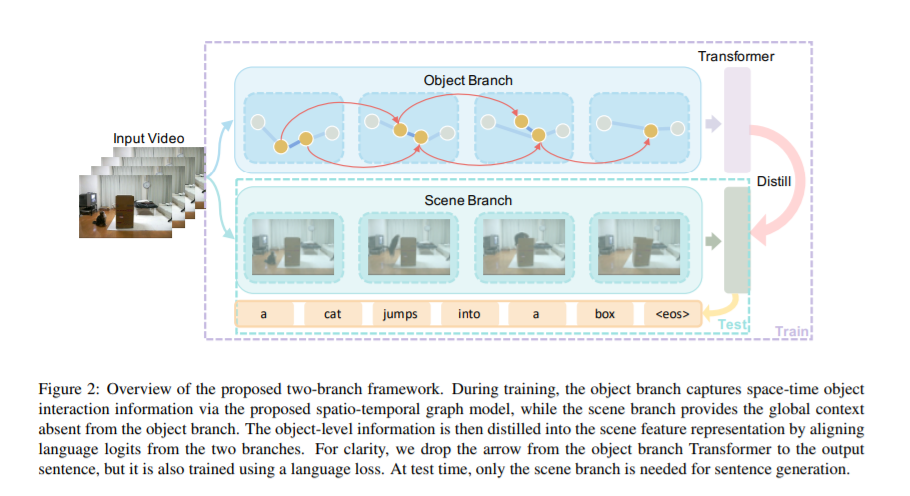
视频描述是一项具有挑战性的任务,需要对视觉场景有深刻的理解。最先进的方法使用场景级或对象级信息生成标题,但不显式地建模对象交互。因此,他们往往无法做出有视觉根据的预测,而且对虚假的相关性很敏感。本文提出了一种新的视频描述时空图模型,该模型利用了时空中物体间的相互作用。我们的模型建立了可解释的链接,并能够提供明确的视觉基础。为了避免由于对象数量的变化而导致系统性能的不稳定,提出了一种基于局部对象信息的全局场景特征正则化的对象感知知识提取机制。我们通过在两个基准上的大量实验来证明我们的方法的有效性,表明我们的方法具有可解释预测的竞争性能。
https://www.zhuanzhi.ai/paper/4729866d34c784d60bdad8d04f3dc6b2
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“STG” 就可以获取《【CVPR2020-斯坦福】知识蒸馏时空图的视频描述,Spatio-Temporal Graph》专知下载链接



登录查看更多
相关内容
专知会员服务
42+阅读 · 2020年6月29日
专知会员服务
77+阅读 · 2020年2月25日
Arxiv
9+阅读 · 2019年5月27日
Arxiv
8+阅读 · 2019年5月20日
Arxiv
5+阅读 · 2018年12月6日



相关VIP内容
专知会员服务
42+阅读 · 2020年6月29日
专知会员服务
77+阅读 · 2020年2月25日
相关资讯
相关论文
Arxiv
9+阅读 · 2019年5月27日
Arxiv
8+阅读 · 2019年5月20日
Arxiv
5+阅读 · 2018年12月6日