【斯坦福李飞飞等人Nature论文】基于深度学习检测ICU中的患者移动
【导读】近日,斯坦福李飞飞团队在Nature Digital Medicine发表新论文,意图使用深度学习来检测ICU病房中患者的移动。
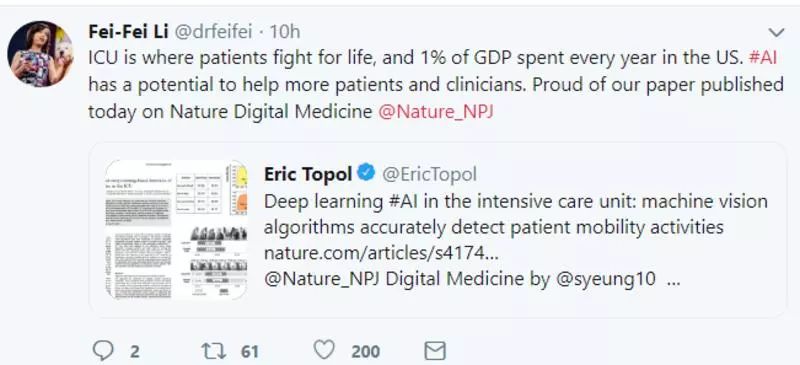
早期和频繁的患者移动大大降低了重症监护后综合症和长期功能障碍的风险。作者开发并测试了计算机视觉算法,以检测成人ICU中发生的患者移动。移动活动被定义为将患者移入和移出床,以及将患者移入和移出椅子。作者在Intermountain LDS医院ICU收集了隐私安全深度视频图像数据集,包括563个移动活动实例和来自7个壁挂式深度传感器的98,801个总帧视频数据。总之,67%的移动实例用于训练算法以检测移动活动的发生和持续时间,以及每个活动中涉及的医护人员的数量。其余33%的移动性实例用于算法评估。检测到移动活动的算法在四种活动中的平均特异性为89.2%,灵敏度为87.2%;量化人员数量的算法达到平均准确率68.8%。

【介绍】
长期高强度护理的幸存者经常患有重症监护后综合症,其特征是长期认知和身体损伤导致功能状态显著下降.重症患者的动员可以防止肌肉萎缩和功能障碍(ICU获得性无力).这很重要,因为这些是可预防的危害,影响整体生存,独立进行日常生活活动的能力。虽然早期研究表明特定患者群体的移动干预对他们有益,但需要进行更多详细的研究,以确定类型,频率和类型的变化,以及健康相关的生活质量。移动的持续时间会影响不同患者群体的结果。遗憾的是,此类研究的范围目前有限,因为早期移动的实施需要克服重大的组织和文化障碍,并且历史上很难衡量成功。
目前监测患者移动的做法包括直接人类观察和挖掘电子健康记录(EHR)。这些方法耗费时间和劳动力,容易出现不准确的文件记录。计算机视觉技术(CVT)通过捕获临床环境中的数据提供了一种替代方法,应用机器学习算法自动检测和量化患者和员工活动。事实上,人们越来越关注使用CVT进行活动:例如,计算机视觉算法已被开发用于自动识别医院走廊中的手部卫生事件和急诊部门的创伤复苏事件。CVT也已应用于手术室算法识别患者护理任务(例如将患者移动到手术台上),外科手术中的步骤和工具,甚至外科医生的手术技能水平。
【实验结果】
用于检测移动性活动的算法性能
在评估视频数据的各个层次的预测时,用于检测移动性活动发生的算法分别在所有四个活动中实现了87.2%和89.2%的平均灵敏度和特异性以及0.938ROC(帧级预测)。每个活动和接收机操作特性曲线如图1所示。帧级预测被合并以确定算法检测到的移动活动的持续时间。算法预测的所有移动活动的平均持续时间为7.6秒(标准差12.6秒,最小0.4秒,最大146.5秒,对于个体移动活动的持续时间)。为进行比较,所有活动的平均持续时间基于手动审查的注释数据(真实情况)为9.0 s(标准差12.9 s,最小0.5 s,最大123.9 s)。算法正确对活动进行了正确的分类,也对持续时间进行正确的预测,58.1%的活动在标准差+-15%; 68.7%的活动在+/- 25之内; 82.0%的活动在+/- 50%之内。
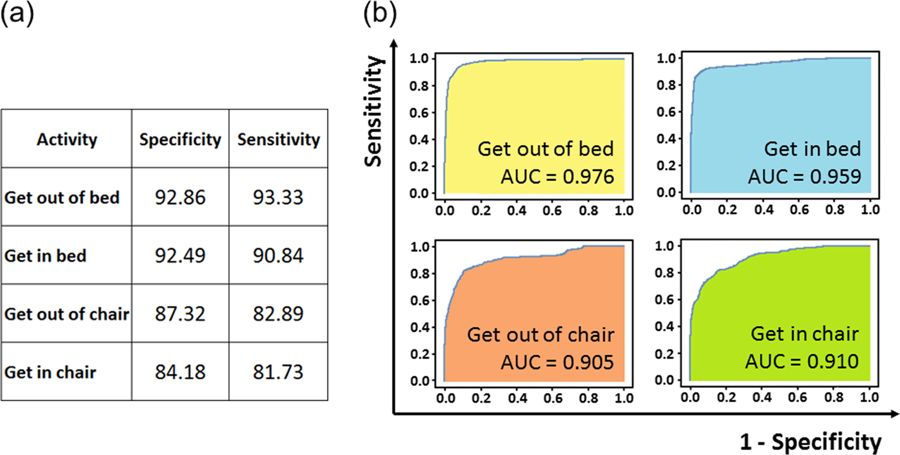
用于检测医护人员的算法性能
用于量化每项活动中涉及的医护人员数量的算法实现了68.8%的平均准确度。 在移动活动期间分配真实与预测人员的混淆矩阵如图2所示。混淆矩阵表明,当患者运动时,算法在75%的时间内正确地检测到这一点(0名预测人员); 当存在单个医护人员时,该算法在74%的时间内正确地检测到这个(1个预测人员)。 2名和3名医护人员的检测准确率分别为62%和60%。 该算法在78%的时间内正确检测到2个或更多预测人员(而不是0或1)。
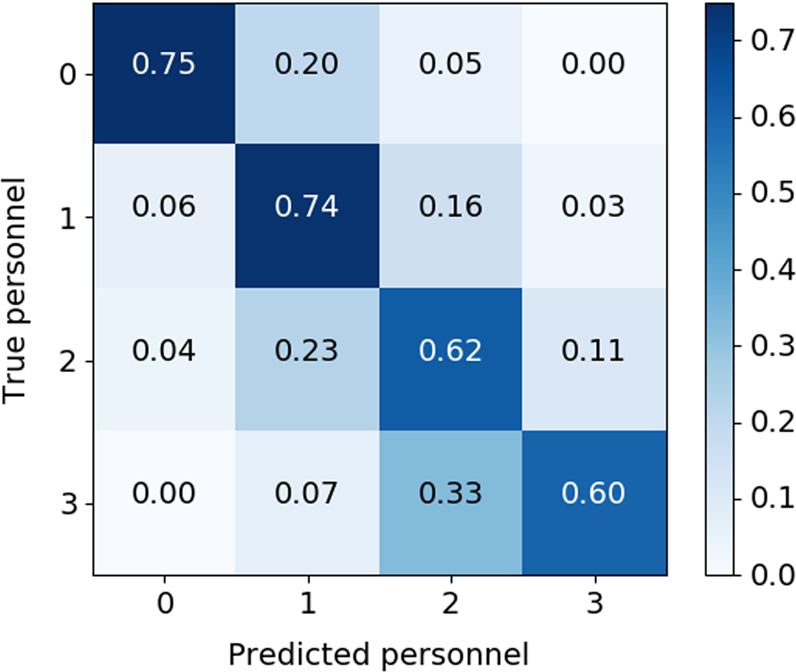
下图展示了算法输出的定性示例。图中显示了两个(压缩)时段的采样深度图像帧。此外,下图中的时间线还显示了检测到的活动类型、发生时间、持续时长,以及涉及的医护人员数量。为方便对比,下图还显示了真值数据。
请关注专知公众号(点击上方蓝色专知关注)
后台回复“ICU” 就可以获取李飞飞等Nature论文的下载链接~
原文链接:
https://www.nature.com/articles/s41746-019-0087-z#data-availability
END-
专 · 知
专知《深度学习:算法到实战》课程全部完成!490+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询《深度学习:算法到实战》课程,咨询技术商务合作~

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程





