Flink 提供了灵活丰富的状态管理,可轻松解决数据之间的关联性。本文介绍了Flink 状态(State)管理在推荐场景中的应用,大家结合自己的应用场景与业务逻辑,选择合适的状态管理。
本文作者:代松辰 内容来源:58技术公众号
Flink作为纯流式大数据实时计算引擎,较于Spark Streaming的微批处理引擎,不管是内存管理,多流合并,还是时间窗口,迭代处理上,Flink在实时计算场景更较适合。而Flink的State状态管理,更是让Flink在实时计算领域,更胜一筹。通过对Flink State状态的灵活妙用,可以完美实现大数据下的实时数仓,实时画像和实时数据监控等功能。
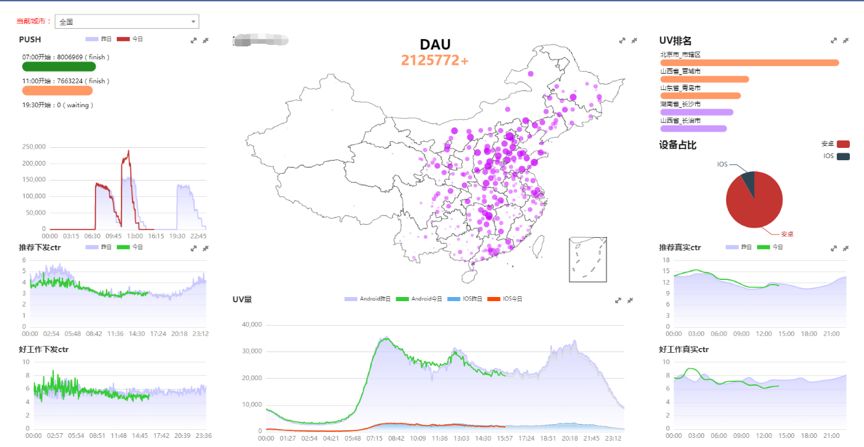
最近在做推荐数据平台,其中有一个场景需求是要实时统计最近1分钟的UV、点击量、真实曝光量和下发量等热点数据,并可以在不同地域维度下做多维度查询。
通过对数据的实时跟踪监控,可以精准迅速地获悉推荐算法在不同地域投放后所产生的流量变化,从而优化对不同地域下用户的精准推荐。
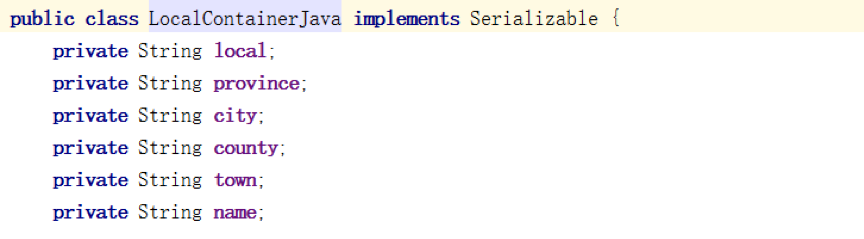
首先是我们的数据来自于用户对App的操作行为日志,在这些埋点数据里,有个字段localId(13位数字组成),该字段记录了该用户所在的位置编号,可以精确到区,街道,甚至村委会,但是缺少上下层级关系。也就是说,通过localId我们无法得知该用户属于哪个镇,哪个市,哪个省等。所以,在对该数据做进一步操作前,需要找到localId的地域映射关系,并关联到省市县等,从而实现省市县下不同维度下的热点数据统计与分析。
另外就是对于埋点上报的真实曝光数据,存在较严重的数据延迟问题,甚至可达到数个小时的延迟,严重影响数据的准确性和时效性。这部分的原因是真实曝光的定义与App客户端的埋点上报机制所致。
首先想到使用Spark做数据处理引擎,不管从公司使用的人数和任务数上,还有维护上,使用Spark无疑是最稳定的选择。但是Spark是基于RDD做的micro batch处理,而Spark Streaming又只是在Spark RDD基础上增加了时间维度(时间片),其本质还是在进行Spark的RDD处理。Spark Streaming将流式计算分解成了多个Spark Job,而每一段数据的处理都会经过RDD DAG有向无环图的分解,和Spark Scheduler的调度分配,其最小的Batch Size为0.5秒~2秒钟之间。所以,Spark Streaming适用于对实时性要求不是非常高的流式准实时计算场景。而我们的数据有一部分是实时上报上来,例如点击与下发数据。我们希望对这些数据做秒级内处理,所以在处理这种延时性较低的数据上,Spark Streaming可能不是很适合。并且,一天不同时间段访问UV量参差不齐,导致一天内不同时间段的流量峰值或高或低,而且节假日期间的流量更是不可预测。Spark Streaming从v1.5才开始引进反压机制(back-pressure),而且也只是估计当前系统处理数据的速率,再调节系统接收数据的速率与之匹配,无法实现动态反压。而Spark在流式计算上的缺陷,正是Flink的优势。与Spark基于RDD计算不同,Flink是基于有状态流的计算,并提供了更丰富灵活的状态用以保存状态数据,我们就用到了Flink Stream的Broadcast State解决了localId的地域映射关系。并且Flink对数据流也是逐条处理,在低延时上明显优于Spark Streaming。Flink在1.5之后,采用Credit-based的网络流控制机制,对运行时的Task有着天然流控,慢的数据sink节点会反压快的数据源source。系统能接收数据的前提是接收数据的Task必须有空闲可用的Buffer,而数据被继续处理的前提是下游Task也有空闲可用的Buffer,只有下游的Task有了空闲的Buffer,才能消费上游Task的Buffer。所以,Flink的反压,是系统接收数据的速率和处理数据速率的自然匹配。
其次,我们在专门基于流处理框架Storm和Flink中做了比较,虽然Storm在延迟处理上优于Flink,但从吞吐量,资源动态调整,SQL支持,状态管理,容错机制和社区活跃度等来看,Flink都明显优于Storm。特别是Storm没有任何对状态的支持,需要依赖其他组件实现状态管理。最重要的,Flink在公司内部有专门的WStream平台,并由专业的团队维护。
所以,我们选择了Flink做数据流处理框架,而基于真实曝光数据上报延迟较严重问题,我们选择Druid这种时序性的数据库作为数据存储,在保证数据不丢失的前提下,还能做到数据的近实时聚合查询。
Spark有广播变量,把地域映射表数据直接Broadcast共享到到各个Worker Node的内存中,接下来的Operator操作都可以基于各自所在Worker节点已拷贝到内存中仅一份的地域映射表数据进行操作。Flink Datastreaming也有类似Spark的Broadcast广播变量,都实现了节约内存和共享变量的作用。但其机制原理与使用方法与Spark 广播变量截然不同。Flink Streaming的Broadcast作为Flink State的一种,类似Hadoop的分布式缓存,Flink会复制文件或者目录到所有Worker Node的本地文件系统,让并行运行实例的函数可以本地访问。为保证每个节点获取到的Broadcast State一致,Worker Node中的Broadcast State并不会相互传播通信,也不会被修改,且同一个Worker Node的所有Task可以共享广播状态。这个功能被常用来缓存不大且不可变的静态数据,例如地域映射表或者机器学习的逻辑回归模型等。而在使用方法上,Flink DataStreaming需要定义StateDescriptor来广播状态到各个Worker Node。而每个Task在处理数据时,通过StateDescriptor就可以获取缓存在本Worker Node的广播状态,相对Spark 广播变量API的使用较复杂一些。
不仅有Broadcast State,根据数据集是否按照Key分区,Flink可以将状态分为Keyed State和Operator State(No-Keyed State)两种类型,而这两种状态类型又均具有两种形式,分别是托管状态(Managed State)和原生状态(Raw State)。区别在于托管状态(Managed State)是由Flink Runtime控制和管理的状态数据,并将状态数据转化存储在Java Heap内存的Hash Table或RocksDB,然后将这些状态数据通过内部的CheckpointedFunction接口持久化到Checkpoints中,而状态的一致性,其实也是通过Checkpoints实现。因为有第三方RocksDB数据库的参与,可以把State数据暂存RocksDB数据库中,相比存于Java Heap中更安全。如果开启Checkpoint增量机制,新产生的数据会替换之前产生的文件COPY到持久化中,以此减少COPY的数据量,并提高性能,更适合在生产环境使用。但目前为止,RocksDB还不支持Broadcast State。
当任务出现异常退出时,也可以通过这些状态数据进行恢复,读取已经Checkpoints的状态数据,可以还原任务失败前的状态,包括记录已经消费过的Kafka偏移量,以此实现容错机制。当任务从状态数据恢复时,可以继续从未消费的Kafka偏移量开始读取数据,从而实现Flink Source端Exactly-Once语义。
原生状态(Raw State)由算子自己管理数据结构,当触发Checkpoint过程时,只是将数据转化成字节码数据存在Checkpoints中,当从Checkpoints恢复任务时,算子再自己反序列化出状态的数据结构,常用于自定义算子操作中。虽然两者都可以实现状态的管理和存储,但托管状态可以更好地支持状态数据的重平衡以及更加完善的内存管理,经常被使用。
托管状态(Managed State)已经有了官方实现好的几种状态,可以根据实际场景与业务逻辑选择使用,例如BroadcastState<K,V>,ValueState[T],ListState[T],ReducingState[T],AggregatingState[IN,OUT],MapState[UK,UV],而所有的托管状态都需要通过创建StateDescriptor来获取响应的State的操作类,该描述符主要定义了状态的名称,状态中的数据类型参数信息以及状态自定义函数,方便Flink的序列化与反序列化。每种托管状态都有对应的描述符,例如ValueStateDescriptor,ListStateDescriptor,ReducingStateDescriptor,FoldingStateDescriptor,MapStateDescriptor等。而且通过对Flink State设置TTL,自定义超时清理时间,在状态量越来越大的情形,可对内存做着优化处理的同时,还不会影响性能。
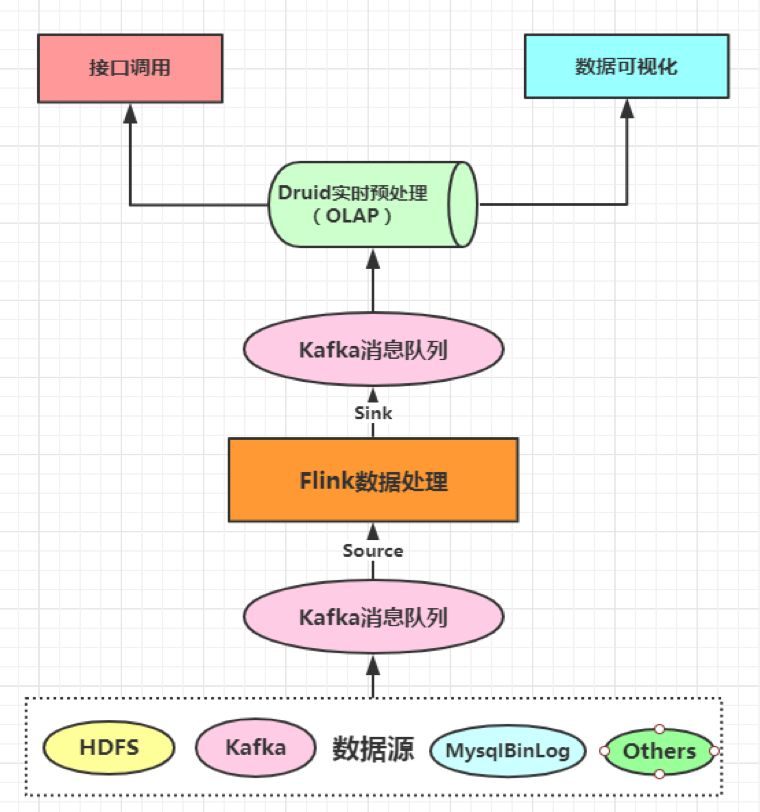
我们的数据处理是基于Lambda架构搭建,数据暂存于Kafka消息队列,分流供离线与实时做不同处理。
Flink在处理数据流程上层次分明,Source(数据源)->Channel(数据处理)->Sink(数据存储)。
首先,Flink Source端接入已经存入Kafka消息队列的数据,这里面的数据可以是经过ETL处理后的JSON格式数据。
其次,使用Flink对接入的数据做operator操作,并将处理结果Sink暂存到另一个Kafka消息队列,供Druid做Pull拉取操作。
最后,基于Druid做数据可视化操作或供其他接口调用。
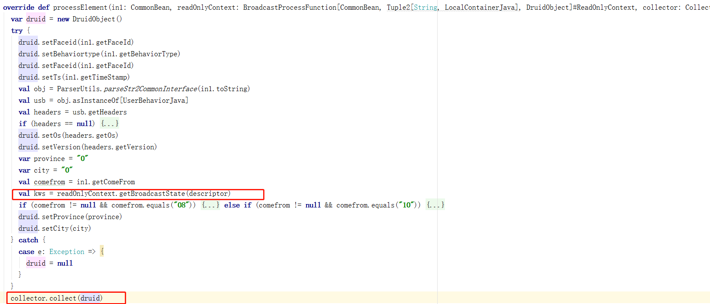
首先,读取存于HDFS的地域表数据,并把表数据转换成自定义LocalContainerJava对象流。
其次,定义MapStateDescriptor描述符,并把转换的表数据对象流广播出去,描述符必须和表数据对象流格式相对应。
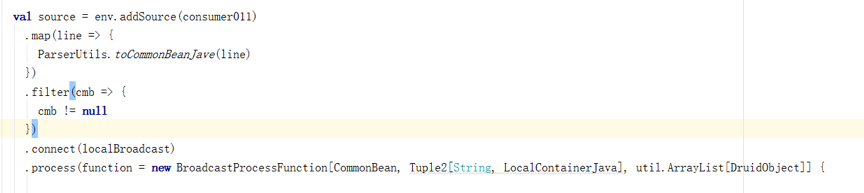
然后,使用connect将BroadcastStream 与Kafka传来的数据流合并,因为这两种流数据类型不同,所以使用connect多流合并,返回BroadcastConnectedStream。Flink的多流合并还有union和join等,union要求连接的流数据类型必须一致,join则要求每个流必须有key且key值相同才能完成关联操作。之后调用Process方法分别对各流做具体逻辑操作。因为我们的场景并不需要对数据集做Key分区,所以在Process方法里传入抽象类BroadcastProcessFunction的参数实现。
在抽象类BroadcastProcessFunction里,这里必须重写两个方法,一个是processBroadcastElement,一个是processElement,前者用以处理广播流,后者用以直接处理从Kafka读取的数据流,当然也可以重写 open和close方法,做一些初始化与收尾操作,具体根据自己的应用场景的需要来决定。
在processBroadcastElement方法,通过上下文Context传入之前定义Broadcast State的描述符,获取到BroadcastState操作类,并对BroadcastState做put键值对操作。这里的put操作并不会影响其他TaskManager节点的Broadcast State数据,只会作用于当前节点。这点类似定义本地全局HashMap,只是这里TaskManager把这些状态数据转换成内存Hash Table存储,并Checkpoint到JobManager,最后JobManager根据配置信息setStateBackend存储Checkpoints数据。这里,Flink RunTime帮我们做了内部具体实现,让我们可以只关注具体业务逻辑,而不必考虑数据在节点间的传输和序列化等问题。
而processElement方法,可以对MapState进行各种操作。类似HashMap接口,MapState可以通过entries(),keys(),values()获取对应的keys或values的集合。然后把结果集collect到下游算子。
最后,把结果数据集做Sink处理。这里可以把Flink做完的聚合统计结果,直接存入第三方存储里(例如Kafka,Redis甚至Mysql等),只要把Sink定义成相应的connector即可。
这里,我们没有使用Flink做聚合操作的原因,从Kafka传来的部分数据,不可避免出现延迟时间问题,甚至有些数据延迟达数个小时以上。Flink可以解决乱序问题,但是对于延时过长的数据,借助其他大数据组件是更好的选择。同时也是因为部分数据数据延时过长的原因,我们使用Flink默认的ProcessTime,以Flink处理时间为准。因为不需要Flink做聚合操作,所以也就没有自定义Window。
最后把数据传入第三方大数据组件Druid,我们在Druid里做聚合查询操作。而Druid使用的是数据的EventTime,通过把数据存入Druid时序数据库的不同时间Segment,就解决了数据延迟时间参差不齐的问题,实时性和性能都有提高。随着时间的推移,迟到数据陆续存入不同时间的Segment,准确度越来越高,迟到的数据会不断更新最后的结果,解决埋点数据上报的延迟问题。
无论是在实时还是离线场景,数据之间难免会有关联。Flink 提供了灵活丰富的状态管理,可轻松解决数据之间的关联性。结合自己的应用场景与业务逻辑,选择合适的状态管理。
Flink虽然可以处理大多数实时计算场景,但对某些特殊场景,可能并不是特别适合,或者处理起来较复杂。如果可以参考其他大数据组件,与Flink相互结合使用,无论从代码开发,还是预期效果上,可能会事半功倍。
Apache Flink官方文档:https://ci.apache.org/projects/flink/flink-docs-release-1.6/dev/stream/state/state.html
代松辰,高级大数据开发工程师,现就职于58同镇算法技术部。
如果您喜欢本文,欢迎点击右上角,把文章分享到朋友圈~~
欢迎加入DataFunTalk大数据交流群,跟同行零距离交流。如想进群,请加逃课儿同学的微信 ( 微信号:DataFunTalker ),回复:大数据,逃课儿会自动拉你进群。
——END——
DataFunTalk专注于大数据、人工智能技术应用的分享与交流。发起于2017.12,至今已在全国7个数据智能企业和人才聚集的城市 ( 北京、上海、深圳、杭州等 ) 举办超过100场线下技术分享和数场千人规模的行业论坛及峰会,邀请300余位工业界专家和50位知名学者参与分享,30000+从业者参与线下交流。合作企业包括BATTMDJ等知名互联网公司和数据智能方向的独角兽公司,旗下DataFunTalk公众号共生产原创文章300+,百万+阅读,5万+精准粉丝。
注:左侧关注"社区小助手"加入各种技术交流群,右侧关注"DataFunTalk"公众号最新干货文章不错过👇👇
![]()