生成对抗网络也需要注意力机制
选自KDnuggets
作者:Bilal Shahid
机器之心编译
参与:Nurhachu Null、张倩
传统的深度卷积生成对抗网络无法捕获到图像中的长距离依赖。当图像中存在较高的信息变化率时,卷积生成对抗网络通常会错过所有的这种变化,因此不能真实地表征全局关系。自注意力生成对抗网络(Self-Attention Generative Adversarial Networks)使用自注意力范式来捕获图像中存在的长距离空间关系,以更好地合成新的图像。本文梳理了一下这篇文章的概况和它的主要贡献。
原论文地址:https://arxiv.org/pdf/1805.08318.pdf
TDLS 展示地址:https://tdls.a-i.science/events/2018-06-11/
传统生成对抗网络的挑战
尽管传统的生成对抗网络可以生成相当逼真的图像,但是它们无法捕获到图像中的长距离依赖。这些传统的生成对抗网络在不包含太多的结构和几何信息的图像上效果是不错的(例如海洋、天空和田野)。但是,当图像中存在较高的信息变化率时,传统的生成对抗网络往往会错过所有的这种变化,因此就无法真实地表征全局关系。这些非局部依赖始终会出现在某些类别的图像中。例如,生成对抗网络可以生成具有逼真皮毛的动物,但是却无法生成独立的足部。

之前的 SOTA 生成对抗网络生成的图像(CGANs with Projections Discriminator; Miyato et al., 2018)
由于卷积算子表征能力的局限性(也就是接受域是局部的),传统的生成对抗网络在几个卷积层之后才能捕获到长距离关系。缓解这个问题的一种方法就是增加卷积核的尺寸,但是这在统计和计算上都是不够高效的。各种注意力和自注意力模型早已被用来捕获并使用这种结构化模式和非局部关系。但是,这些模型通常不能有效地平衡计算效率和建模长距离关联二者之间的关系。
用于生成对抗网络的自注意力
这个功能性差距就是 Zhang 等人(2018)提出这种方法的原因。他们给生成对抗模型配备了一个工具来捕获图像中的长距离、多级关联。这个工具就是自注意力机制。自注意力机制尝试关联输入特征的不同部分,切合正在进行的任务计算出输入的另一个表征。自注意力机制的思想已经被成功地应用在了阅读理解(Cheng 等 2016)、自然语言推理(Parikh 等,2016)以及视频处理(X. Wang 等, 2017)等领域。
将自注意力引入到图像生成领域受启发于《Non-local neural networks》(非局部神经网络)(X. Wang 等,2017),这项工作使用自注意力来捕获视频序列中的空间-时间信息。通常而言,自注意力机制就是简单地计算某个单独的位置在所有位置的特征加权和中的响应。这个机制允许网络聚焦于那些分散在不同位置但是又有着结构关联的区域。
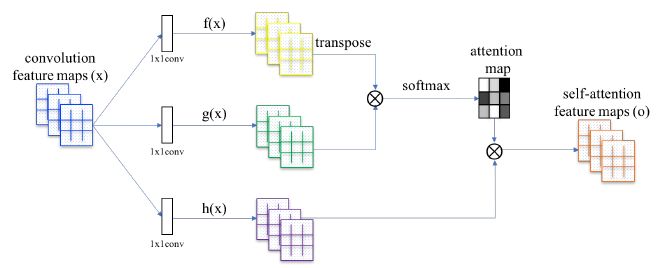
自注意力生成对抗网络(Self-Attention Generative Adversarial Networks,Zhang 等,2018)中所提出的自注意力模块
在 SAGAN 中,注意力模块与卷积神经网络协同工作,并且使用了 key-value-query 模型(Vaswani 等,2017)。这个模块以卷积神经网络创建的特征图为输入,并且将它们转换成了三个特征空间。这些特征空间(分别是 key f(x)、value h(x) 和 query g(x))通过使用三个 1X1 的卷积图来传递原始特征图而生成。然后 Key f(x) 和 query g(x) 矩阵相乘。接下来,相乘结果的每一行应用 softmax 算子。由 softmax 生成的注意力图代表了图像中的哪些区域应该被关注,如方程(1)所示(Zhang 等,2018):
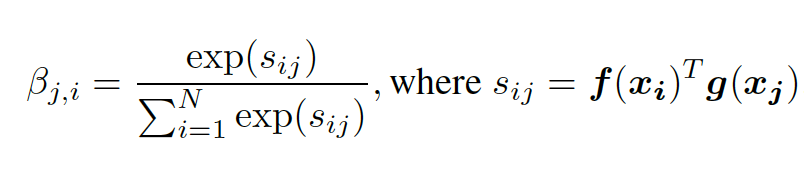
然后,注意力图与 h(x) 的值相乘来生成自注意力特征图,如下所示(Zhang 等,2018):
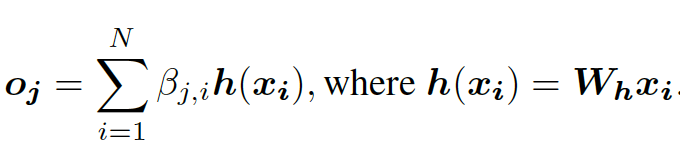
最后,将原始输入特征图和缩放的自注意力图相加来计算输出。缩放参数𝛄在开始的时候被初始化为 0,以让网络在开始的时候首先关注局部信息。当参数γ在训练过程中进行更新时,网络就会逐渐学习注意一幅图像的非局部区域(公式(3),Zhang 等,2018)。
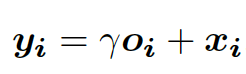

自注意力生成对抗网络的输出图像(Zhang 等,2018)
处理生成对抗网络训练过程中的不稳定性
SAGAN 论文的另一个贡献与著名的 GAN 训练不稳定性相关。论文提出了两种技术来处理这个问题:谱归一化和双时间尺度更新规则(TTUR)。
在良好的条件下,生成器被证明会表现得更好,而且提升了训练的动态性能(Odena 等,2018)。可以使用谱归一化来完成生成器调制。这个方法最早是在 Miyato 等人的《SPECTRAL NORMALIZATION FOR GENERATIVE ADVERSARIAL NETWORKS》中提出的,但仅仅是针对判别器的,目的是解决训练振荡问题,这一问题可能导致生成器无法很好地学习到目标分布。SAGAN 在生成器和判别器网络中都使用了谱标准化,限制了两个网络中的权重矩阵谱归一化。这个过程是有好处的,因为它在不需要任何超参数调节的情况下就限制了李普希茨常数,阻止了参数幅度和异常梯度的增大,而且允许判别器进行较少的更新(与生成器相比)。
除了谱归一化,这篇论文还使用了 TTUR 方法(Heusel 等,2018)来解决常规判别器训练缓慢的问题。使用常规判别器的方法通常在一次生成器更新中需要多次更新判别器。为了加快学习速度,生成器和判别器以不同的学习率进行训练。
结论
SAGAN 是对图像生成的现有技术的实质性改进。自注意力技术的有效集成使得网络能够真实地捕获和关联长距离空间信息,同时保证计算的高效性。在判别器和生成器网络中使用谱归一化和 TTUR 方法不仅降低了训练的计算成本,而且提高了训练稳定性。

原文链接:https://www.kdnuggets.com/2019/03/gans-need-some-attention-too.html
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



