![]()
对手建模作为多智能体博弈对抗的关键技术,是一种典型的智能体认知行为建模方法。介绍 了多智能体博弈对抗几类典型模型、非平稳问题和元博弈相关理论;梳理总结对手建模方法,归纳 了对手建模前沿理论,并对其应用前景及面对的挑战进行分析。基于元博弈理论,构建了一个包括 对手策略识别与生成、对手策略空间重构和对手利用共三个模块的通用对手建模框架。期望为多智 能体博弈对抗对手建模方面的理论与方法研究提供有价值的参考。
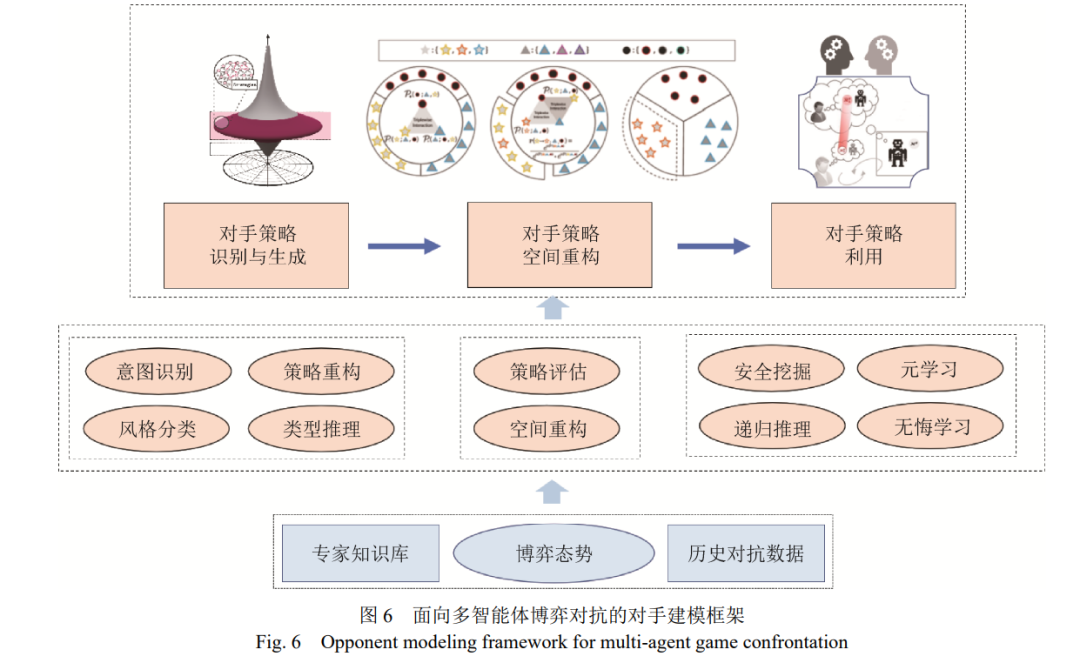
人工智能技术的发展经历了计算智能、感知智 能阶段,云计算、大数据、物联网等技术的发展正 助力认知智能飞跃发展。其中认知智能面向的理 解、推理、思考和决策等主要任务,主要表现为擅 长自主态势理解、理性做出深度慎思决策,是强人 工智能(strong AI)的必备能力,此类瞄准人类智能 水平的技术应用前景广阔,必将影响深远。机器博 弈是人工智能领域的“果蝇” [1],面向机器博弈的智 能方法发展是人工智能由计算智能、感知智能的研 究迈向认知智能的必经之路。多智能博弈对抗环境是一类典型的竞合(竞争 -合作)环境,从博弈理论的视角分析,对手建模主 要是指对除智能体自身以外其它智能体建模,其中 其他智能体可能是合作队友(合作博弈,cooperative game)、敌对敌人(对抗博弈,adversarial game)和自 身的历史版本(元博弈, meta game)。本文关注的对 手建模问题,属于智能体认知行为建模的子课题。研究面向多智能体博弈对抗的对手建模方法,对于提高智能体基于观察判断、态势感知推理,做好规 划决策、行动控制具有重要作用。本文首先介绍多智能体博弈对抗基础理论;其 次对对手建模的主要方法进行分类综述,研究分析 各类方法的区别联系,从多个角度介绍当前对手建 模前沿方法,分析了应用前景及面临的挑战;最后 在元博弈理论的指导下,构建了一个拥有“对手策 略识别与生成、对手策略空间重构、对手策略利用” 共 3 个模块的通用对手建模框架。
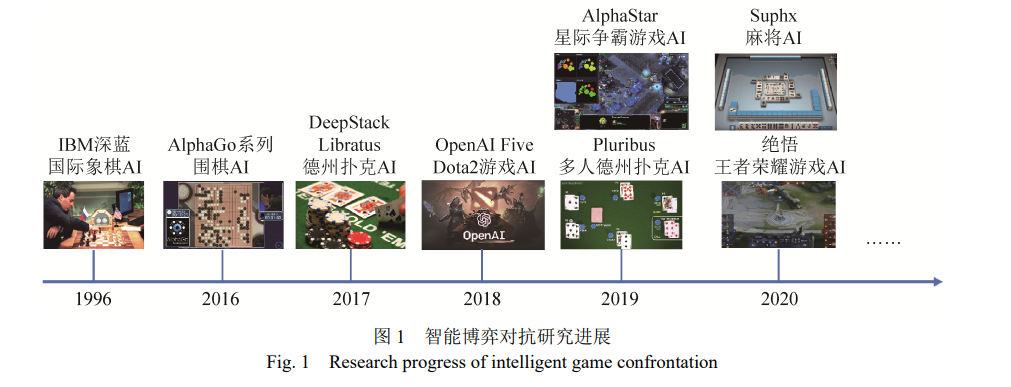
近年来,多智能体博弈对抗的相关研究取得了 很大的突破。如图 1 所示,以 AlphaGo/AlphaZero (围棋 AI)[2]、Pluribus (德州扑克 AI)[3]、AlphaStar (星 际争霸 AI)[4]、Suphx (麻将 AI)[5]等为代表的人工智 能 AI 在人机对抗比赛中已经战胜了人类顶级职业 选手,这类对抗人类的智能博弈对抗学习为认知智 能的研究提供了新的研究范式。多智能体博弈对抗的研究就是使用新的人工 智能范式设计人工智能 AI 并通过人机对抗、机机 对抗和人机协同对抗等方式研究计算机博弈领域 的相关问题,其本质就是通过博弈学习方法探索 人类认知决策智能习得过程,研究人工智能 AI 升级进化并战胜人类智能的内在生成机理和技术 途经,这是类人智能研究走上强人工智能的必由 之路。
![]()
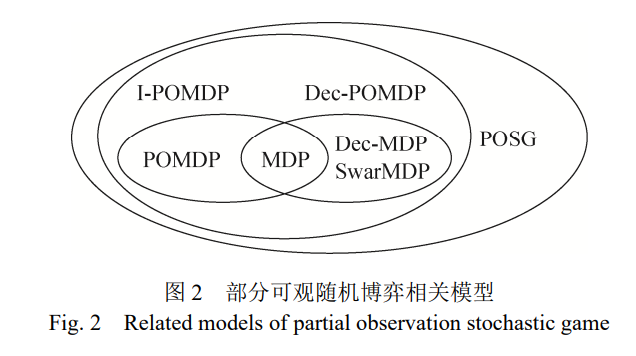
在人工智能领域,马尔可夫决策过程(markov decision process, MDP)常用于单智能体决策过程建 模。近些年,一些新的马尔可夫决策模型相继被提 出,为获得多样性策略和应对稀疏反馈,正则化马 尔可夫决策过程将策略的相关信息或熵作为约束 条件,构建有信息或熵正则化项的马尔可夫决策过 程[6]。相应的,一些新型带熵正则化项的强化学习 方法[7](如时序空间的正则化强化学习,策略空间的 最大熵正则化强化学习与 Taillis 熵正则化强化学 习)和一些新的正则化马尔可夫博弈模型[8](如最大 熵正则化马尔可夫博弈、迁移熵正则化马尔可夫博 弈)也相继被提出。面向多智能体决策的模型主要 有多智能体 MDPs(multi-agent MDPs, MMDPs)及 分布式 MDPs(decentralized MDPs, Dec-MDPs)[9]。其中在 MMDPs 模型中,主要采用集中式的策略, 不区分单个智能体的私有或全局信息,统一处理再 分配单个智能体去执行。而在 Dec-MDPs 模型中, 每个智能体有独立的环境与状态观测,可根据局部 信息做出决策。重点针对智能体间信息交互的模型 主要有交互式 POMDP(interactive POMDP, I-POMDP)[10] ,其主要采用递归推理 (recursive reasoning)的对手建模方法对其他智能体的行为进 行显式建模,推断其它智能体的行为信息,然后采 取应对行为。以上介绍的主要是基于决策理论的智能体学习模型及相关方法。如图 2 所示,这些模型 都属于部分可观随机博弈 (partial observation stochastic game, POSG)模型的范畴。
![]()
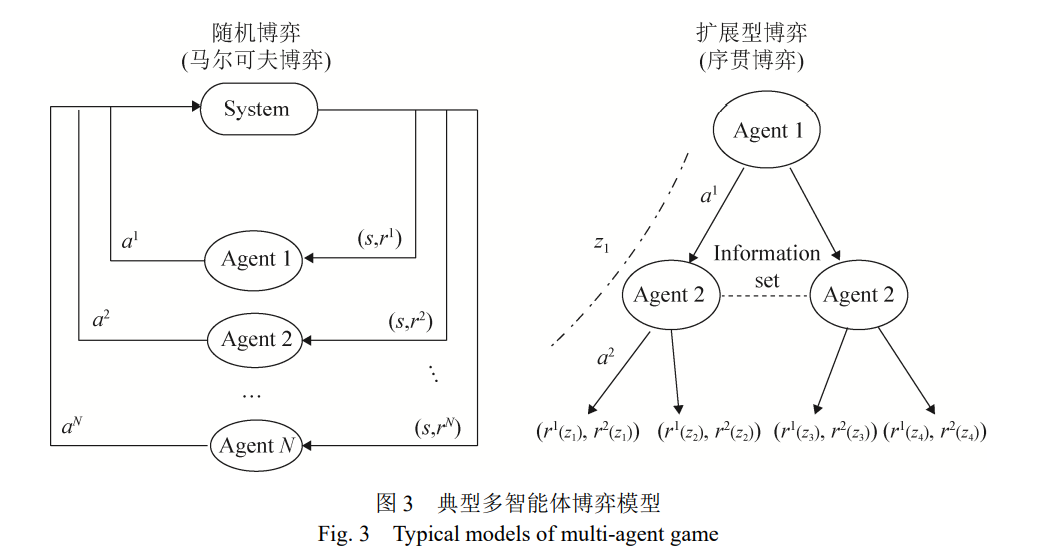
当前,直接基于博弈理论的多智能体博弈模型 得到了广泛关注。如图 3 所示,其中有两类典型的 多智能体博弈模型:随机博弈(stochastic game),也 称马尔可夫博弈(markov game)模型适用于即时战 略游戏、无人集群对抗等问题的建模;而扩展型博 弈(extensive form game, EFG)模型常用于基础设施 防护,麻将、桥牌等回合制游戏(turn-based game) 的序贯交互,多阶段军事对抗决策等问题的建模。最新的一些研究为了追求两类模型的统一,将扩展 型博弈模型的建模成因子可观随机博弈(factored observation stochastic game)模型。
![]()
1.2 非平稳问题
多智能体博弈对抗面临信息不完全、行动不确 定、对抗空间大规模和多方博弈难求解等挑战,在 博弈对抗过程中,每个智能体的策略随着时间在不 断变化,因此每个智能体所感知到的转移概率分布 和奖励函数也在发生变化,故其行动策略是非平稳 的。当前,非平稳问题主要采用在线学习[11]、强化 学习和博弈论理论进行建模[12]。智能体处理非平衡 问题的方法主要有五大类:无视(ignore)[13],即假 设平稳环境;遗忘(forget)[14],即采用无模型方法, 忘记过去的信息同时更新最新的观测;标定(target) 对手模型[15],即针对预定义对手进行优化;学习 (learn)对手模型的方法[16],即采用基于模型的学习 方法学习对手行动策略;心智理论(theory of mind, ToM)的方法[17],即智能体与对手之间存在递归推 理。面对拥有有限理性欺骗型策略的对手,对手建 模(也称智能体建模)已然成为智能体博弈对抗时必 须拥有的能力[18-20],它同分布式执行中心化训练、 元学习、多智能体通信建模为非平稳问题的处理提 供了技术支撑[21]。
合理的预测对手行为并安全的利用对手弱点, 可为己方决策提供可效依据。要解决博弈中非完全 信息的问题,最直接的思想就是采取信息补全等手 段将其近似转化为其完全信息博弈模型而加以解决。本文中,对手建模主要是指利用智能体之间的 交互信息对智能体行为进行建模,然后推理预测对 手行为、推理发掘对手弱点并予以利用的方式。
针对多智能体博弈对抗中的非平稳问题,以及 对手建模面临的挑战,本文基于元博弈理论,从智 能体认知行为出发,试图建立一个满足多智能体博 弈对抗需求的通用对手建模框架。
![]()
![]()
![]()
多
智能体博弈对抗过程中,可能面临对手信息 不完全、信息不完美、信息不对称等挑战。本文旨 在构建面向非平稳环境的通用对手建模框架。首先 从多智能体博弈对抗的角度介绍了当前多智能体 博弈的几类典型模型和非平稳问题。其次,结合对 手建模前沿理论梳理总结了两大类共八小类对手 建模方法,并对其应用前景和面临的挑战进行详细 分析。最后,基于元博弈理论,从对手策略识别与 生成、对手策略空间重构、对手策略利用三个方面 构建了一个通用的对手建模框架,并指出了对手建 模的未来六大主要研究方向。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
专知,专业可信的人工智能知识分发
,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai,获取100000+AI(AI与军事、医药、公安等)主题干货知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程资料和与专家交流咨询!
点击“
阅读原文
”,了解使用
专知
,查看获取100000+AI主题知识资料