Facebook AI新研究:可解释神经元或许会阻碍DNN的学习

新智元报道
新智元报道
来源:Facebook AI
编辑:QJP
【新智元导读】Facebook AI 近期更新博客介绍了一篇新论文,即研究人员通过实验发现「易于解释的神经元可能会阻碍深层神经网络的学习」。为了解决这些问题,他们提出了一种策略,通过可伪造的可解释性研究框架的形式来探讨出现的问题。

「类选择性」:深度神经网络可解释性的工具
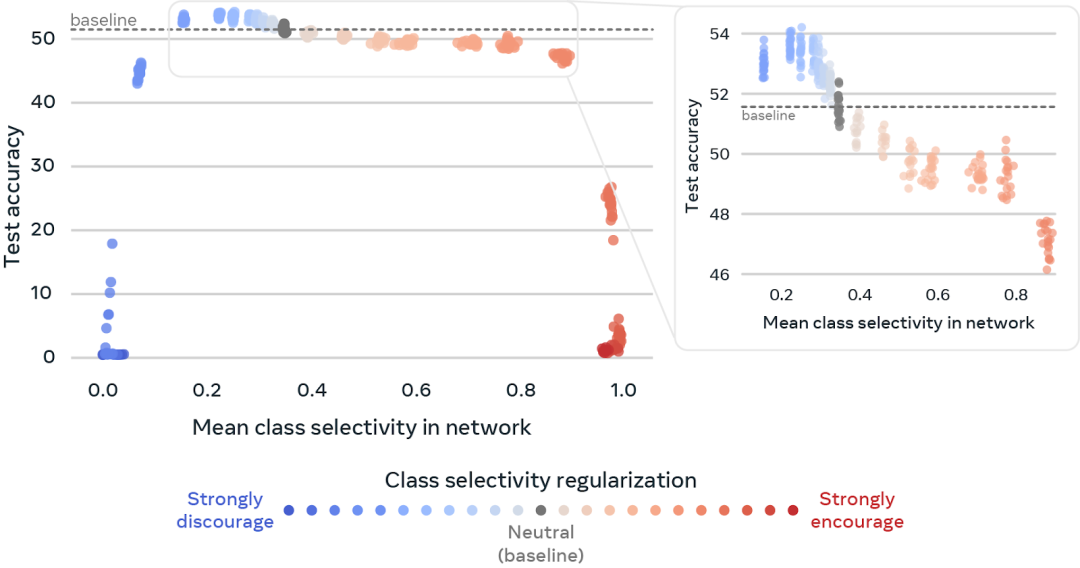
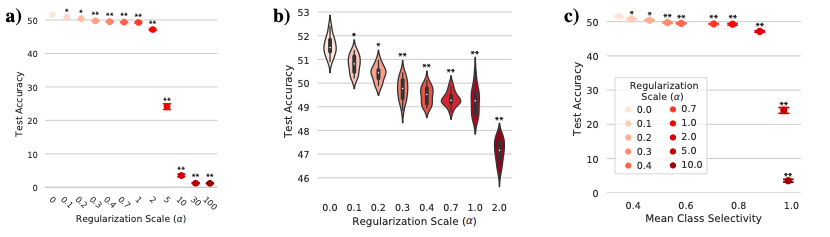
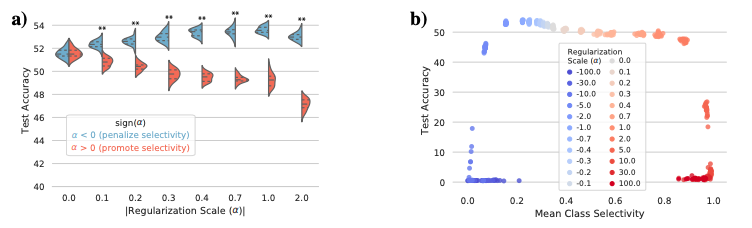
走出实验室,生产环境中数据更复杂


登录查看更多
相关内容



相关VIP内容
相关资讯
相关论文