NLP博士答辩41页PPT,面向自然语言处理的神经网络迁移学习

新智元推荐
新智元推荐
来源:专知(ID:Quan_Zhuanzhi)
【新智元导读】现实中的自然语言处理面临着多领域、多语种上的多种类型的任务,为每个任务都单独进行数据标注是不大可行的。迁移学习可以将学习的知识迁移到相关的场景下。本文介绍 Sebastian Ruder 博士的面向自然语言处理的神经网络迁移学习的答辩 PPT。
NLP 领域活跃的技术博主 Sebastian Ruder 最近顺利 PhD 毕业,下周即将进入 DeepMind 开启 AI 研究员生涯。
Sebastian Ruder 博士的答辩 PPT《Neural Transfer Learning for Natural Language Processing》介绍了面向自然语言的迁移学习的动机、研究现状、缺陷以及自己的工作。
Sebastian Ruder 博士在 PPT 中阐述了使用迁移学习的动机:
state-of-the-art 的有监督学习算法比较脆弱:
易受到对抗样本的影响
易受到噪音数据的影响
易受到释义的影响
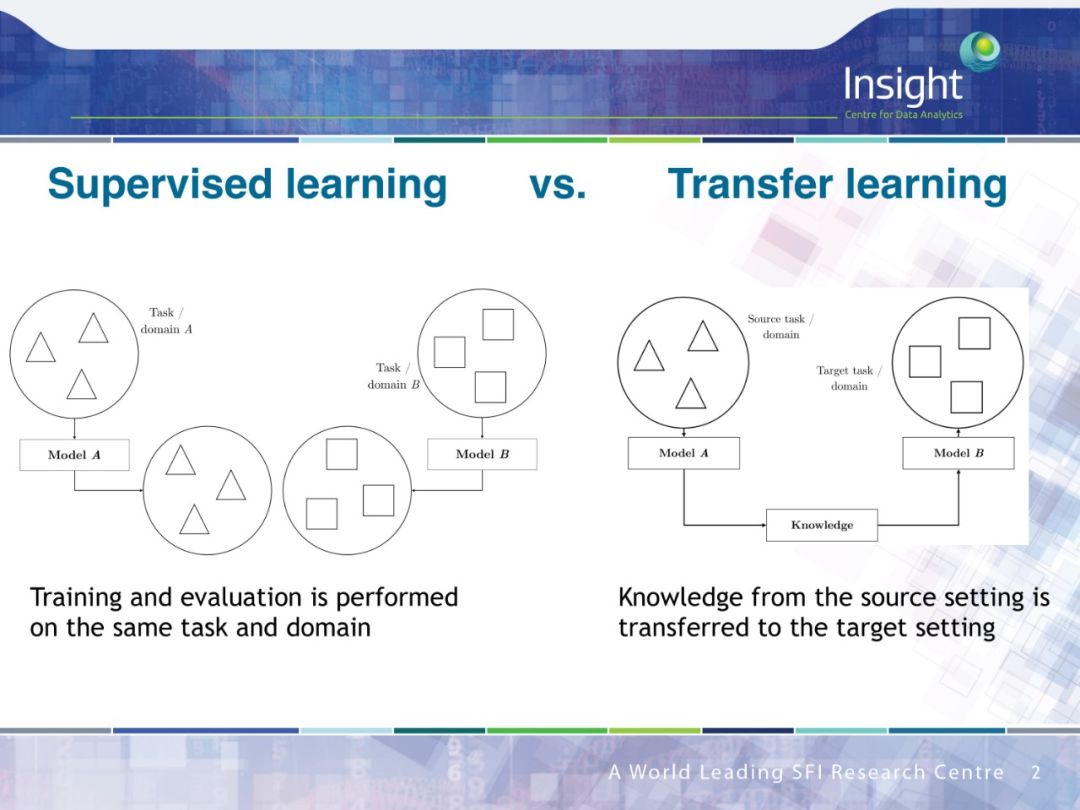
现实中的自然语言处理面临着多领域、多语种上的多种类型的任务,为每个任务都单独进行数据标注是不大可行的,而迁移学习可以将学习的知识迁移到相关的场景下
许多基础的前沿的 NLP 技术都可以被看成是迁移学习:
潜在语义分析 (Latent semantic analysis)
Brown clusters
预训练词向量(Pretrained word embeddings)
已有的迁移学习方法往往有着下面的局限性:
过度约束:预定义的相似度指标,硬参数共享
设置定制化:在一个任务上进行评价,任务级别的共享策略
弱 baseline:缺少和传统方法的对比
脆弱:在领域外表现很差,依赖语种、任务的相似性
低效:需要更多的参数、时间和样本
因此,作者认为研究迁移学习需要解决下面的这些问题:
克服源和目标之间的差距
引起归纳偏置
结合传统和现有的方法
在 NLP 任务中跨层次迁移
泛化设置
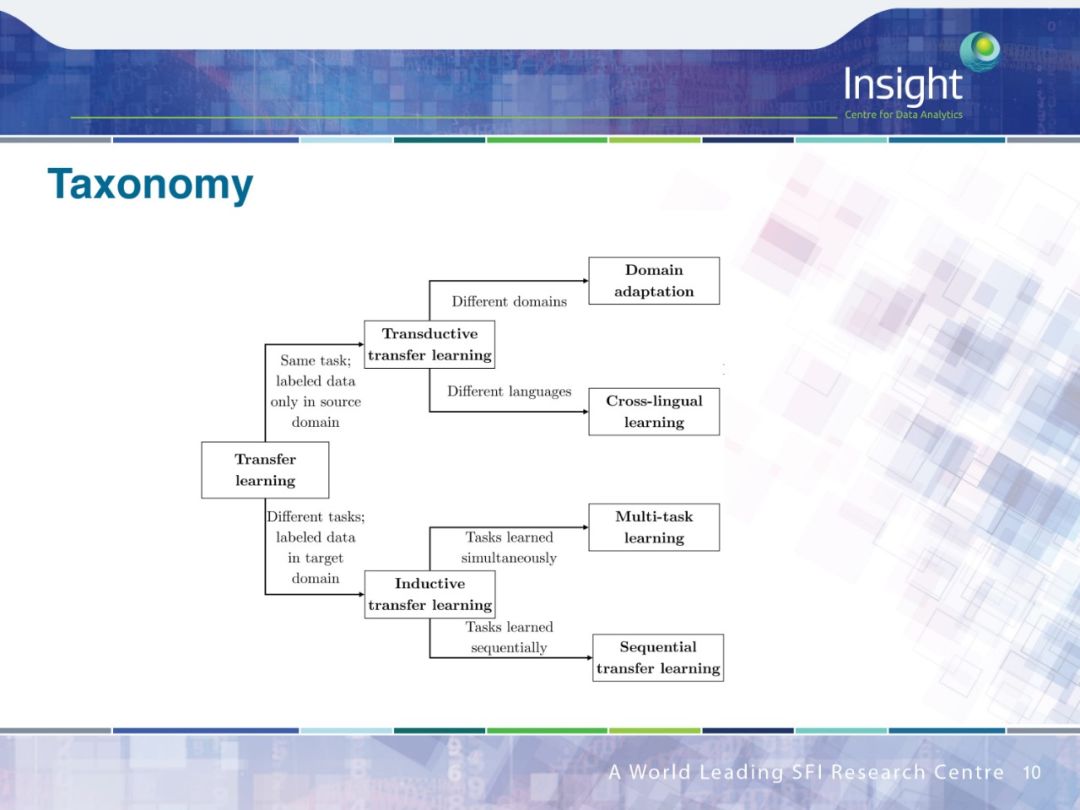
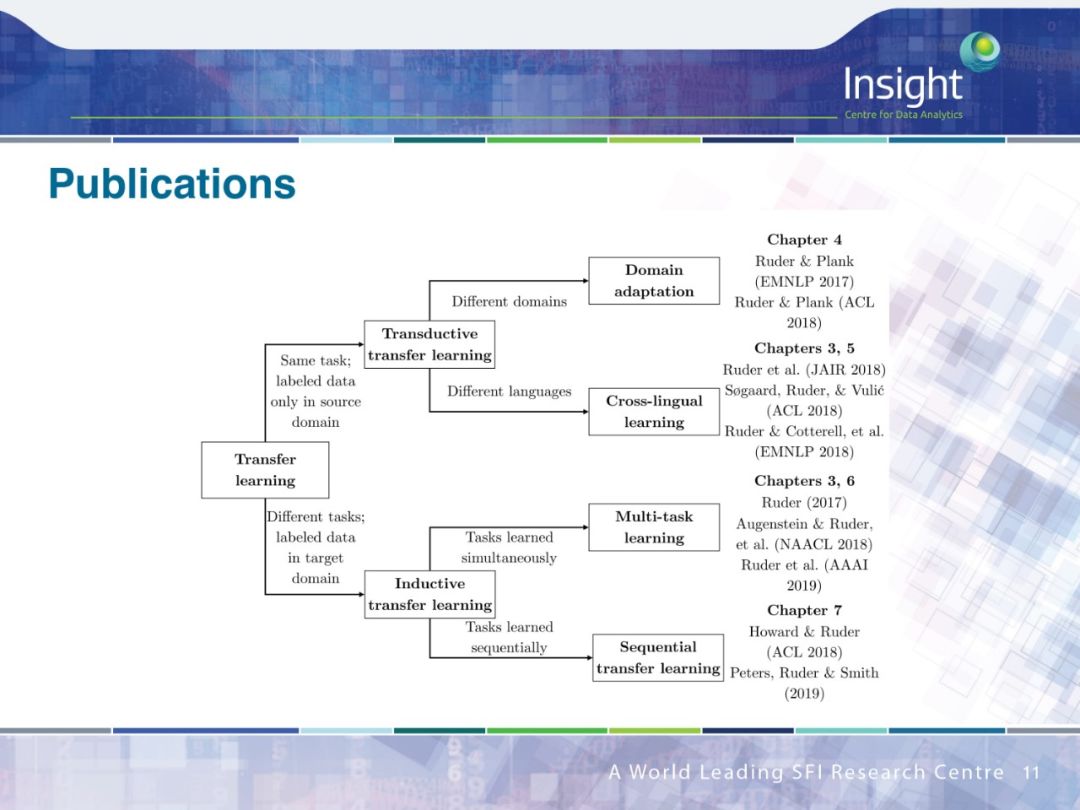
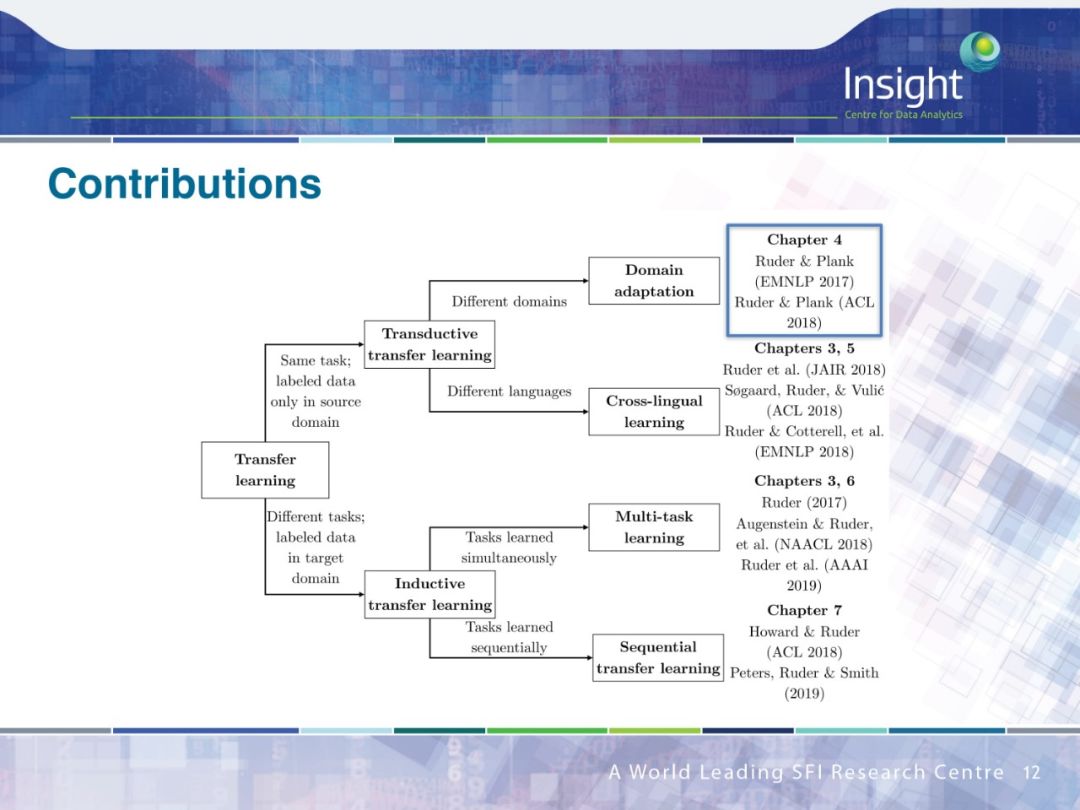
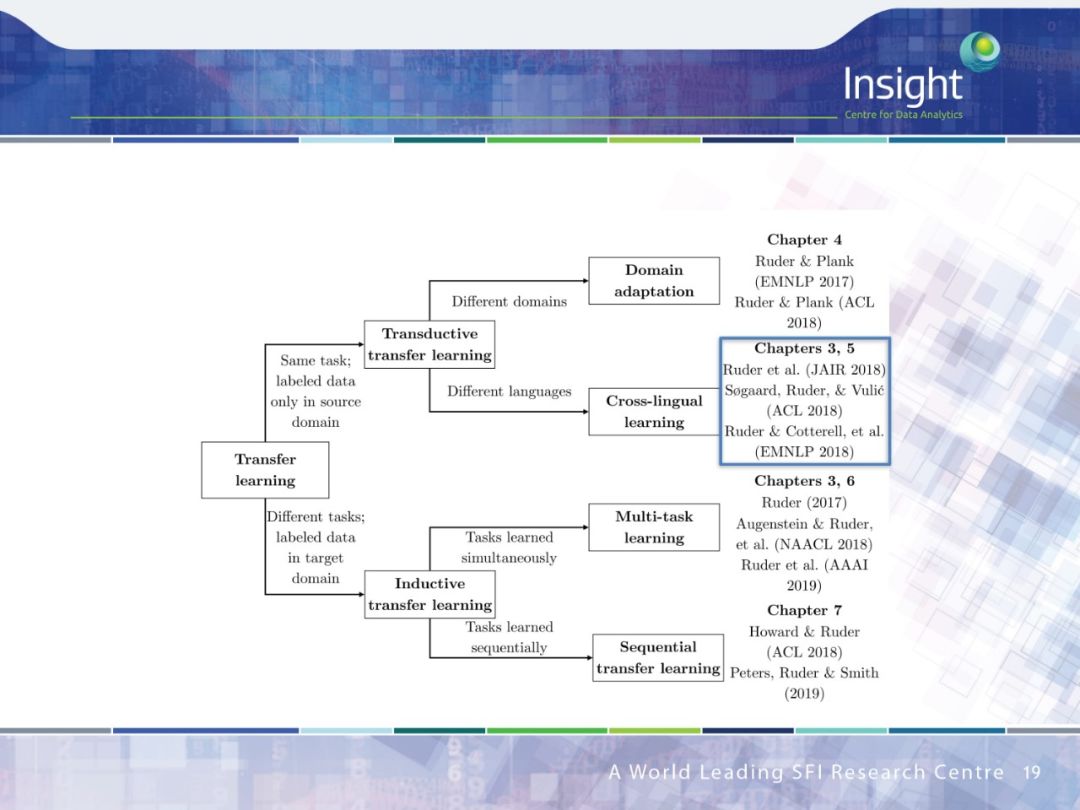
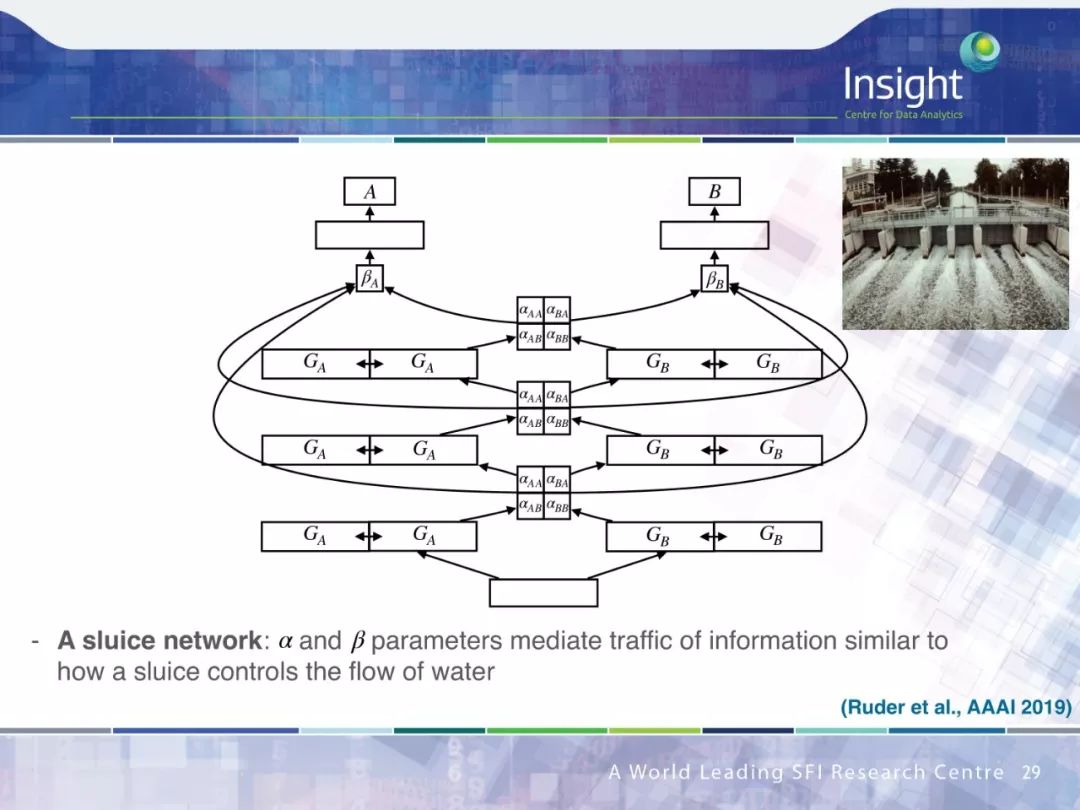
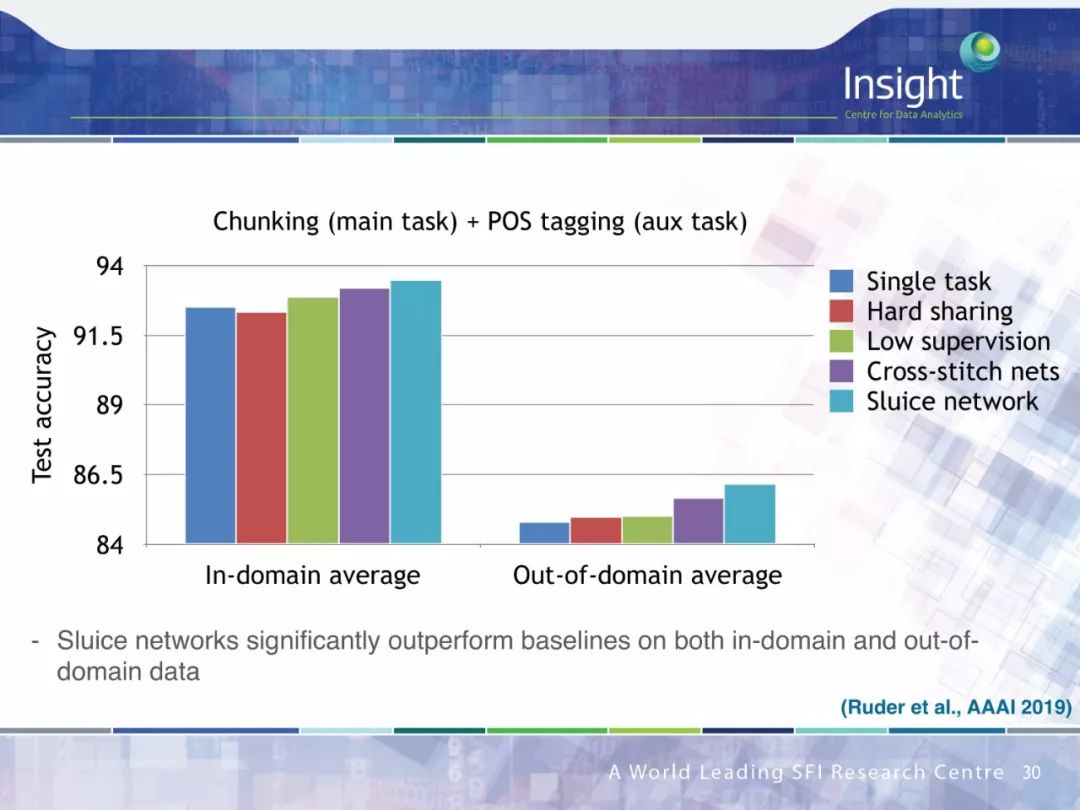
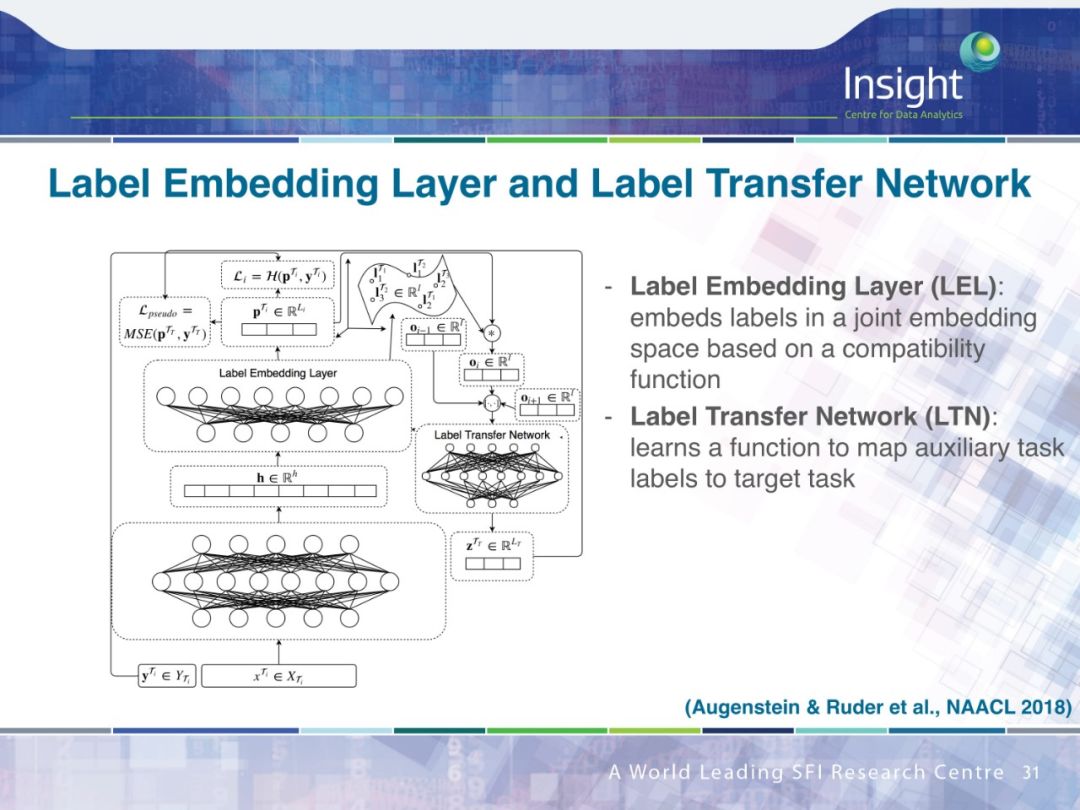
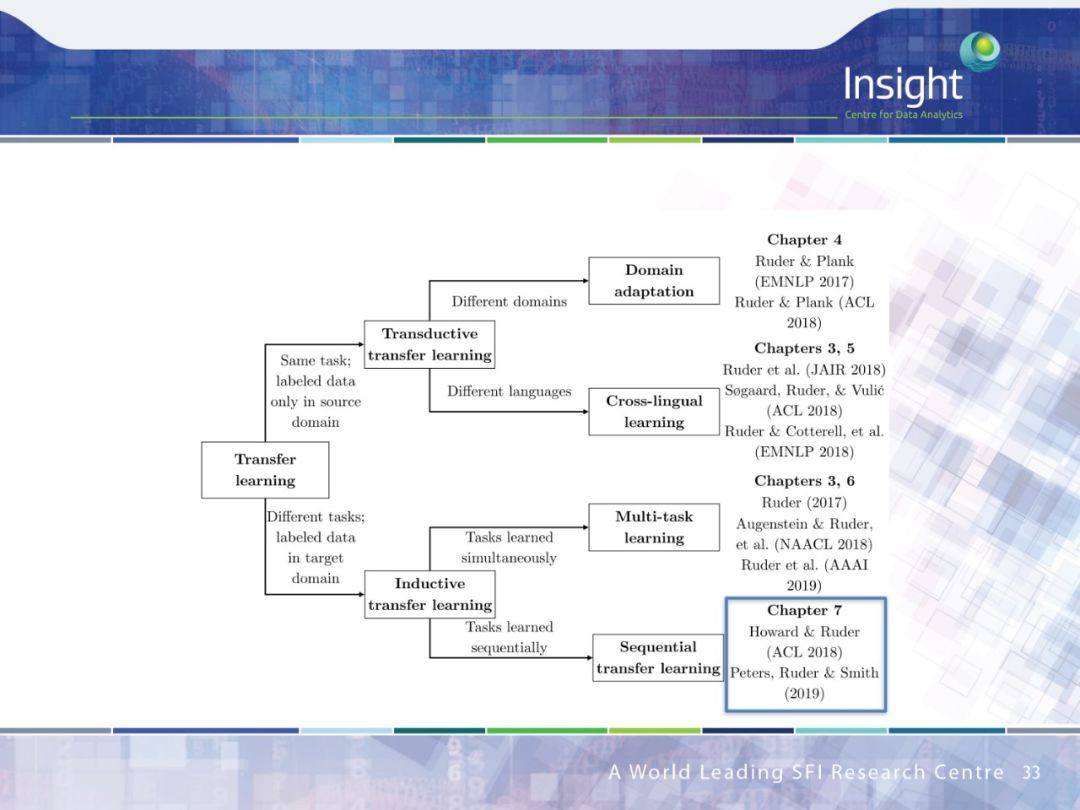
作者围绕迁移学习做了 4 个方面的工作:
领域适应(Domain Adaption)
跨语种学习(Cross-lingual learning)
多任务学习(Multi-task learning)
序列迁移学习(Sequential transfer learning)
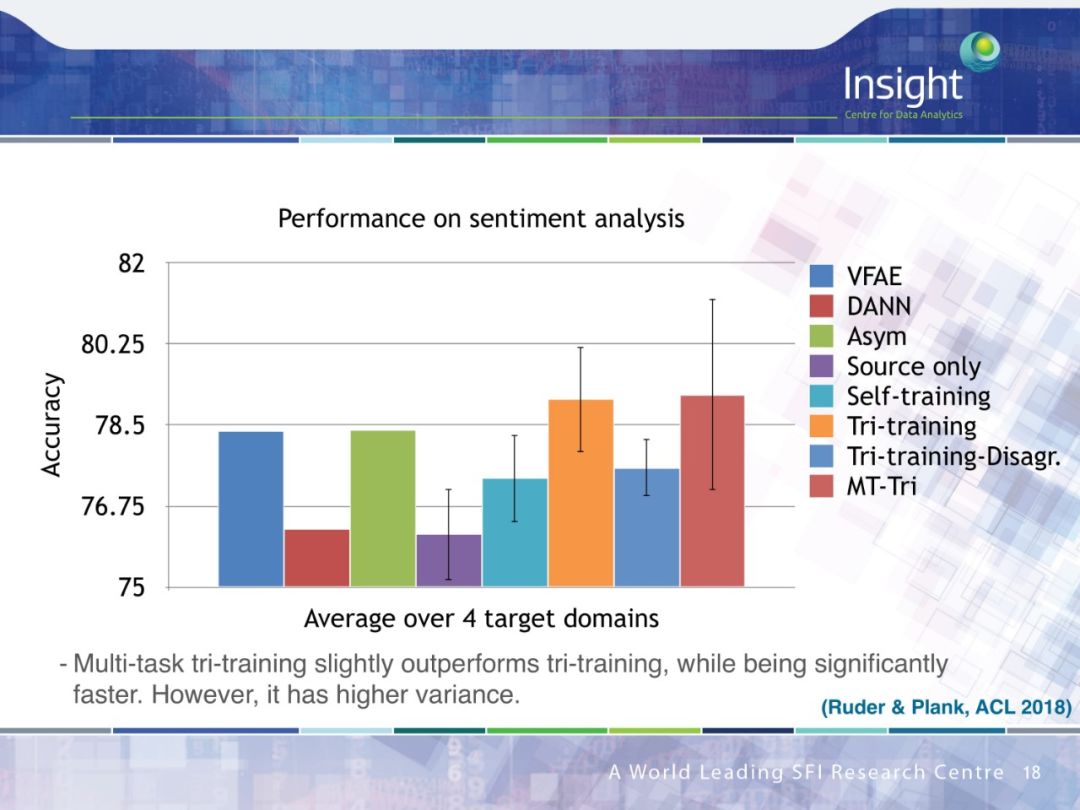
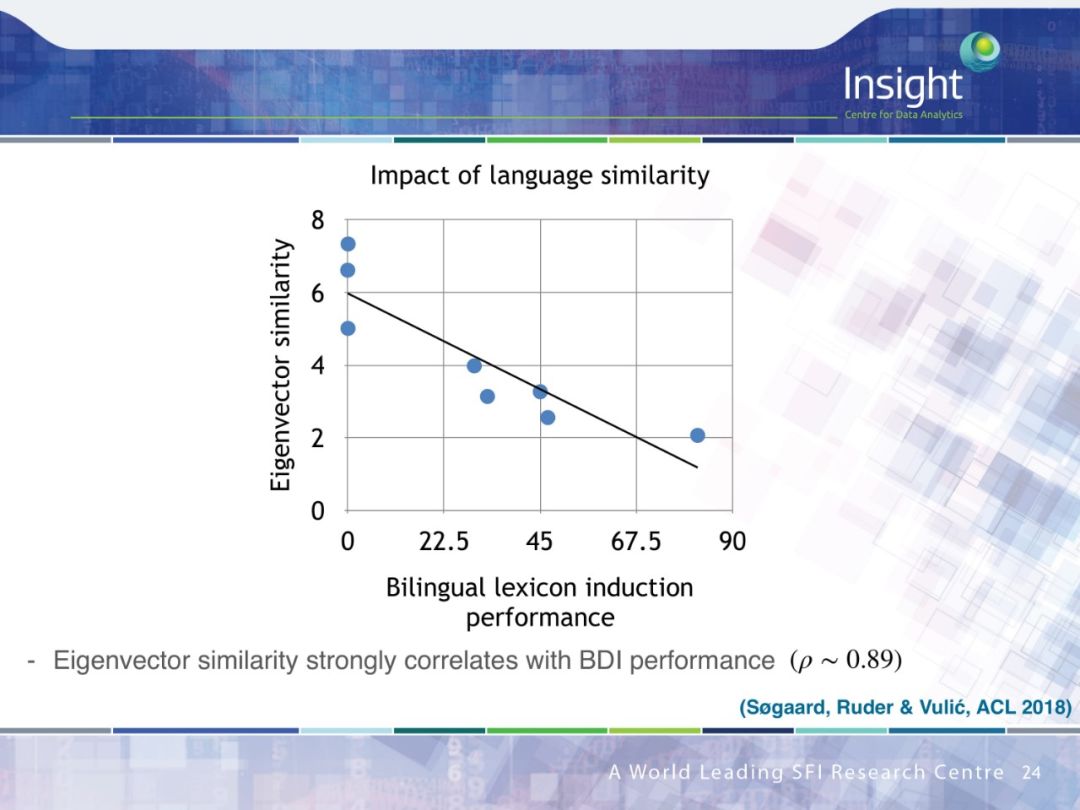
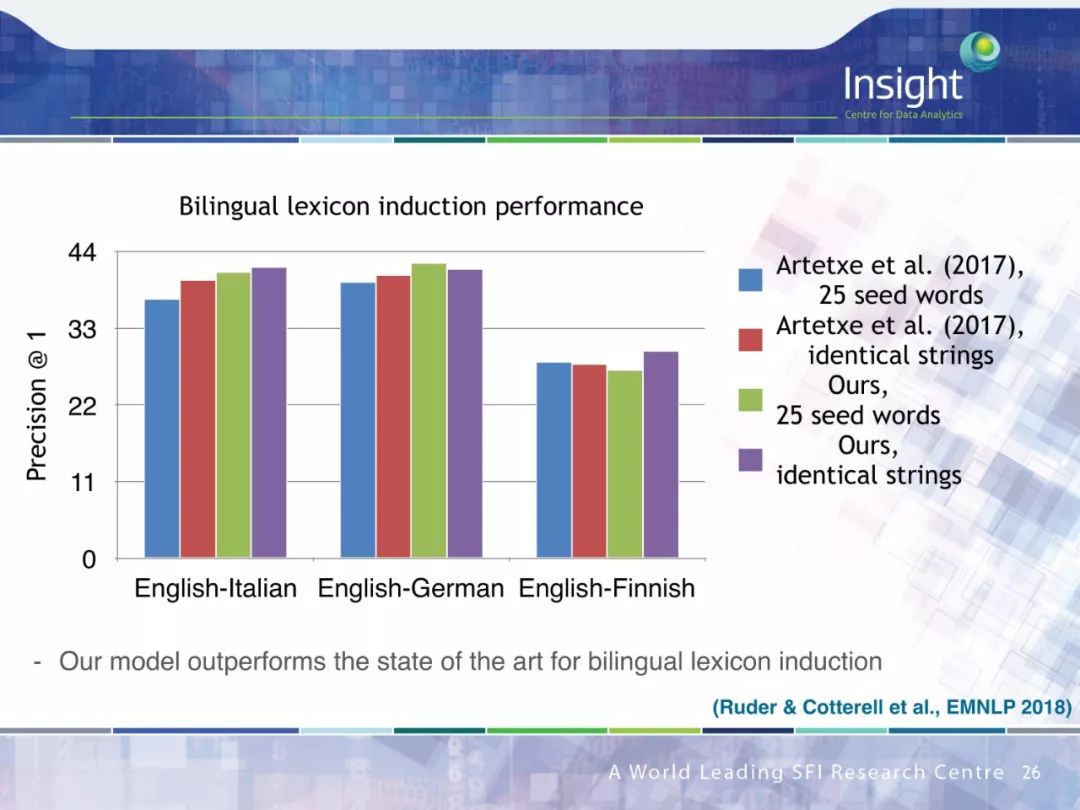
具体内容可在 Sebastian Ruder 博士的完整答辩 PPT 中查看。









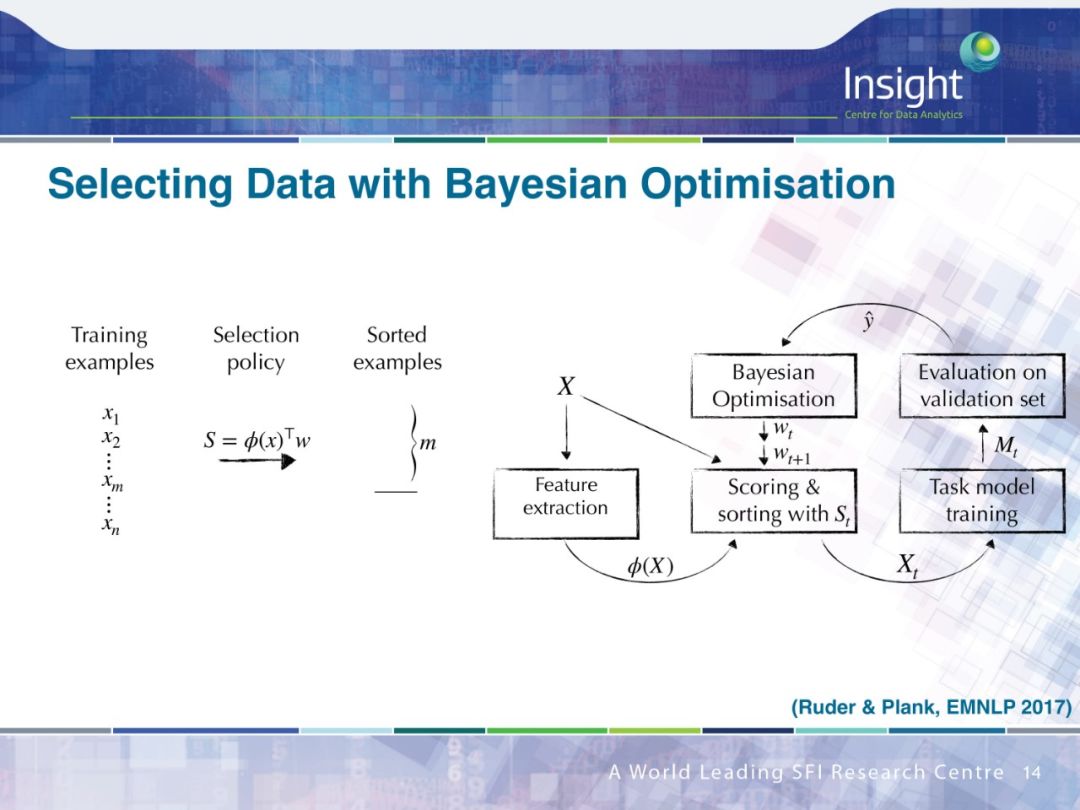
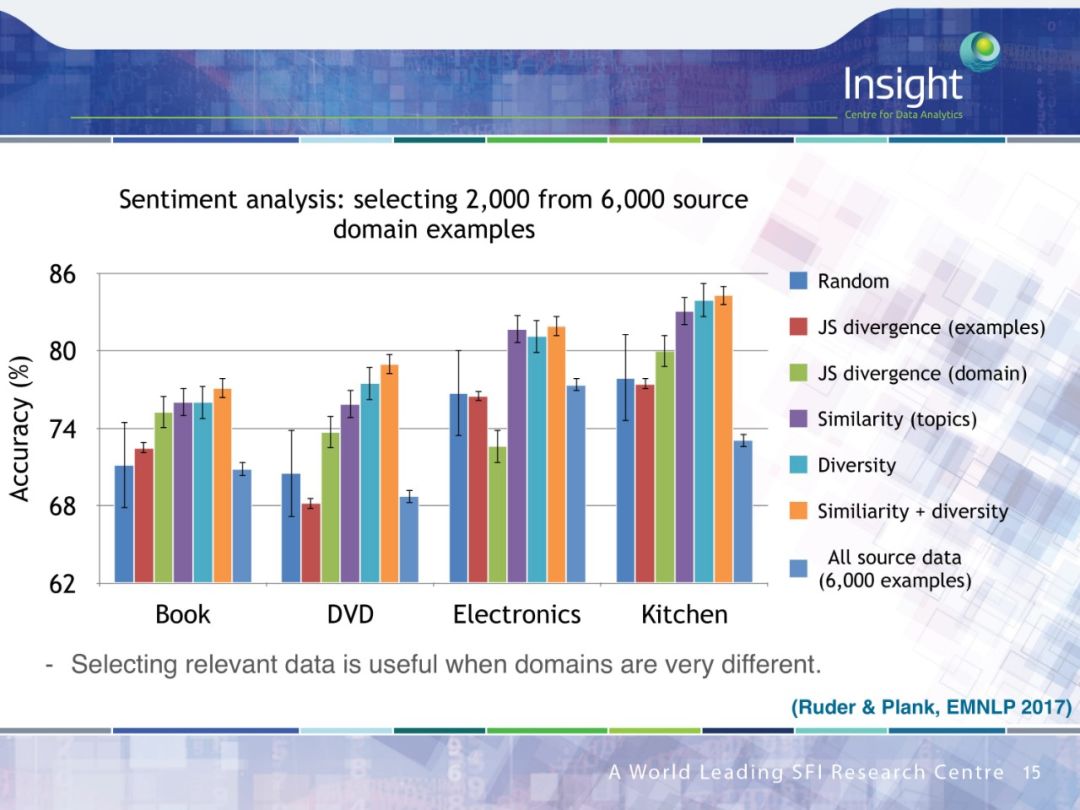
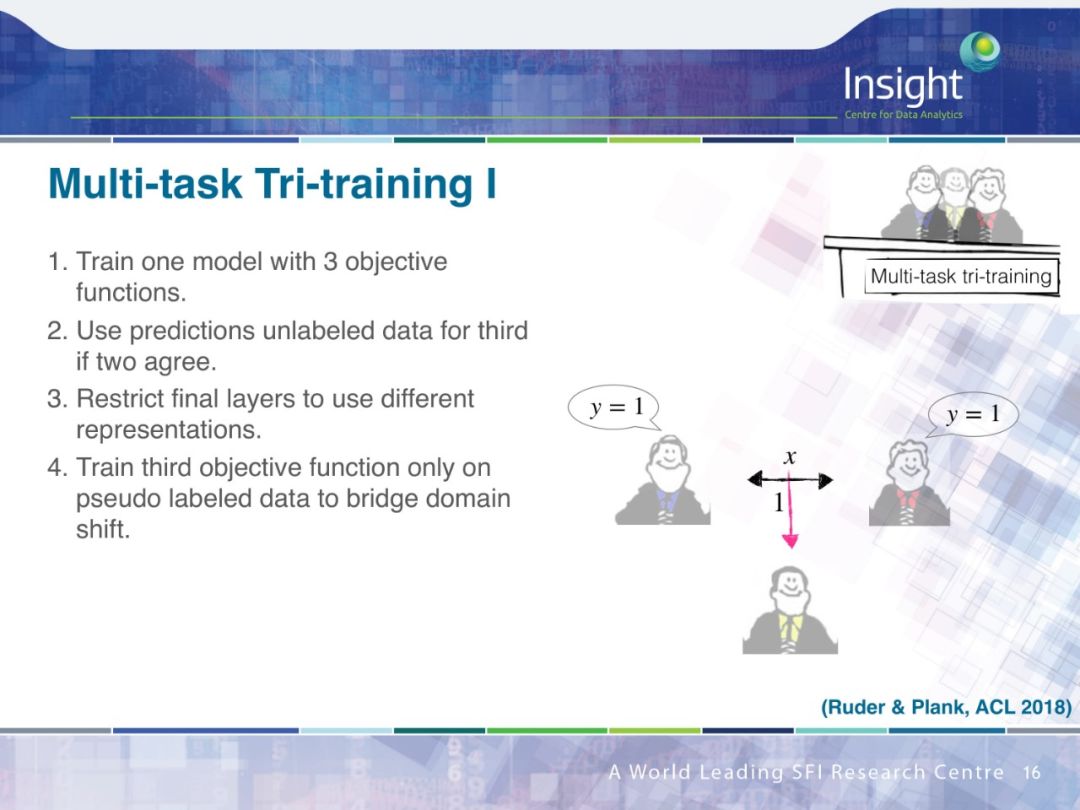
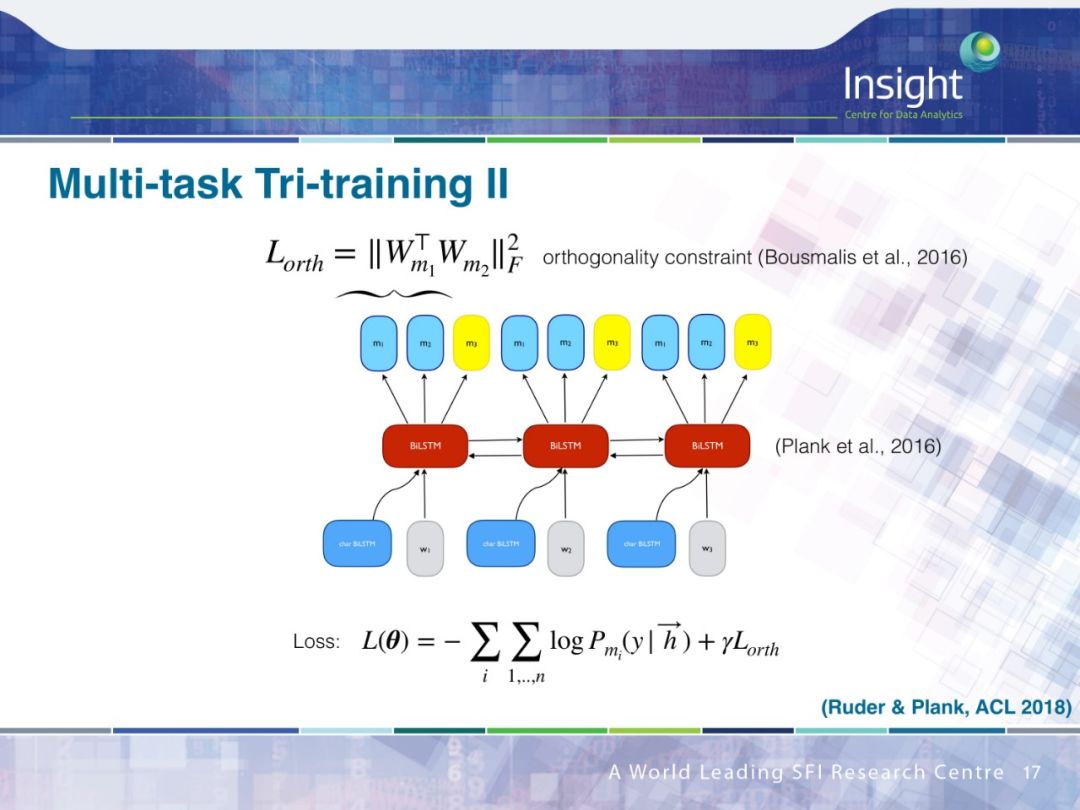












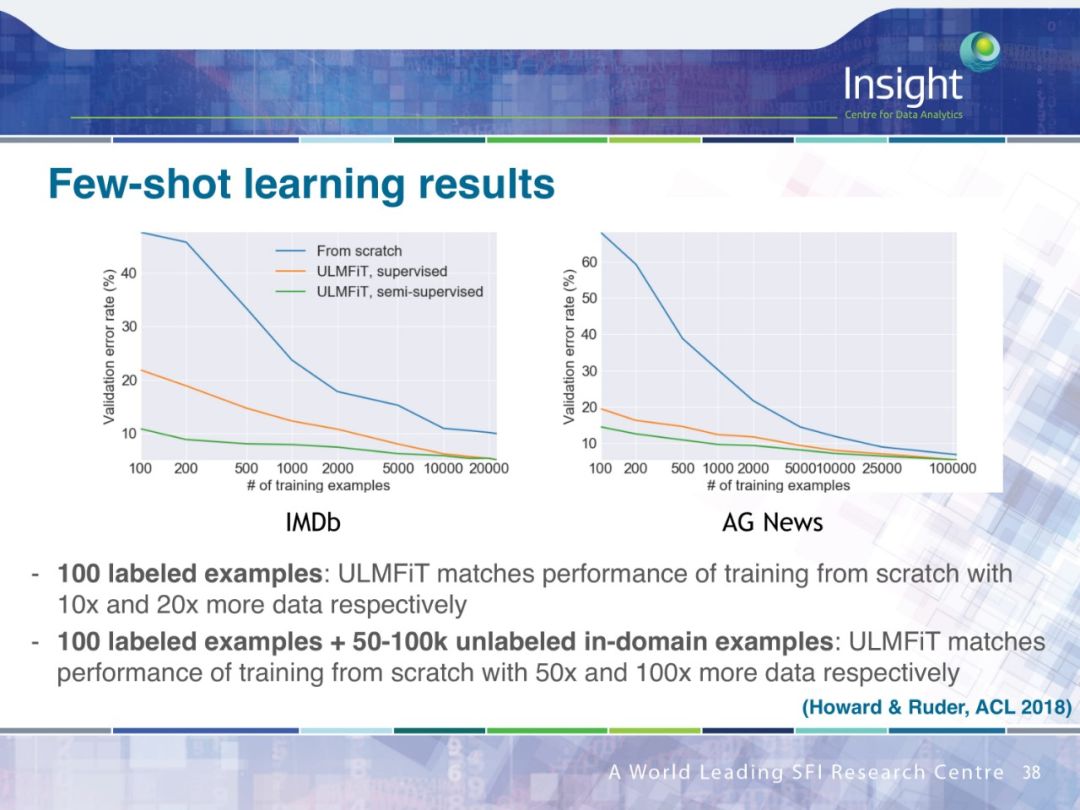
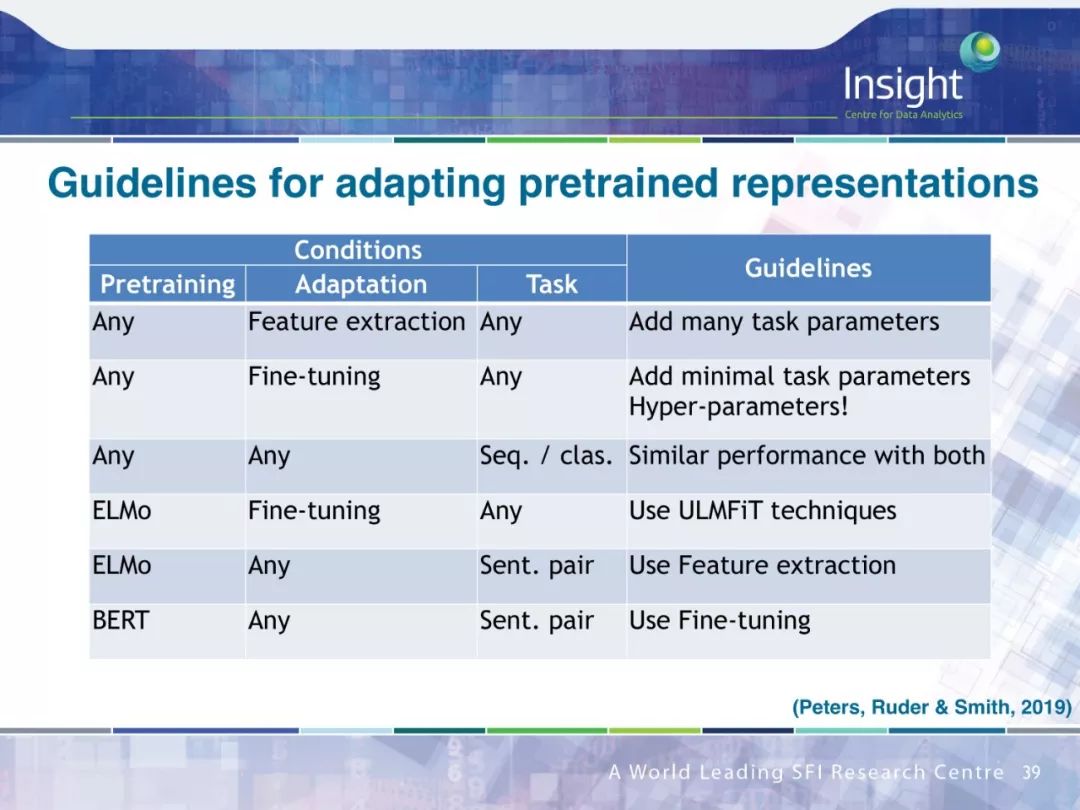


PPT下载链接:
https://drive.google.com/file/d/1Jhzd8gWK7M_76t1WfNBcB5gzPIAYZAS1/view
本文转载自专知(ID: Quan_Zhuanzhi),请点击阅读原文查看原文。
【加入社群】
新智元AI技术+产业社群招募中,欢迎对AI技术+产业落地感兴趣的同学,加小助手微信号:aiera2015_2 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。






