【泡泡图灵智库】GANVO:一种基于生成对抗网络的无监督深度单目视觉里程计与深度估计方法(arXiv)
泡泡图灵智库,带你精读机器人顶级会议文章
标题:GANVO: Unsupervised Deep Monocular Visual Odometry and Depth Estimation with Generative Adversarial Networks
来源:arXiv:1809.05786
编译:李雨昊
审核:万应才
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——GANVO:一种基于生成对抗网络的无监督深度单目视觉里程计与深度估计方法,该文章发表于rXiv:1809.05786。
在过去十年,有监督的深度学习方法广泛应用于视觉里程计领域,但是在没有丰富标签数据的环境中是不可行的。另一方面,在VO研究中,对在未知环境中使用无标签数据进行定位和建图的无监督深度学习方法相较而言获得较少关注度。本次研究中,作者提出一种生成式无监督学习框架,通过使用深度卷积生成式对抗神经网络从无标签RGB影像序列中预测包含6自由度的相机运动姿态以及单目深度图。作者通过变换视图序列以及最小化在多视姿态生成与单视图深度生成网络中所使用到的目标损失函数来产生一种监督信号。在KITTI和Cityscapes数据集上对本文提出的算法进行了详细的定性和定量验证,同时表明本算法优于当下传统VO算法以及无监督深度VO算法,并且在姿态估计和深度恢复均取得更好结果。
主要贡献
1、本文首次提出在单目VO中使用对抗式神经网络和循环无监督学习方法来联合估计姿态和深度图;
2、作者提出一种新的对抗式技术,使得GANs可以在没有深度真值信息的情况下生成深度影像;
3、相较于传统VO方法,本文算法在姿态和深度估计中没有严格精确的参数调整过程。
算法流程
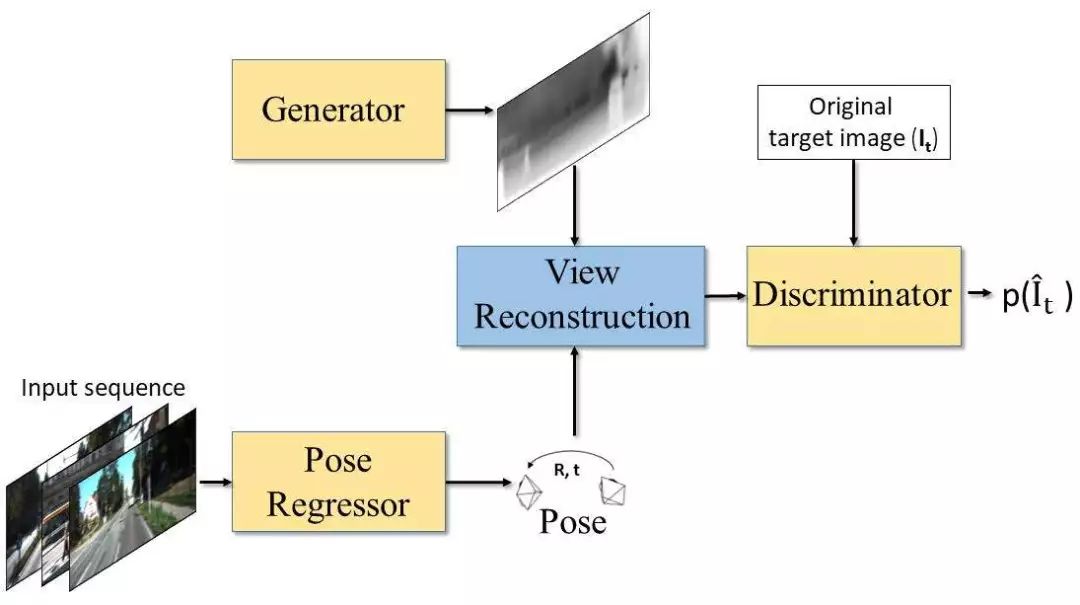
图1 本文方法整体架构
如图1所示,将包含目标视图和源视图的原始RGB序列堆叠在一起成为一个输入块输入到多视姿态估计模块中,该模块回归出源视图相对于目标视图的6自由度相对姿态值。在并行的另一线程中,深度产生模块生成目标视图的深度图。在视图重建模块通过使用生成的深度图、估计得到的6DOF相机姿态以及源影像附近的颜色(RGB)值人工合成目标影像。视图重建约束提供了一种监督信号使得神经网络可以从不同相机姿态得到的多张源影像中合成一张目标影像。而视图判别模块试图从原始目标影像中区分出合成的目标影像。
在本文提出的GAN网络的对抗机制中,生成器的目的是为了欺骗判别器,例如,为目标视图重建生成一个深度图,使得判别器无法从由源图像产生的重建结果以及合成影像的重建结果中将这些合成影像区分出来。与传统的GAN不同的是,生成器产生的结果图被映射到了影像的彩色空间,判别器在彩色空间进行区分而不是直接比较生成器得到的输出结果。
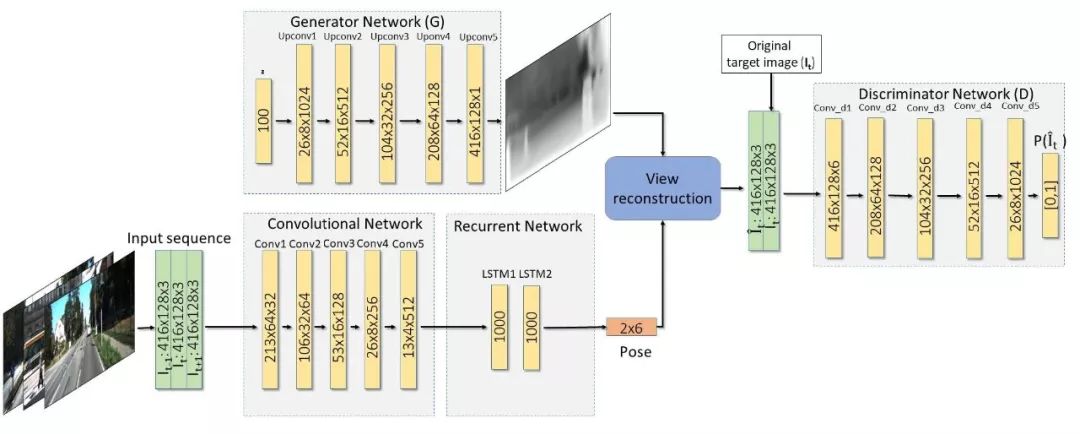
图2 算法流程图
图2 为提出的深度估计及产生深度图的网络架构,层的空间维度与输出通道显示了贯穿整个网络的张量尺寸。生成器G将一个以先验分布p采样的随机向量映射到深度影像空间。姿态估计网络包含一个提取VO相关特征的卷积网络和一个捕获输入帧序列间时相关系的循环神经网络。穿过循环神经网络之后可以得到姿态结果,因为是6自由度的运动参数,因此会输出通道为6*(N-1)的结果,N代表序列的长度。视图重建算法之后是一个判别器D,判别器将重建的RGB影像映射成为一个目标影像的可能性值。D判断该值是来源于重建结果还是原始影像。
A、深度生成器
架构的第一部分是一个可以产生目标帧单视深度图的网络。该网络是基于GAN思想设计的,尝试从输入影像中学习得到其概率分布,包含一个生成器G和一个判别器D。G将从先验分布为P采样的随机向量映射到深度影像空间,D将输入的RGB影像映射为一个可能性值输出。
B、姿态回归
在图2网络下方为姿态估计网络。它将使用卷积神经网络从输入帧序列中提取特征并将其传入到RNN中,LSTM模块输出6自由度的姿态值,其中包含平移和旋转参数。尽管第一个LSTM已经可以获得序列之间的关系,作者又增加了一个LSTM网络以提高网络的学习能力,并产生更加准确的姿态回归结果。
C、视图重建
输入数据为三个连续的影像帧<It-1,It,It+1>,t为时间,It为目标视图,其余为源视图,这些源视图Is=<It-1,It+1>根据目标函数(式1)获得目标影像:
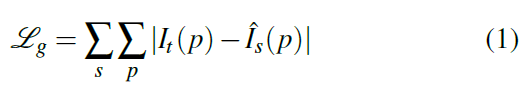
P为像素坐标,Ishat为使用深度影像基于渲染模块将源视图Is投影到目标坐标系下的影像。渲染过程基于估计得到的深度影像Dhat,4x4的相机变换矩阵以及源视图Is进行的。将目标视图上像素的齐次坐标定义为pt,相机内参矩阵为K,投影到源影像上的像素pt的坐标可以表示为式2:
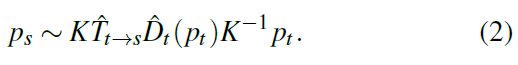
因为ps不是离散的,因此需要通过插值的方式得到对应位置的强度值,作者使用双线性内插方法进行内插,投影像素的平均强度可以表示为式3:
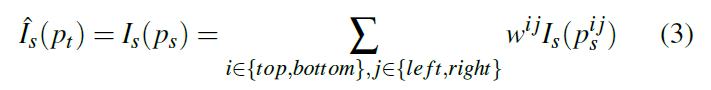
Wij代表投影像素和邻近像素的近似值,和为1.
D、视图判别
利用估计姿态值与深度影像生成器G的视图重建算法人工合成近似真实的影像。判别器D从重建的影像中区分出从分布为p的目标影像中采样得到的真实影像,D即扮演对抗的角色。这些网络是通过优化目标损失函数(式4)进行训练的:(与原始GAN文章中的目标函数近似一致)
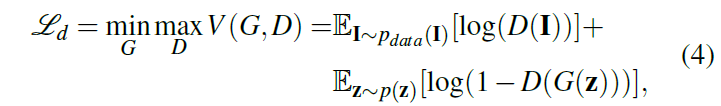
I为以p分布采样的影像,z是潜在空间上的随机编码。
E、对抗式训练
相较于原始的GAN,作者去掉了全连接层,并在G\D网络中使用BN层,并用带步长的卷积层代替了池化层,在判别器中的每一层都使用了Leaky ReLU。在生成器G中,使用微步长卷积层代替了池化层,并在全部非输出层使用ReLU激活层,在输出层使用了Tanh激活层。经过修改的GAN可以生成没有模糊的影像,并且可以在训练时保证收敛。架构中最终优化的权重可以用式5表示:
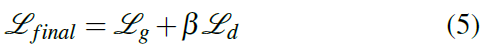
Beta是平衡因子,实验中发现最优的beta位于最终的Lg与Ld之间。
主要结果
作者整个架构基于Tensorflow,使用Adam优化方法来提高收敛率,beta1为0.9,beta2为0.999,学习率为0.1,mini-batch为8。在训练时,输入的张量为128x416的序列影像,测试时,没有影像大小限制。作者在KITTI和Cityscapes数据集上进行了测试并评估了其泛化能力。实验中训练采用NVIDIA TITAN V显卡。
A、姿态估计基准
作者使用KITTI前9个序列数据(00-08)进行训练,使用09,10两个序列数据进行测试。作者在序列长度为5的情况下将本文姿态估计精度与当下无监督深度学习方法以及单目ORB-SLAM结果进行了对比。他们使用绝对轨迹误差ATE评估了5个连续输入帧的位姿估计结果,评估时采用一个优化后的尺度因子来解决尺度任意性的问题,而序列长度为5是根据这些待比较算法中提交的最佳序列长度决定的。如表1和图3所示,本文提出的算法结果优于当下具备竞争力的无监督或传统算法结果,而不需要诸如闭环检测、捆绑平差(Bundle Adjustment)以及重定位等全局优化过程。从而揭示出GANVO不仅可以捕捉到短期(时)低层次的里程计特征,还可以捕捉到长期(时)的高水平里程计细节。
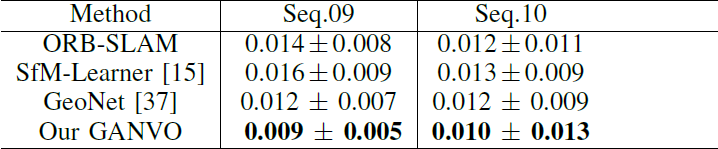
表1 KITTI里程计数据集上的ATE结果
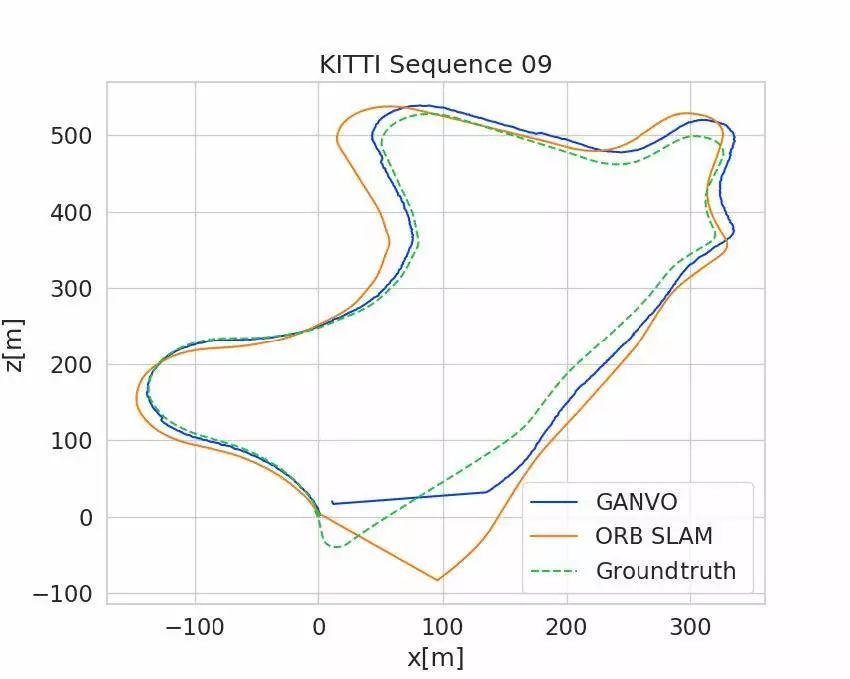
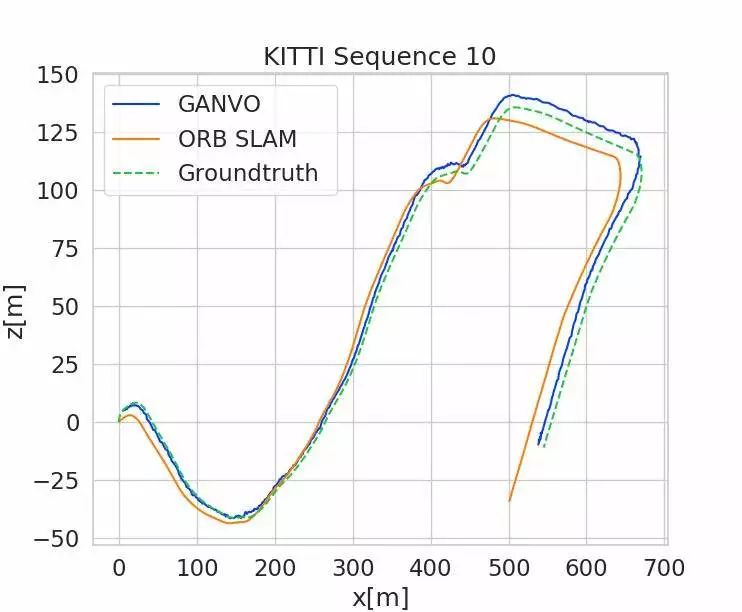
图3 GANVO、ORB-SLAM与真实轨迹之间的比较
B、单视图深度估计
作者在从KITTI数据集中分离出来的影像上对本文提出的深度估计方法进行了评估,并且和当下基于学习的、传统深度估计方法进行了比较。分离出的数据集的总帧数为44000,作者使用40000帧进行训练,剩余4000帧进行验证。输入数据的序列长度为3帧,以便和相比较方法中的评估设置保持一致,中间帧作为目标视图用来进行深度估计。使用LiDAR传感器得到真实数据被反投到影像平面上评估误差和精度。预测的深度图Dp乘以尺度因子s来解决尺度任意性的问题,s是与真实深度图Dg相配的。并且作者通过在Cityscapes数据上进行训练,在KITTI数据上进行微调,测试了算法的泛化能力。
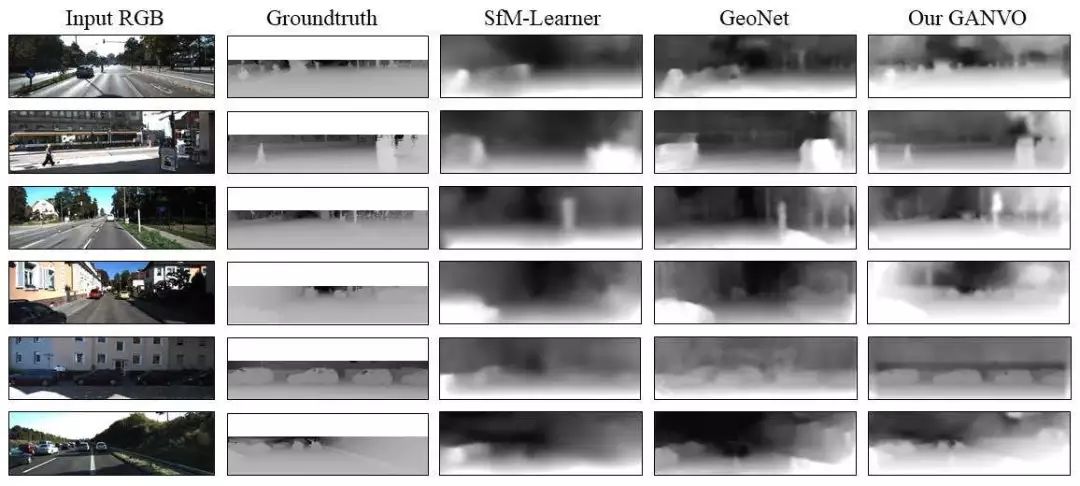
图4不同无监督单目深度估计算法的比较结果。GANVO可以捕获一些诸如低纹理区域、阴影区域、不平整道路线等具有挑战性的环境中的细节,并且在远近区域都可以在预测的深度图中保留更加尖锐和精确的细节。
图4显示了本文提出算法、SFM-Learner与GeoNet的深度值结果。相较于其他以编码-解码器及其变体为基础架构的方法,可以很清楚的看到GANVO能够输出更加尖锐和精确的深度图。作者给出的解释是,在对抗式训练过程中,使用卷积层得到的区域相关特征集的判别器能够获得较少模糊的结果。另外从图4中可以看出,本文提出的GANVO所产生的深度图中能够捕获场景中的较小细节区域,而其他方法都将这些信息忽略了。影像空间的损失函数能够均匀的检测到所有细节可能存在的位置,而带有自然影像先验信息的特征空间中的对抗式损失函数使得本文提出的GANVO对于场景中细节可能存在的部位更加敏感。而且本文的GANVO能够精确地预测出由于阴影不连续等造成的弱纹理区域物体的深度图。同时,在与无监督方法比较时,作者还表明由于一些挑战性场景会导致深度预测失败情况,这些场景诸如乡村地区存在较差路面信号以及输入视频中出现较大物体遮挡等情况。尽管如此,GANVO的性能还是比现有算法性能要好。

图5 本文模型中一些失败的案例。在广泛的乡村开放场景以及相机视角中有较大物体遮挡时,其他算法都失效了。
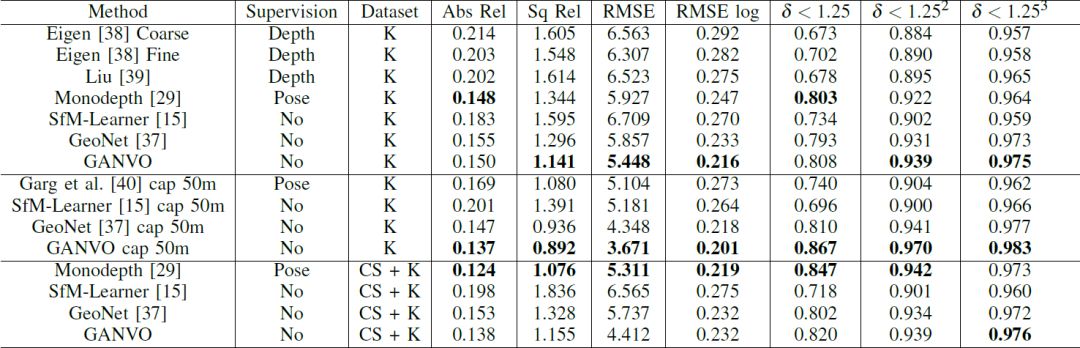
表2 单目深度估计结果。K表示使用KITTI数据集进行训练,CS表示使用Cityscapes数据集进行训练。加粗表示最佳结果。
正如表2的定量结果显示,本文的算法比当下无监督甚至监督学习方法的效果要好。此外,在比较方法在不同环境中的适应能力的基准中,这些方法都是在Cityscapes数据集上进行训练,在KITTI数据集上进行微调。这种基准条件下,本文的方法相比现有方法可以得到更好的精度更小的误差。GANCO可以得到与使用左右影像一致性约束的无监督深度估计方法估计的深度更加接近的结果。
图6显示本文提出算法与现存算法在参数敏感性方面的分析结果,作者表示无论是在采用不同网络参数初始化方法、不同的数据划分方式还是在不同优化参数变化的情况下,本文的方法对超参数的调整都更加稳健。
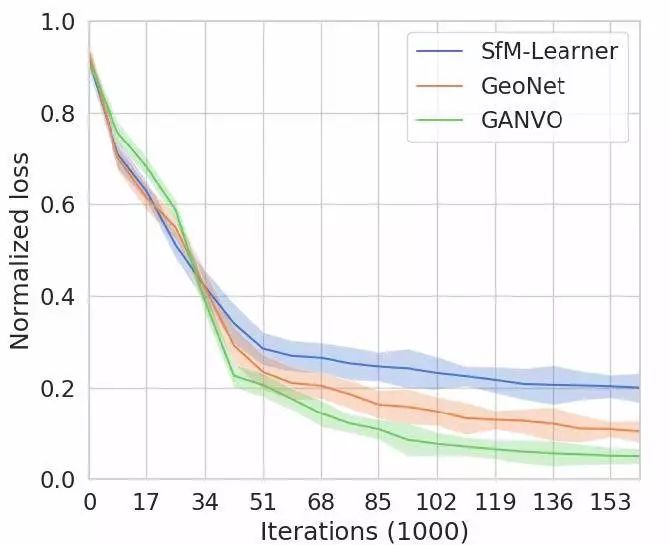
图6 训练过程中归一化后的损失值,可以看出GANVO对超参数的敏感性较低,其均值和方差变得更小。

Abstract
In the last decade, supervised deep learning approaches have been extensively employed in visual odometry (VO) applications, which is not feasible in environments where labelled data is not abundant. On the other hand, unsupervised deep learning approaches for localization and mapping in unknown environments from unlabeled data have received comparatively less attention in VO research. In this study, we propose a generative unsupervised learning framework that predicts 6-DoF pose camera motion and monocular depth map of the scene from unlabelled RGB image sequences, using deep convolutional Generative Adversarial Networks (GANs). We create a supervisory signal by warping view sequences and assigning the re-projection minimization to the objective loss function that is adopted in multi-view pose estimation and single-view depth generation network. Detailed quantitative and qualitative evaluations of the proposed framework on the KITTI and Cityscapes datasets show that the proposed method outperforms both existing traditional and unsupervised deep VO methods providing better results for both pose estimation and depth recovery.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com


