看完发现RNN原来是这样,机器学习人门贴送上
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要5分钟
跟随小博主,每天进步一丢丢


白交 发自 凹非寺
量子位 报道 | 公众号 QbitAI
今天写给小白的机器学习入门贴,就来介绍一下什么是循环神经网络,也就是RNN。
循环神经网络就是专门处理序列的。由于它们在处理文本方面的有效性,因此经常用于自然语言处理(NLP)任务。
还是之前介绍的那个作者——Victor Zhou。
RNN有什么用?
传统的神经网络,以及CNN,它们存在的一个问题是,只适用于预先设定的大小。
通俗一点,就是采用固定的大小的输入并产生固定大小的输出。
就比如上次提到的CNN例子,以4×4图像为输入,最终指定输出2×2的图像。
而RNN呢?它专注于处理文本,其输入和输出的长度是可变的,比如,一对一,一对多,多对一,多对多。
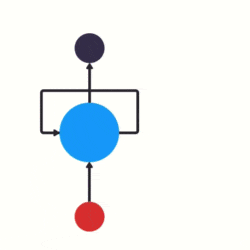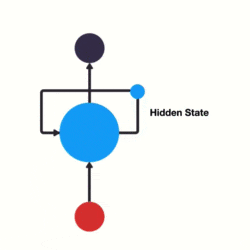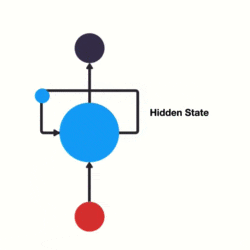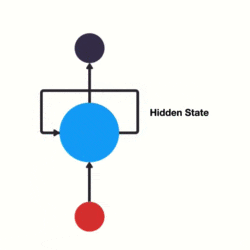
看这个图,我想你就可以明白了。
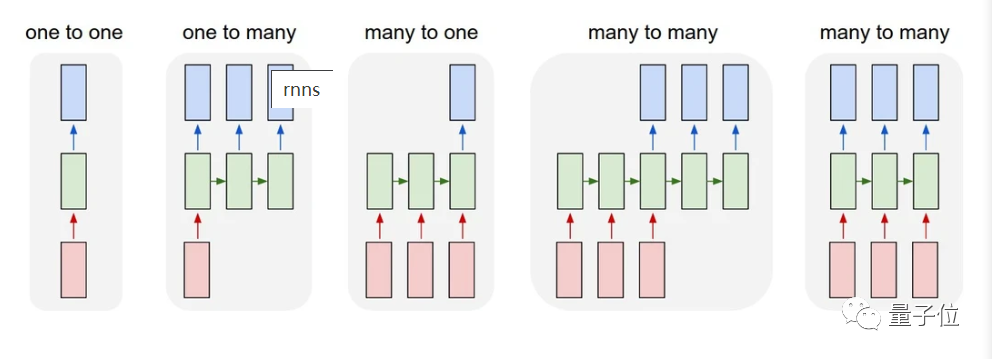
其中,输入是红色、RNN本身是绿色,输出为蓝色。
这种处理序列的能力十分有用,于是,RNN就有了丰富的应用场景。
比如,机器翻译。
像你见到的,某歌、某道、某度,还有最近很火的DeepL翻译器,它们都是“多对多”进行的。
原始文本序列被馈送到RNN,然后RNN生成翻译后的文本作为输出。
再比如,情绪分析。
通常使用的是“多对一”的RNN进行。将想要分析的文本输入到RNN中,然后产生一个单一的输出分类。
举个例子:分析一个评论是正面还是负面的评论。
输出得出:这是一个肯定的评论。
怎样实现RNN?
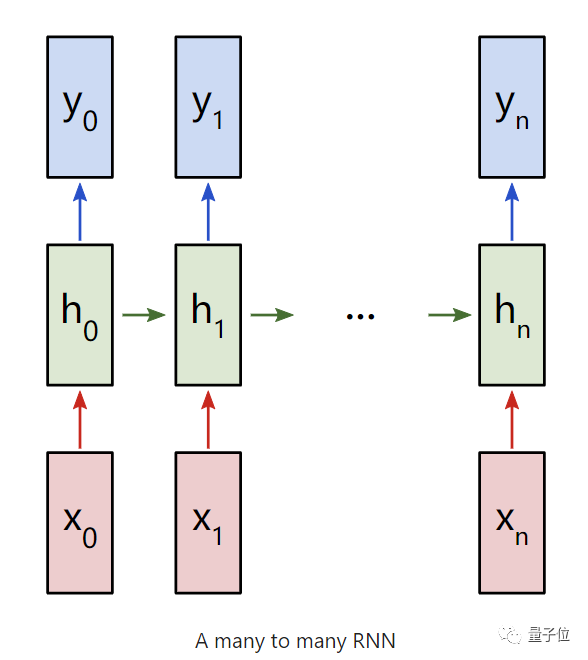
我们就先来考虑一下,“多对多的RNN,输入为x0、x1、x2……xn,输出为y0、y1、y2……yn,这些xi,yi都是向量,具有任意维度。
RNNs的工作原理是迭代更新一个隐藏状态h,它是一可以有任意维度的向量。
而对于任意的一个ht:
1、由对应的输入xt与上一个隐藏层ht-1来计算
2、输出yt是由ht计算出的结果。
这样,前一次的输出结果,就会带到下一次的隐藏层中,跟着一起训练。这样看,是不是就感受到了循环二字了。
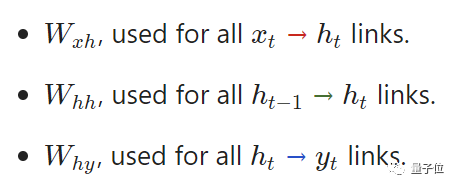
此外,还需要两个偏差。

由此,这3个权重跟2个偏差,就完成了整个RNN的计算。
将他们组合起来,方程式是这样的。
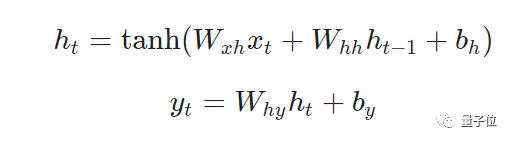
需要注意的是,这里的权重是矩阵,而其他变量是向量哦!
这里的第一个方程式,激活函数采用的是双曲线函数,当然用之前提到的S型函数也是OK的。
文本是肯定还是否定?
接着,我们就来试着从头开始执行RNN吧。
以一个简单的情感分析为例,就是判断一串给定的文本字符串是肯定的表达还是否定的。
比如,这些数据集。
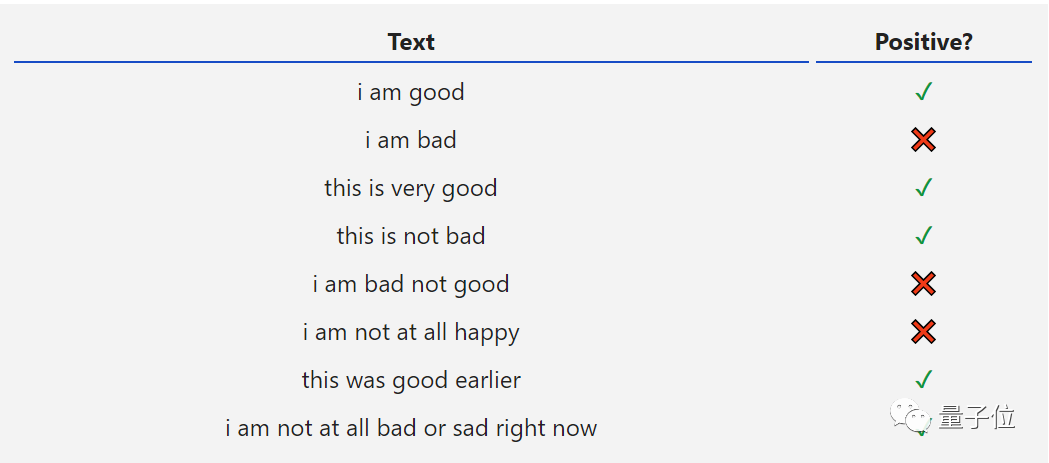
从这个表格看出,我们将使用“多对一”的RNN类型。
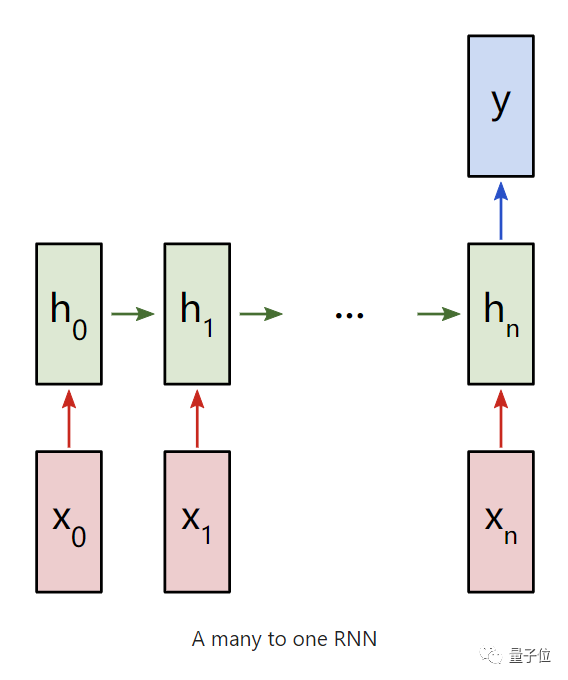
每个输入x都将是一个向量,代表文本中的一个单词。
而输出y则是一个包含两个数字的向量,一个代表正数,一个代表负数,然后应用Softmax将这些值转化为概率,并最终得出正负。
预处理
首先,我们要先进行一些预处理——将数据集转化为可用的格式。因为RNN暂且还不能识别单词,所以,我们需要构建一个所有单词的词汇表,并给它编号。
在词汇表中,有18个单词,那就意味着每一个单词是一个x,那么输入就是一个18维的向量。
训练RNN
接下来,就是按照原始RNN所需的3个权重,与2个偏差开始。
就是我们前面见过的公式。
就像此前训练CNN一样,训练RNN,首先需要一个损失函数。
此次将使用交叉熵损失与Softmax联合计算:
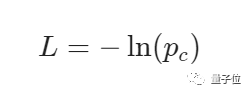
(其中c表示某个文本标签,比如 correct)
举个例子,如果一个肯定文本测试显示有90%的概率是肯定的,那么它的损失函数是:
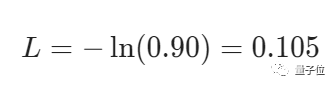
计算了损失函数以后,就要利用梯度下降的训练来减小损失。
接下来,就涉及到多变量演算,计算思路跟之前的一样,只是具体计算公式有所不同。详情就戳下方链接。
训练之后,别忘了,还需要进行一番测试哦~
好了,今天有关RNN介绍,就到这里了。
传送门
https://victorzhou.com/blog/intro-to-rnns/







