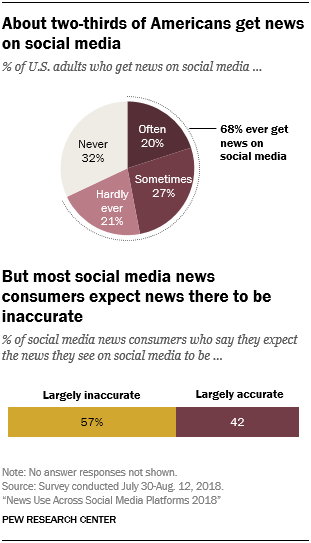
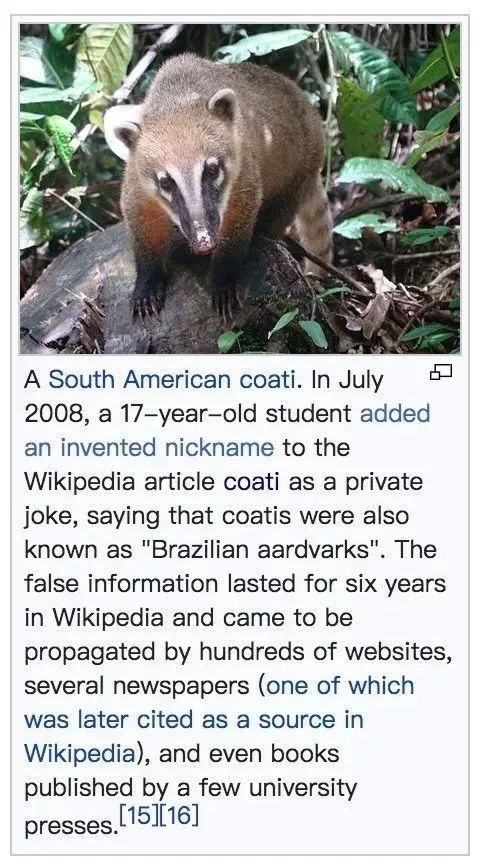
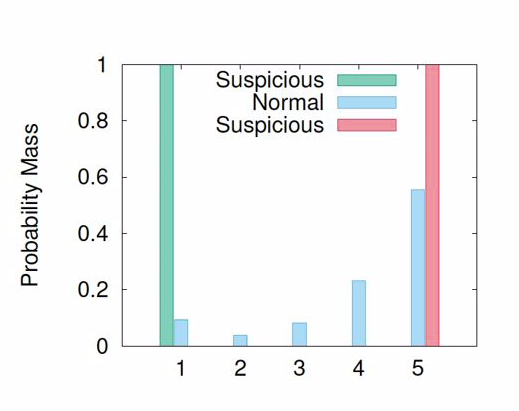
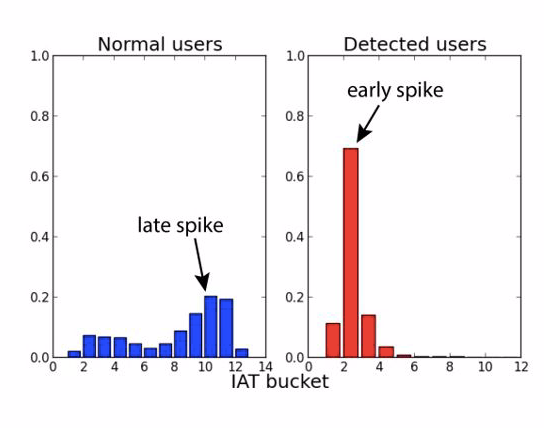
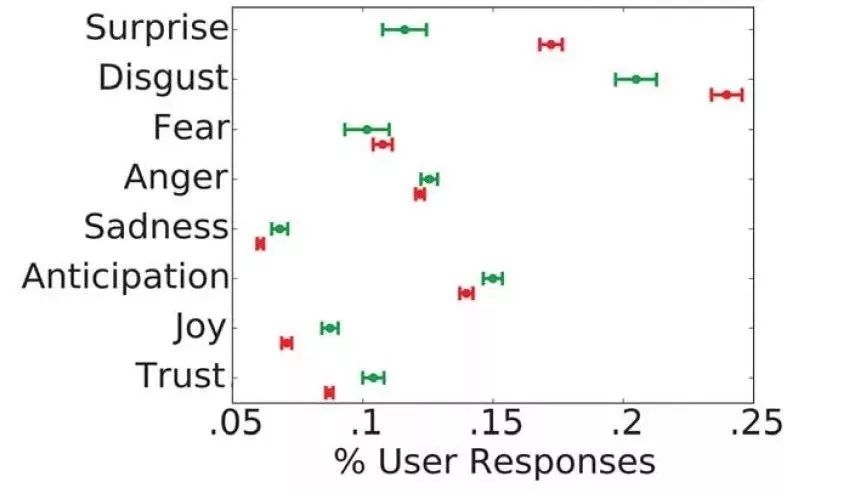
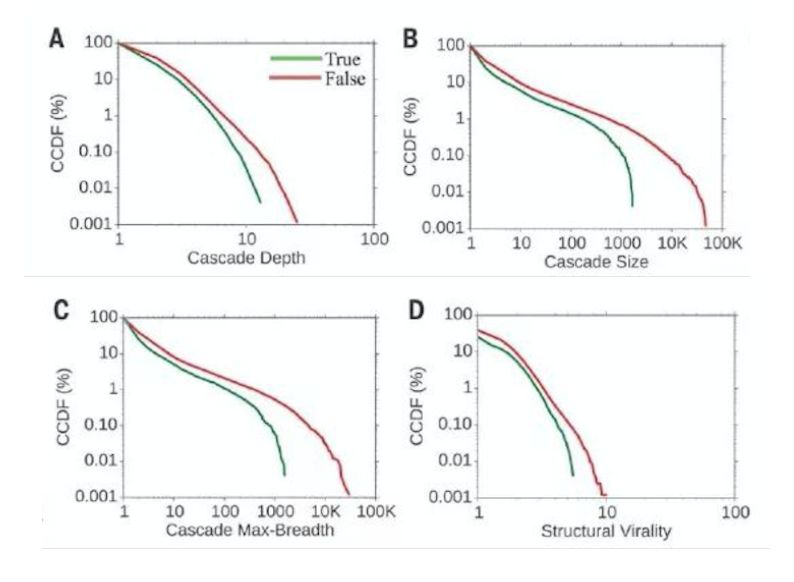
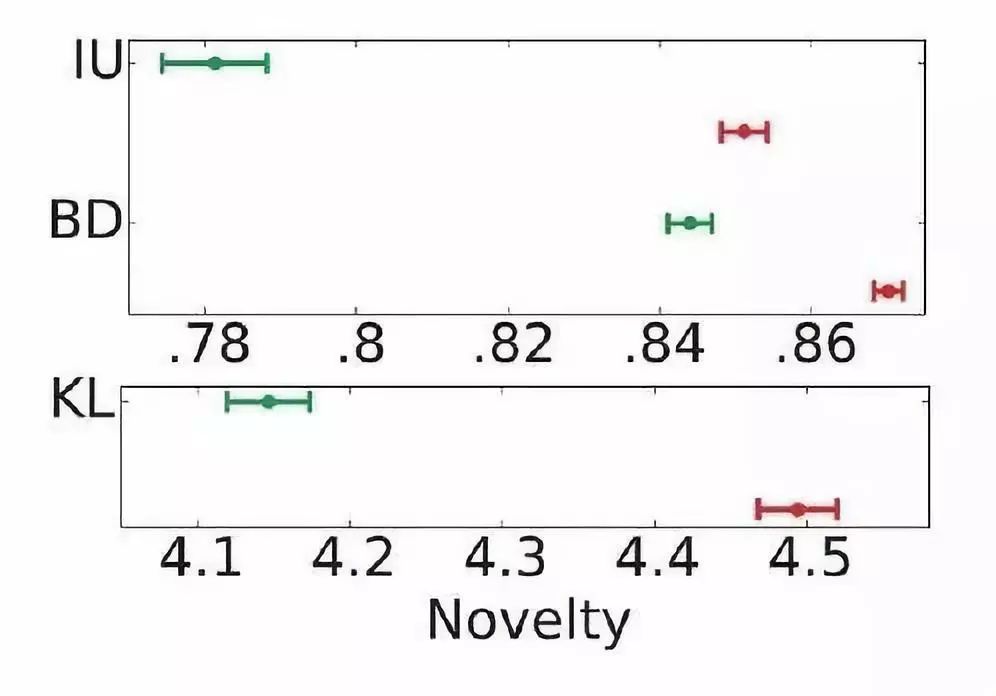
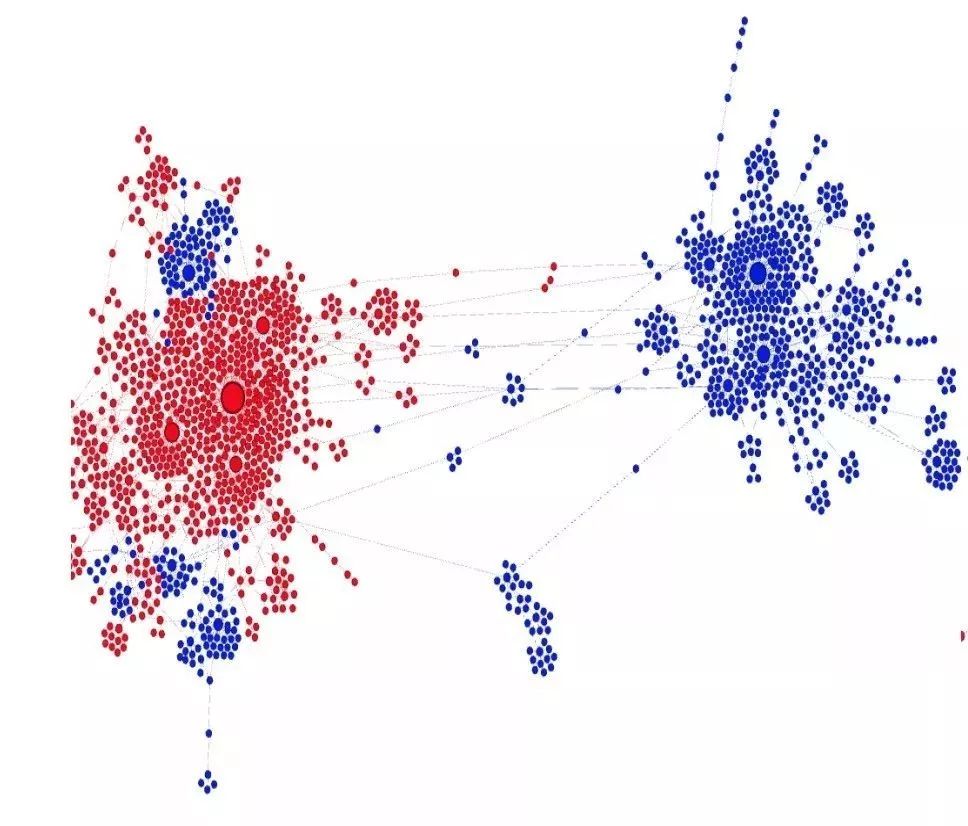
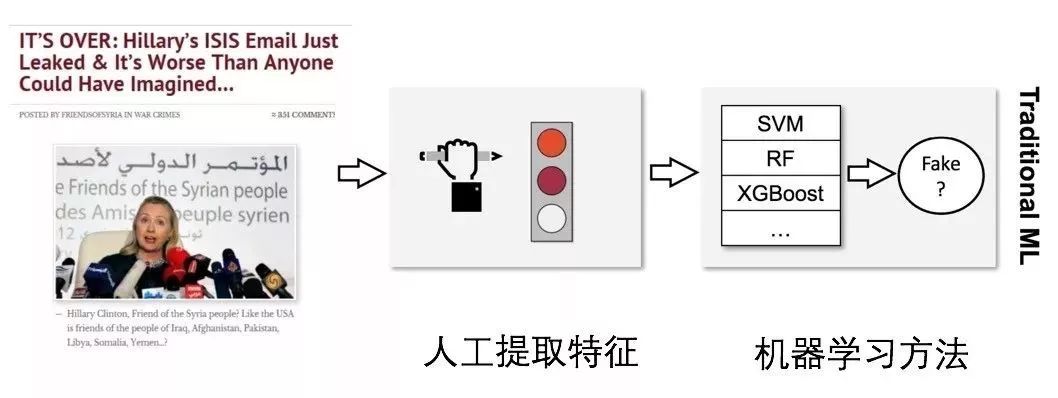
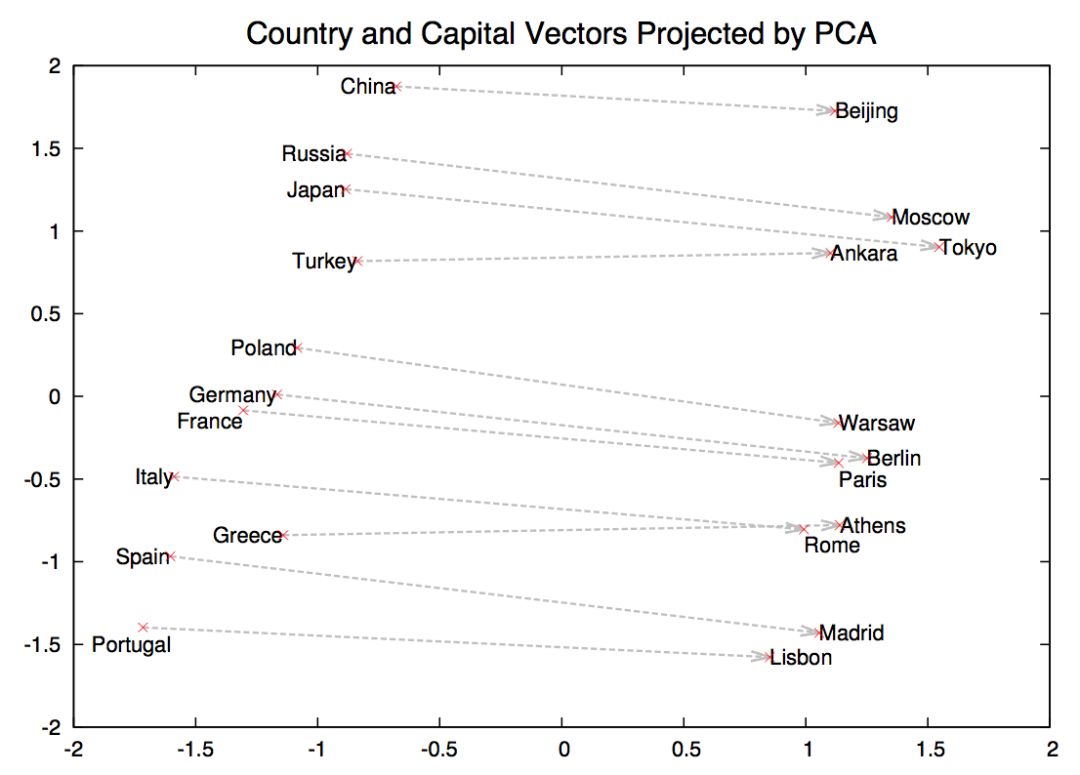
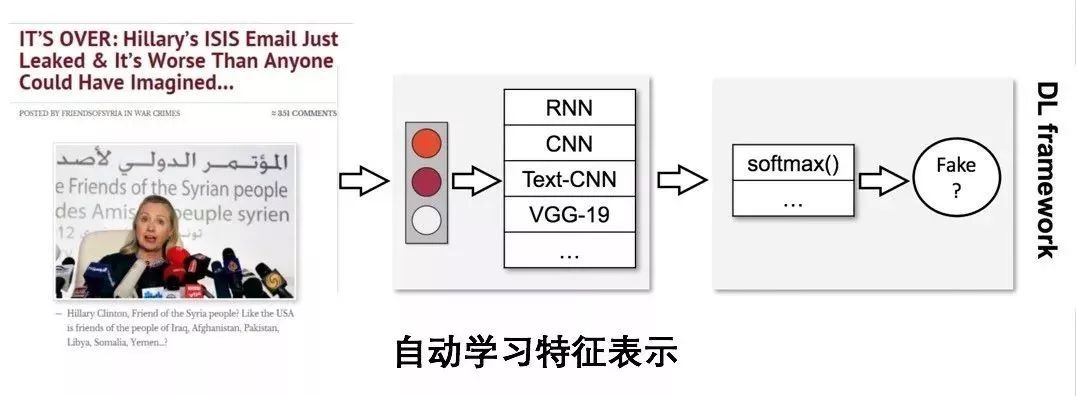
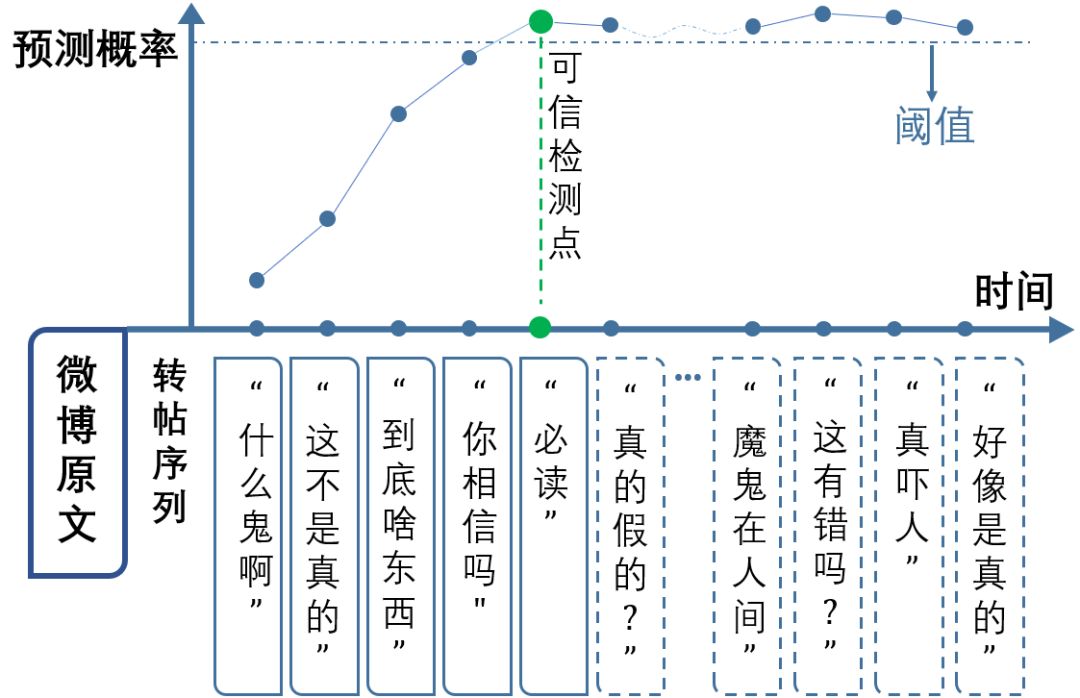
[1] Elisa Shearer, Katerina Eva Matsa. News Use Across Social Media Platforms 2018. Pew Research Center.2018.[2] Craig Silverman. This analysis shows how viral fake election news stories outperformed real news on Facebook. Buzzfeed News. 2016.[3] “Word of the Year 2016 is...” Oxford Dictionaries. 2016.[4] Kumar, Srijan, and Neil Shah. "False information on Web and social media: A survey." arXiv preprint arXiv:1804.08559 (2018).[5] Shah, Neil, et al. “Edgecentric: Anomaly detection in edge-attributed networks.” 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW). IEEE, 2016.[6] Hooi, Bryan, et al. “Birdnest: Bayesian inference for ratings-fraud detection.” Proceedings of the 2016 SIAM International Conference on Data Mining. Society for Industrial and Applied Mathematics, 2016.[7] Vosoughi, Soroush, Deb Roy, and Sinan Aral. “The spread of true and false news online.” Science 359.6380 (2018): 1146-1151.[8] Kumar, Srijan, Robert West, and Jure Leskovec. “Disinformation on the web: Impact, characteristics, and detection of wikipedia hoaxes.” Proceedings of the 25th international conference on World Wide Web. International World Wide Web Conferences Steering Committee, 2016.[9] Garimella, Kiran, et al. "Balancing opposing views to reduce controversy." arXiv preprint arXiv:1611.00172 (2016): 4.[10] Kumar, Srijan, Robert West, and Jure Leskovec. “Disinformation on the web: Impact, characteristics, and detection of wikipedia hoaxes.” Proceedings of the 25th international conference on World Wide Web. International World Wide Web Conferences Steering Committee, 2016.[11] Jindal, Nitin, and Bing Liu. “Opinion spam and analysis.” Proceedings of the 2008 international conference on web search and data mining. ACM, 2008.[12] Kumar, Srijan, et al. “FairJudge: Trustworthy user prediction in rating platforms.” arXiv preprint arXiv:1703.10545 (2017).[13] Mikolov, Tomas, et al. “Distributed representations of words and phrases and their compositionality.” Advances in neural information processing systems. 2013.[14] Karimi, Hamid, and Jiliang Tang. “Learning Hierarchical Discourse-level Structure for Fake News Detection.” arXiv preprint arXiv:1903.07389 (2019).[15] Song, Changhe, et al. “CED: Credible Early Detection of Social Media Rumors.” arXiv preprint arXiv:1811.04175 (2018).[16] Shu, Kai, Suhang Wang, and Huan Liu. “Beyond news contents: The role of social context for fake news detection.” Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining. ACM, 2019.[17] Fake News: Fundamental Theories, Detection Strategies and Challenges, Xinyi Zhou, Reza Zafarani, Kai Shu and Huan Liu, WSDM, 2019.[18] 刘知远, 宋长河, 杨成. 社交媒体平台谣言的早期自动检测. 全球传媒学刊 5.4 (2018): 65-80. 英文技术版:Changhe Song, Cunchao Tu, Cheng Yang, Zhiyuan Liu, Maosong Sun. CED: Credible Early Detection of Social Media Rumors. arXiv preprint arXiv:1811.04175. 原文链接:https://zhuanlan.zhihu.com/p/94768011