点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达![]()
作者:Liqian Ma、Zhe Lin等
本文转载自:机器之心 | 编辑:蛋酱、张倩、杜伟
自拍也能变为他拍,魔幻修图界又出新招式,但效果实在感人。
智能手机的出现,让摄影变成了一项大众艺术,也让越来越多的人爱上「自拍」。但自拍照常常存在构图问题,比如不自然的肩膀姿势、占据一小半镜头的手臂,或者极其诡异的视角。
![]()
要想解决这个问题,可以选择随身携带三脚架或自拍杆,也可以选择随身携带一个朋友作为摄影师(该方法对单身狗极其不友好)。
或者,你还可以选择相信后期修图的艺术。近日,
来自 Adobe 研究院、UC 伯克利、鲁汶大学的研究者开发了一种「自拍」变「他拍」的新技术,通过识别目标的姿势并生成身体的纹理,在给定的自拍背景中完善和合成人物
。
![]()
在这篇论文中,研究者提出了一种叫做 「
Unselfie(非自拍)」的图片转换方法,能够将自拍照中的人物,转变为手臂、肩膀、躯干都比较放松舒展的“他拍图像”。
它会把所有举起的手臂调整为向下,然后调整服装细节,最后填充好所有暴露出来的背景区域。
![]()
论文链接:https://arxiv.org/pdf/2007.15068.pdf
除了用来修饰社交媒体上的自拍照,这项技术还有很多应用方式,如果你急需一张证件照,而无人能帮你拍摄,那这项技术就能派上用场。
![]()
当然,这个方法目前还不太成熟,除了效果一般之外,偶尔还有翻车的时候,比如生成这样的图像:
![]()
没有成对的训练数据(自拍 - 他拍图像对);
一个自拍姿势可能对应多个他拍姿势;
改变姿势会在背景中留下空洞,因此在转换过程中要填补这些空洞。
研究者尝试用之前的几种方法来解决挑战,但实验结果表明,这些方法会产生明显的伪影,其纹理细节也会由于外观信息的高度压缩而丢失。
因此,他们提出
借助合成「自拍 - 他拍」图像对和自监督学习的方法来解决上述问题
。
具体来说,研究者提出了一种利用他拍图像合成对应自拍图像的方法,他们利用非参数化最近姿态搜索模块来检索最接近给定他拍图像的自拍图像,然后合成对应的自拍照。他们还在推理过程中应用了一个最近姿态搜索模块。给定一个自拍姿态输入,模型会检索出与之匹配度最高的他拍姿态,然后利用这个姿态来合成最后的他拍效果。合成的输出的结果不止一个,用户可以从中选择,这就解决了上面提到的挑战 2。
利用上述步骤合成的成对数据可以直接用来训练一个有监督的人像生成网络,但实验结果显示,明显的伪影问题依然没有解决。之前的各种方法对于合成的成对训练数据与真实自拍测试数据之间的像素级 domain gap 非常敏感(如下图 3 所示)。
![]()
受到 CVPR 2019 论文《Coordinate-based texture inpainting for pose-guided image generation》的启发,研究者使用基于坐标的修补方法在 UV 空间中修补身体纹理,空间中大部分是不变的原始身体姿态,因此在面临合成数据的瑕疵时更具鲁棒性。此外,基于坐标的修补方法可以重新利用可见像素,从而获得更清晰的结果。
为了应对挑战 3,研究者使用了一个基于合成网络的门控卷积层来完善身体外观和填补背景空白,并保持人体与背景之间的平滑过渡。
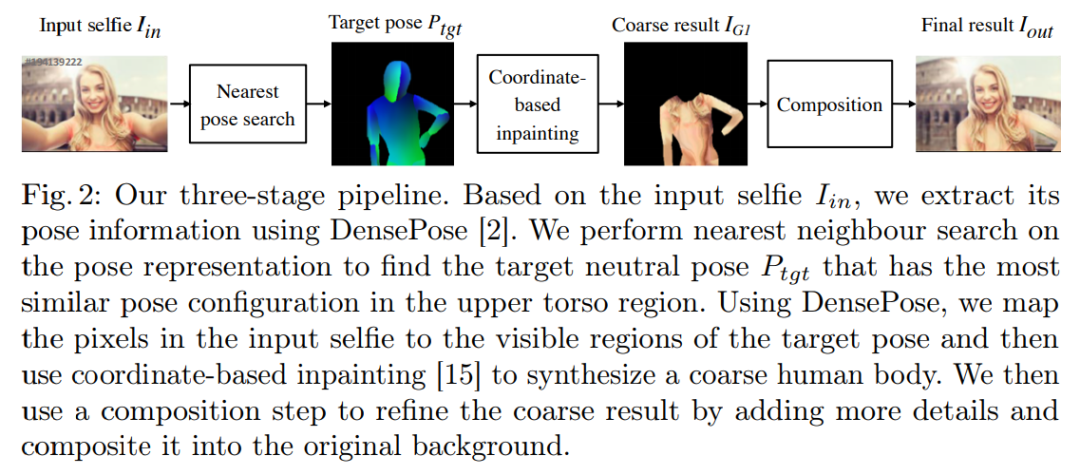
总的来说,为了解决「unselfie」任务,研究者提出了下图所示的
三段式 pipeline
:
首先在数据库中搜索最相近的他拍姿势,然后执行基于坐标的身体纹理修补,最后使用合成模块来细化结果,并在背景上合成它们。
![]()
研究者在定性评估、用户研究和定量评估三方面将他们提出的方法与以往类似方法进行了比较。
下图 7 表明,与之前的 DPIG 和 PATN 方法相比,Unselfie 方法生成了更逼真的人体姿势和背景。
![]()
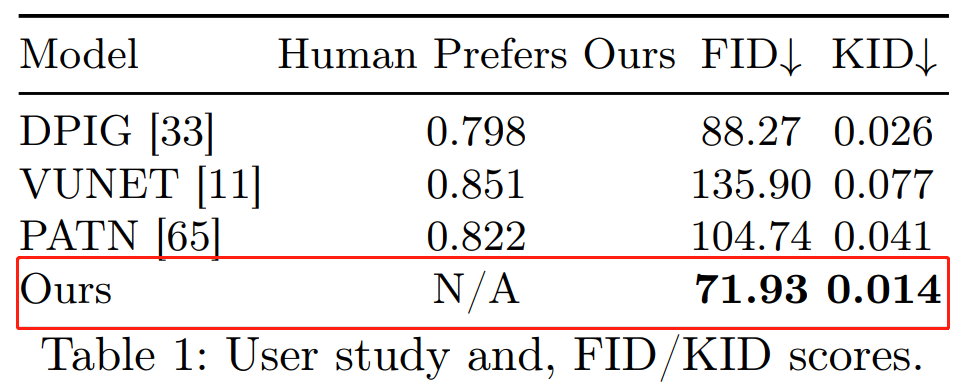
研究者在 Amazon Mechanical Turk (AMT)上对该方法以及 DPIG、VUNET 和 PATN 方法进行了用户研究。结果显示,该方法优于其他方法(如下表 1 所示)。
![]()
由于没有对应自拍照的 ground truth 他拍照,因而不能使用 SSIM 之类的指标。所以,为了定量比较该方法与其他基准方法的成像结果,研究者使用了 FID 和 KID 两项指标。结果显示,定量比较中的 FID 和 KID 结果与用户研究保持一致,该方法显著优于其他方法。
首先,如下图 10(左)所示,对于具有挑战性的自拍姿势或角度来说,最近姿态搜索模块可能难以找到与之匹配的他拍姿态,这导致合成图像中的手臂或肩膀相较于头部区域过细或过宽。
这一问题在 top-1 结果中出现的比例少于 10%,并且用户通常可以从 top-5 结果中找到良好的兼容姿势。
![]()
此外,图 10 示例也暴露出了背景合成的局限。不过,针对此问题,研究者在下图 11 中也展示了利用已有模型对图像背景进行修复的示例,从而证明了在大规模数据集上训练的图像修复模型的好处。
![]()
最后,系统在 DensePose 检测中容易出错。如上图 10(右)所示,DensePose 没有检测到她的手臂在前方。所以,合成模块在结果中依然保留了她的手臂。
下载1
在CVer公众号后台回复:OpenCV书籍,即可下载《Learning OpenCV 3》书籍和源代码。注:这本书是由OpenCV发起者所写,是官方认可的书籍。其中涵盖大量图像处理的基础知识介绍,虽然API还是基于OpenCV 3.x,但结合此书和最新API,可以很好的学习OpenCV。
![]()
下载2
在CVer公众号后台回复:CVPR2020,即可下载CVPR2020 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2000+人,旨在交流顶会(CVPR/ICCV/ECCV/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI等)、SCI、EI等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
![]()
▲长按加微信群
![]()
▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!![]()