如何训练你的准确率?

©PaperWeekly 原创 · 作者 | 苏剑林
单位 | 追一科技
研究方向 | NLP、神经网络
最近 arXiv 上的一篇论文《EXACT: How to Train Your Accuracy》[1] 引起了笔者的兴趣,顾名思义这是介绍如何直接以准确率为训练目标来训练模型的。正好笔者之前也对此有过一些分析,如《函数光滑化杂谈:不可导函数的可导逼近》[2]、《再谈类别不平衡问题:调节权重与魔改 Loss 的对比联系》等, 所以带着之前的研究经验很快完成了论文的阅读,写下了这篇总结,并附上了最近关于这个主题的一些新思考。

失实的例子
看上去是一个很简明漂亮的例子,但笔者认为它是不符合事实的。其中,最大的问题是模型设置温度参数,即一般出现的模型是 而不是 ,刻意去掉温度参数来构造不符合事实的反例是没有说服力的,事实上补上可调的温度参数后,这两个损失都可以学到正确的答案。更不公平的是,后面作者在提出自己的方案 EXACT 时,是自带温度参数的,并且温度参数是关键一环,换句话说,在这个例子中,EXACT 比其他两个损失好,纯粹是因为 EXACT 有温度参数。

然后我们来看论文所提出的方案——EXACT(EXpected ACcuracy opTimization)。从事后来看,EXACT 很是莫名其妙,因为作者是直接不加任何解释地从重参数的角度重新定义了一个条件概率分布 :
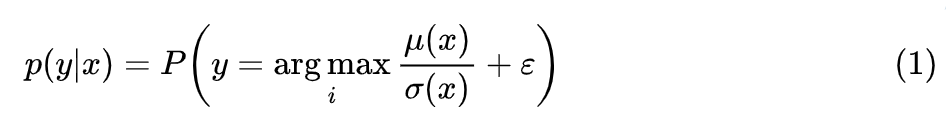
其中 是一个向量网络, 是一个标量网络, 跟 维度相同,每个分量是独立同分布地从 采样得到。关于用重参数来定义概率分布的做法,我们在上一篇文章《从重参数的角度看离散概率分布的构建》已经讨论过,这里不重复。
紧接着,有了这个新的 ,作者直接以

作为损失函数,全文的理论框架基本上到此结束。
由此,我们可以总结 EXACT 的莫名其妙之处了。在《从重参数的角度看离散概率分布的构建》我们知道,从重参数角度来看,Softmax 对应的噪声分布是 Gumbel 分布,而 EXACT 换成了正态分布,那么好在哪?为什么会好?这些全无解释。
此外,式 (2) 的相反数是准确率的光滑近似,这本已“广为人知”,但同时也有一个广为人知的结论是在 Softmax 情况下直接优化式 (2) 的效果通常都是不如优化交叉熵的,现在只是换了一个“新瓶”(新概率分布的构建方法)装“旧酒”(同样的准确率光滑近似),真的就能有提升吗?

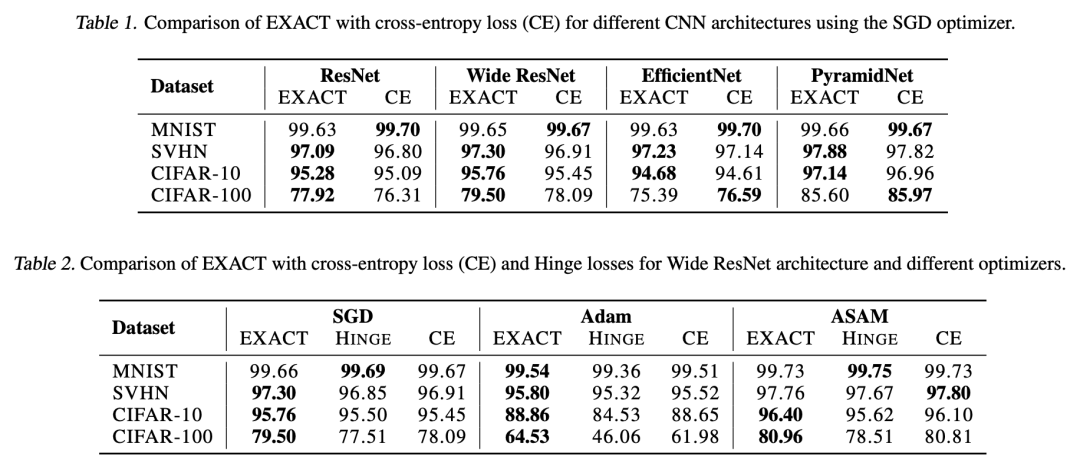
原论文给出了非常惊人的实验结果,显示 EXACT 几乎总是 SOTA:

一个新视角
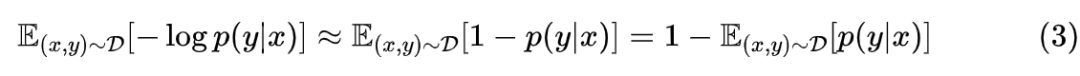
于是我们就能解释为什么优化交叉熵也能获得很好的准确率了,因为从上式我们可以发现,交叉熵优化到中后期跟式 (2) 基本是等价的,也就是同样在优化准确率的光滑近似!
由此,我们可以得到一个优秀的损失函数的新视角:
首先寻找评测指标的一个光滑近似,最好能表达成每个样本的期望形式,然后将错误方向的误差逐渐拉到无穷大(保证模型能更关注错误样本),但同时在正确方向保证与原始形式是一阶近似。


参考文献
[2] https://kexue.fm/archives/6620
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧



