Elasticsearch地理信息存储及查询之Geo_Point

导读
Elasticsearch提供了丰富的搜索和分析功能,地理位置功能可以让我们把基于地理位置的搜索、聚合、计算与全文搜索、结构化搜索和分析结合到一起。在这里易观的技术小哥哥,就跟大家做一个交流和探讨。
▌基本概念
1. GeoHash
GeoHash是一种将经纬度坐标(lat/lon)编码成字符串的方式,通过牺牲一定的精度,来获得高效的检索性能。
其原理是,将平面预先划分成多级矩形区域,在按照从大矩形到小矩形的顺序,将位置信息依次编码成二进制码,最后按照一定编码方式,转换成字符串。如:
比如这样一个点(39.923201, 116.390705) ,我们以纬度为例:
纬度的范围是(-90,90),其中间值为0。对于纬度39.923201,在区间(0,90)中,因此得到一个1;(0,90)区间的中间值为45度,纬度39.923201小于45,因此得到一个0,依次计算下去,即可得到纬度的二进制表示,如下表:
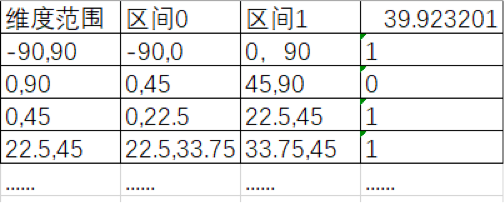
最后得到纬度的二进制表示为:
10111000110001111001
同理可以得到经度116.390705的二进制表示为:
11010010110001000100
合并纬度、经度的二进制:
合并方法是将经度、纬度二进制按照奇偶位合并:
11100 11101 00100 01111 00000 01101 01011 00001
按照Base32进行编码:
将上述合并后二进制编码后结果为:
wx4g0ec1
GeoHash的特点:
精度越高,字符串越长,
前缀匹配度越高,距离越近。
2. geo_point
地理坐标点,在Elasticsearch中用来存经纬度数据的一种数据格式。
3. geo_shape
地理形状,Elasticsearch中用于存储复杂形状的一种数据格式,可以用来存储,点集、线、多边形、多边形集等多种集合形状。Geo-shapes 不能用于计算距离、排序、打分以及聚合。
使用geo_shope时,可以指定precision(精度)和距离误差。
本文将重点介绍geo_point相关功能,在以后的文章中,将会进一步介绍geo_shape。
▌geo_point存储及查询
1. geo_point存储
geo_point是Elasticsearch中用于存储坐标点的数据格式,每一个坐标点都有经度和维度信息,geo_point格式的字段无法做自动映射,需要指定数据类型:
{
"dynamic": "false",
"properties": {
"id": {
"type": "keyword"
},
"location": {
"type": "geo_point",
"ignore_malformed": true
}
}
}
对于geo_point这种数据格式,Elasticsearch提供了三种不同的索引和展现形式:
假设经度:127.25456,纬度:25.236
(1)对象:
{
"location": {
"lon": 127.25456,
"lat": 25.236
},
"id": "10001"
}
(2)数组:
{
"location": [
127.25456,
25.236
],
"id": "10001"
}
(3)字符串
{
"location": "25.236,127.25456",
"id": "10001"
}
注意:
使用字符串存储时,顺序是“纬度,经度”,使用数组存储时,顺序是“经度,纬度”。
2.查询
geo_point支持geo_bounding_box、geo_distance、geo_polygon查询
(1)geo_bounding_box查询
地理坐标盒模型:输入左上角和右下角坐标,即检索在地图上指定的矩形范围内的所有点。
geo_bounding_box是一种极其简单的查询方式,即使不使用geo_point,我们直接使用double类型存储经度和纬度数据,使用range查询一样可以实现这个功能。如果是多值,我们需要使用nested_object类型来实现。
geo_bounding_box默认使用内存过滤,这样需要一条一条计算,这是一种比较低效的查询方式,我们可以指定使用“indexed”方式,这样能够利用倒排索引实现高效检索,但是必须使用对象方式存储数据,但是,这种方式只有对单值存储有效。
(2)geo_distance查询
简而言之,这种查询,就是指定圆心和半径,圈出圆内的点。Elasticsearch执行过程,是先使用圆的外切正方形快速筛选出点,在判断正方形内的每个点与圆心的距离,由此可见如果能使用倒排索引的range查询同样可以提高查询效率,所以,在设计索引和数据格式的时候,使用单值、对象方式存储经纬度数据,是比较理想的。
计算距离时,Elasticsearch提供了两种计算方式:ark、plane。
ark方式,将地球当做球体来处理,精确度高,但计算较慢,这是默认的计算方式;
plane方式,将地球当做平面来处理,精确度略低,但计算较快。
在锆云项目中,我们使用plane计算方式,在大多数应用场景中,几米的误差,完全可以忽略不计。
(3)geo_polygon 查询
输入多个坐标构成的不规则多边形,筛选出这个多边形中的点,这是一种性能极低检索方式,无法使用倒排索引提高查询性能。
3.聚合
(1)geo_distance聚合
基于geo_point的多桶聚合,类似于range聚合,指定点以及距离分段,由此得到,到点不同距离内的点的数量
POST /museums/_search?size=0
{
"aggs" : {
"rings_around_amsterdam" : {
"geo_distance" : {
"field" : "location",
"origin" : "52.3760, 4.894",
"ranges" : [
{ "to" : 100000 },
{ "from" : 100000, "to" : 300000 },
{ "from" : 300000 }
]
}
}
}
}
同样,距离计算选ark,plane两种方式。
(2)geohash_grid聚合
我们知道,geohash的每一个值代表一个方格,geohash_grid聚合是指,将地图上的点,按照指定的精度,划分到各个方格中去,并返回各方格中点的个数,GeoHash的特点,对于这种“方格聚合”能够提供很好的支持,自然,精度越高,性能越差,所以,使用geohash_grid聚合,需要高精度的时候,尽量缩小数据集,在聚合之前使用filter过滤数据集。
(3)geo_bounds聚合
geo_bounds聚合可以快速找出能够包含所选点集的最小矩形,使用max ,min同样可以实现该操作。
(4)centroid聚合
中心点聚合,找出离散点集和的中心点。单独使用中心点聚合的场景并不多,多余geohash_grid聚合联合使用,以计算出每个区域中的中心点,对于从无规则离散点中提取有效坐标非常有效。
点击文末“阅读原文” 即刻体验易观方舟!
戳“阅读原文”,即刻体验易观方舟!



