【泡泡点云时空】SqueezeSegV2:改进模型结构和无监督领域自适应的激光雷达点云道路目标分割方法
泡泡点云时空,带你精读点云领域顶级会议文章
标题:SqueezeSegV2: Improved Model Structure and Unsupervised DomainAdaptation for Road-Object Segmentation from a LiDAR Point Cloud
作者:Bichen Wu∗, Xuanyu Zhou∗, Sicheng Zhao∗, Xiangyu Yue, Kurt Keutzer
来源:ICRA2019
编译:陈贝章
审核:Lionheart
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

早期的工作阐述了基于深度学习的点云分割的方法; 但是,这些方法仍需要改进才能使用。为此,我们引入了一个新模型SqueezeSegV2,它对于激光雷达点云中的噪声去除更具鲁棒性。通过改进的模型结构,训练损失函数,批量归一化和增加输入通道,SqueezeSegV2在实际数据训练中表现出显着的精度提升。用于点云分割的训练模型需要大量标注的点云数据,而获取带标注的点云数据又是一件耗时费力的工作。为了减少采集和标注数据的成本,可以使用如GTA-V(游戏:侠盗飞车5)之类的模拟器来创建大量的标注虚拟数据。然而由于领域漂移问题,在模拟数据上训练的模型通常不能很好地表现现实世界。我们用领域自适应的训练方法来解决这个问题,其中该方法由三个主要部分组成:1)学习激光强度补偿量,2)最短距离线相关校准,3)渐进域校准。在对真实数据进行训练时,我们的新模型比原始SqueezeSeg显示的分割精度提高了6.0-8.6%。当在模拟数据上使用提出的区域自适应方法训练我们的新模型时,我们几乎将实际数据的测试精度从29.0%提高到57.4%。我们将开源的源代码和模拟数据集。
主要贡献
近年来不少基于深度学习的点云目标检测方法被提出,本文介绍的SqueezeSegV2是在SqueezeSeg基础上提出的改进方案,这类方法使用深度神经网络提取点云特征,以接近于端到端的处理流程实现点云中的目标检测,本文的主要贡献如下:
1)利用CAM(Context Aggregation Module:上下文聚合模块) 改进了SqueezeSeg的模型结构,以提高其对丢失噪声的鲁棒性,从而使不同类别的精度提高6.0%至8.6%。我们将新模型命名为SqueezeSegV2。
2)提出了一个领域自适应训练方法,它可以显着减少模拟数据和实际数据之间差距的分布。对模拟数据进行训练的模型在实际测试数据上的准确度提高了28.4%。
3)创建了一个大规模的3D LiDAR点云数据集:GTA-LiDAR,它由100,000个模拟点云样本组成,增强了激光雷达反射强度的补偿。源代码和数据集将是开源的。

图1.领域漂移的示例。点云被投射到球面坐标上以进行可视化(车辆为红色,行人为蓝色)。我们的领域自适应方法在模拟数据上训练的同时提升了车辆的分割精度。
SqueezeSegV2网络结构
SqueezeSegV2使用的是CNN(卷积神经网络)+CRF(Conditional Random Field,条件随机场)这样的结构。其中,CNN采用的是Forrest提出的SqueezeNet网络,该网络使用远少于AlexNet的参数数量便达到了等同于AlexNet的精度,极少的参数意味着更快的运算速度和更小的内存消耗,这是符合车载场景需求的。SqueezeSegV2的CNN部分几乎完全采用SqueezeSe一样的的网络结构,其网络结构如下:

图2.用于3D LiDAR点云的道路-目标分割SqueezeSegV2模型的网络结构。
该网络最大的特色为两个结构,被称为 fireModules 和 fireDeconvs,这两种网络层的具体结构如下:
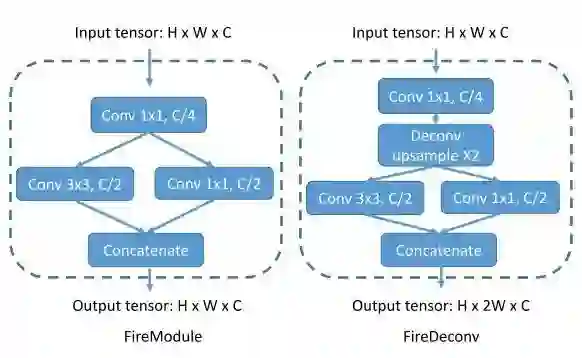
由于输入的张量的高度小于其宽度,该网络主要对宽度进行降维,通过添加最大池化层(Max Pooling)降低数据的宽度。到FireModule9输出的是降维后的特征映射。为了得到一个完整的映射标签,还需要对特征映射进行还原(即还原到原尺寸),conv14层的输出即对每个点的分类概率映射。输出最后被输入到一个条件随机场中进行进一步的矫正。
参考论文:SqueezeSeg: Convolutional Neural Nets with Recurrent CRF for Real-Time Road-Object Segmentation from 3D LiDAR Point Cloud, https://arxiv.org/pdf/1710.07368.pdf
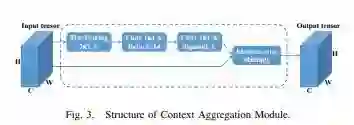
图3.上CAM下文聚合模块的结构。
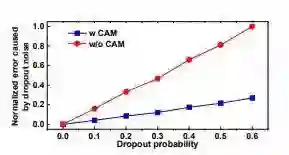
图4.我们将一个随机张量馈送到卷积滤波器,一个在3×3卷积滤波器之前使用CAM,另一个在没有CAM的情况下。我们随机地将输出噪声添加到输入,并测量输出误差。随着我们增加丢失概率,误差也会增加。对于所有丢失概率,添加CAM可提高对丢失噪声的鲁棒性,因此误差始终较小。
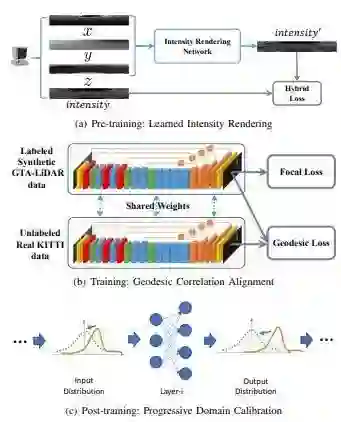
图5.从模拟的GTA-LiDAR数据集到现实世界KITTI数据集的道路-目标分割的所提出的无监督域自适应方法的框架。

图6 模拟数据中的激光强度补偿VS KITTI数据集中的地面真实强度

图7. SqueezeSeg 和我们的SqueezeSegV2(红色:汽车,绿色:骑车人)之间的分割结果比较。请注意,在第一行中,SqueezeSegV2为骑车人产生更准确的分割结果。在第二行中,SqueezeSegV2避免了一个错误检测到的远处的汽车

图8.领域自适应前后的分割结果比较(红色:汽车,蓝色:行人)
实验结果与结论
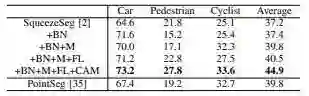
表I.分段性能(IOU,%)本文提出的SQUEEZESEGV2(+ BN + M + FL + CAM)模型和KITTI数据库中最先进的目标检测算法标杆PointSeg进行对比。

表II. 从GTA-LIDAR(模拟数据集)到KITTI(真实数据集)的无监督领域自适应方法的分段性能(IOU,%)。SQSG表示SqueezeSeg。+ LIR表示使用学习强度渲染。+ GCA表示使用相关对齐。+ PDC表示使用渐进域校准。+ CAM表示使用语义上下文模块。
SqueezeSegV2具有比原始SqueezeSeg更好的分割性能以及具有更强的无监督领域自适应方法。通过设计了一个上下文聚合模块(CAM)来减轻噪声丢失的影响。与其他改进(如焦点丢失,批量归一化和LiDAR掩模通道)相比,SqueezeSegV2在原始SqueezeSeg上的各种像素类别中的准确度提高了6.0%至8.6%。提出了一个具有三个组成部分的域自适方法:学习强度渲染,相关对齐和渐进域校准。使模拟数据集训练的网络在真实的测试集中有更高的准确度,甚至优于在真实数据集上训练的模型。

Abstract
Earlier work demonstrates the promise of deeplearning-based approaches for point cloud segmentation; however, these approaches need to be improved to be practicallyuseful. To this end, we introduce a new model SqueezeSegV2that is more robust to dropout noise in LiDAR point clouds.With improved model structure, training loss, batch normalization and additional input channel, SqueezeSegV2 achievessignificant accuracy improvement when trained on real data.Training models for point cloud segmentation requires largeamounts of labeled point-cloud data, which is expensive toobtain. To sidestep the cost of collection and annotation,simulators such as GTA-V can be used to create unlimitedamounts of labeled, synthetic data. However, due to domainshift, models trained on synthetic data often do not generalizewell to the real world. We address this problem with a domainadaptation training pipeline consisting of three major components: 1) learned intensity rendering, 2) geodesic correlationalignment, and 3) progressive domain calibration. When trainedon real data, our new model exhibits segmentation accuracyimprovements of 6.0-8.6% over the original SqueezeSeg. Whentraining our new model on synthetic data using the proposeddomain adaptation pipeline, we nearly double test accuracy onreal-world data, from 29.0% to 57.4%. Our source code andsynthetic dataset will be open-sourced.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com


