第一个GAN驱动的图像编辑框架!多伦多大学华人博士提出EditGAN,最注重细节的GAN模型
![]()
新智元报道

新智元报道
编辑:LRS
【新智元导读】如何能随心所欲改变图像一向是一个有挑战性的问题!以往借助GAN模型的图像编辑有这样那样的问题,英伟达的一个华人博士提出了一个新模型EditGAN,第一个GAN驱动的图像编辑框架,对out-of-domain图像的效果也很好!
图像编辑(image editing)是一个CV领域的一个重要研究问题,是指改变图像的过程,图像包括数码照片、传统的模拟照片和插图。
基于AI的照片和图像编辑也能够简化摄影师和内容创造者的工作流程,提升创意和数字艺术的水平。并且目前基于AI的图像编辑工具已经以照片编辑滤镜的形式添加到软件的功能中,并且深度学习研究界正在积极开发更多的技术。

一个常用的研究模型是使用生成对抗网络(GAN)或者将图像嵌入到GAN的隐空间。对GAN的隐向量(latent embedding)进行仔细修改后可以将其转换为预期变化的输出,例如,可以肖像中的面部表情发生一致变化,改变汽车的视角或形状和纹理,或以语义上有意义的方式在不同图像之间插值。
大部分基于GAN的图像编辑方法可以分为几类。有些工作依赖于GAN对类标签或像素级语义分割的标注,不同的条件能够导致输出的变化,还有一些工作使用辅助属性分类器来引导合成和编辑图像。

然而,训练这种有条件的GAN或外部分类器需要大量的标签数据。因此,这些方法目前仅限于具有大量标注数据的图像类型,例如肖像数据。
此外,即使标注可用,大多数技术也只提供有限的编辑控制,因为这些标注通常只包含高级别的全局属性或相对粗糙的像素级分隔。
另一条研究路线侧重于不同图像的混合和插值特征,因此需要参考图像作为编辑目标,通常也不能精细控制图像的生成。其他方法通过分析GAN的隐空间,找到适合编辑的未分类潜在变量,或控制GAN的网络参数,这些方法不允许详细编辑,而且速度很慢。
针对这些局限性,来自英伟达和多伦多大学的研究人员提出了一种新的基于GAN的图像编辑框架EditGAN,该框架允许用户修改细节对象部分,从而实现高精度的语义图像编辑。EditGan 的构建基于最近提出基于相同的隐向量联合建模两个图像及其语义分割的GAN模型,并且只需要16个标签示例就可以扩展到多个对象类和部分标签的选择。

根据所需的编辑修改分割遮罩,优化隐向量,使其与新的分割保持一致,从而有效地改变了RGB图像。为了达到更高的效率,模型学习了在隐空间中编辑向量来实现图像编辑,并且可以直接应用于其他图像,而不需要任何额外的优化步骤。
因此,可以预先建立一个所需的编辑库,用户可以直接在交互式工具中使用。
文章的第一作者Huan Ling是多伦多大学的博士生,NVIDIA和Vector研究所的研究科学家。

EditGAN 的图像生成组件是StyleGAN2,也目前是最先进的用于图像合成的GAN。StyleGAN2生成器从多元正态分布中提取的隐向量Z映射到真实图像中。首先利用非线性映射函数将隐向量转换成一个中间码,然后通过学习映射变换进一步转换成K+1向量。这些转换后的隐编码被输入到合成块中,合成块的输出是深度的特征映射。
为了训练分割分支的同时并对新图像进行分割,研究人员使用编码器和优化将图像嵌入GAN的隐空间中。在先前的工作的基础上构建了一个编码器,能够将图像嵌入W+空间。
训练编码器的目标函数由标准像素级L2和感知LPIPS重建损失组成,使用真实训练数据和GAN生成的样本进行计算。对于GAN样本,还使用已知的隐向量对编码器进行了显式规则化。在实际应用中,使用编码器初始化图像的隐空间embedding,然后通过优化迭代重构隐代码w+,再次使用标准的重构目标函数。
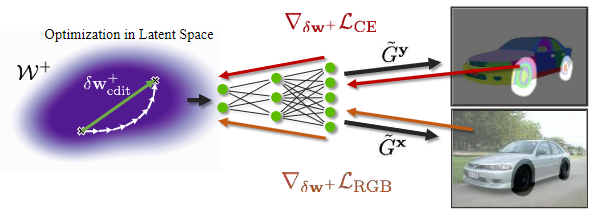
EditGAN的核心思想是利用图像的p(x,y)联合分布和语义分割进行高精度的图像编辑。给定要编辑的新图像X,可以将其嵌入到EditGAN的W+隐空间,或者也可以从模型本身采样并使用这些图像。
分割分支(segmentation branch)将生成相应的分割,因为分割和RGB图像共享相同的隐W+编码。使用简单的交互式数字绘画或标签工具就可以根据需要的编辑手动修改分割。
通过上述优化得到的隐空间编辑向量具有语义,但是常与其它属性相混淆。因此,对于要编辑的新图像,可以把图像嵌入到隐空间,然后通过应用先前学习的编辑向量直接执行相同的编辑操作,而无需再次进行优化。

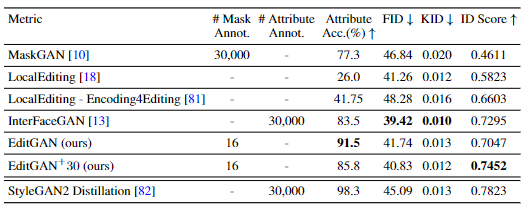
在实验部分,为了EditGAN的图像编辑能力,研究人员使用MaskGAN引入的smile edit基准。将具有中性表情的脸被转换为笑脸,性能主要由三个指标衡量:
-
语义正确性:使用预先训练的笑脸属性分类器,测量面部编辑后是否显示笑脸表情;
-
Distribution-level Image Quality:使用Frechet Inception Distance(FID)和Kernel Inception Distance(KID)在400个编辑的测试图像和Celeba-HD测试数据集之间进行计算;
-
Identity Preservation, 利用预训练的ArcFace 特征提取网络,测量了应用编辑时对象的标识性特征是否保持不变,使用了原始图像和编辑图像之间的余弦相似性。

-
提供非常高精度的图像编辑 -
只需要很少的标注训练数据(不依赖于外部分类器) -
可以实时交互运行 -
允许多个编辑操作的直接合成 -
对于out-of-domain 图像也有很好的效果
参考资料:
https://arxiv.org/abs/2111.03186





