惊艳美国!今天,百度人工智能技术再次成为全球焦点!
百尺竿头更进一步!
百度的人工智能技术,再次闪耀了整个拉斯维加斯!
美国时间2019年1月8日至11日,一年一度的CES国际消费电子展正式在美国拉斯维加斯举行!该展会于1967年成立,发展至今,已经成为了全球各大电子产品企业发布产品信息和展示高科技水平及倡导未来生活方式的窗口!

伴随着时代的变迁,伴随着科技的快速更迭,人类已经站在了第四次工业变革的前夕!与其说是一场电子产品的较量,不如说是一场以人工智能、云技术等前沿科技的较量!
庆幸的是,在这一场新技术的较量中,中国企业早已不再是看客!早在去年的CES国际消费电子展中,百度就已经在了拉斯维加斯的舞台上亮相了,一举打破了美国独领风骚的局面!
时至今日,这次的CES国际消费电子展,百度再次闪耀了整个拉斯维加斯!把人工智能整体技术,推向了一个新的高度!
Apollo自动驾驶技术

早在去年的CES国际消费电子展期间,百度就举办了2018世界大会美国场发布会,大会上,百度正式宣布开启Apollo自动驾驶全球计划!四大模块全部开放,设立Apollo全球实验室,目的就是积聚全球自动驾驶人才,推动全球自动驾驶技术的快速发展!

与此同时,百度还首次向世人展示了在自动驾驶技术上的绝对实力!Apollo自动驾驶平台已经进化至2.0版本,全面支持简单城市道路自动驾驶,更是以中美连线直播的形式,展示了凌晨6点的百度大厦,十辆不同类型、不同功能的百度无人车上路举行“大阅兵”的壮观场景,点亮了百度自动驾驶的全球“不夜航线”。

今天,经过一年时间的洗礼,百度自动驾驶技术再次实现飞跃!在此次2019年的CES百度世界大会美国场上,百度正式发布全球首个最全面的自动驾驶和车联网领域的商业解决方案 —— Apollo Enterprise(Apollo企业版)!
何为Apollo Enterprise?这是百度为汽车企业,供应商和出行服务商加速实现智能化、网联化、共享化,提供量产、定制、安全的自动驾驶和车联网解决方案。
Apollo Enterprise从快速落地、优化成本、全面安全、技术领先等四大方面全面的解决了智能汽车量产的难点,为合作伙伴实现量产化保驾护航!
简单的说就是,百度已经拥有领先的无人车量产实力!Apollo Enterprise的出现,则是打响全球自动驾驶商业量产时代第一枪!

同样,在驾驶技术上,Apollo再次进化至Apollo 3.5版本。拥有全球首个面向自动驾驶的高性能开源计算框架Apollo Cyber RT的全新Apollo 3.5版本,能让自动驾驶汽车轻松的处理复杂场景。窄车道、减速带、人行道、十字路口、无信号灯路口通行、借道错车等十几种复杂路况,统统不再话下!

在车路协同方面,百度建立的ApolloApollo技术与生态框架下,也吸引了中国信息通信研究院、中国移动、大唐电信、千方科技等合作伙伴的加入。并且已经在长沙、北京进行车路协同演示!
无论是软件上、还是硬件上,无论是技术上、还是规模上,百度Apollo自动驾驶都处于全球领先!
如果你觉得百度带来的只是无人驾驶技术的话,那就大错特错了!这一次,百度向世界展现出了百度的整个AI帝国!
DuerOS智能语音技术
在智能语音领域,百度也将动口不动手的智能时代演绎的淋漓尽致!在大会上,百度带来了超豪华的明星阵容,小度家族(小度在家、小度智能音箱、小度智能音箱Pro以及小度语音车载支架)集体亮相。

搭载了最新DuerOS对话式AI操作系统的“ 小度在家 ”,解决了人工智能语音产品的四大难点,听得懂、看得见、能对话、会思考,都不再话下!
这款集可视电话、智能电视和智能音箱于一身的百度智能产品,拥有3000万条短视频、1400万条百科、50万儿童故事、100万相声小品戏曲、100万道菜谱、上亿母婴知识等海量资源。全面的体现出人工智能语音技术给人们带来的便利。

作为开启智能时代,连接万物的物种,小度智能音箱以及小度智能音箱Pro同样具备着非凡能力!
拥有超过1000万小时的海量有声内容、2000万+优质有声节目1000+省市广播电台、80万+精品儿童有声节目、2000万+认证母婴问答等丰富能力的小度智能音箱,俨然成为了你生活中的智能小帮手,听故事、讲笑话、解答问题、深度对话、极客模式等等,无所不能!把“懂你”的智能属性,演绎到极致!

截止目前,百度DuerOS是中国市场规模最大、最活跃、最繁荣的对话式人工智能操作系统。搭载百度DuerOS对话式人工智能操作系统的智能设备已经突破了2亿台,月活跃设备超过了3500万台。同时,DuerOS的合作伙伴数量已经超过300家,搭载DuerOS落地的主控设备超过160多款,在DuerOS平台上的技能开发者数量已经超过2.4万人,这五个数据均为国内第一。小度系列智能硬件遍布全球,已覆盖41个国家,723个城市。
值得一提的是,小度还与老牌科技巨头联想达成了战略合作,将智能语音技术赋能于平板电脑之上,开创了智能平板的新物种!当平板电脑处于闲置状态时,用户只要将其放在联想智能底座上,就摇身一变成为一个智能带屏音箱。

可以想象,未来的智能生活,我们将无比便利!通过小度的赋能、百度AI的赋能,未来更多的电子产品、家居设备都将变得听得懂人话。我们可以直接用语音控制电灯、电视、冰箱、油烟机等等…
智能云技术
在云计算领域,百度同样具备着强大的实力!此次大会,百度智能云发布了中国第一个智能边缘计算产品BIE,以及国内首个智能边缘开源版本OpenEdge。同时,还带来了两款搭载百度智能边缘的硬件产品:BIE-AI-BOX以及BIE-AI-Board。
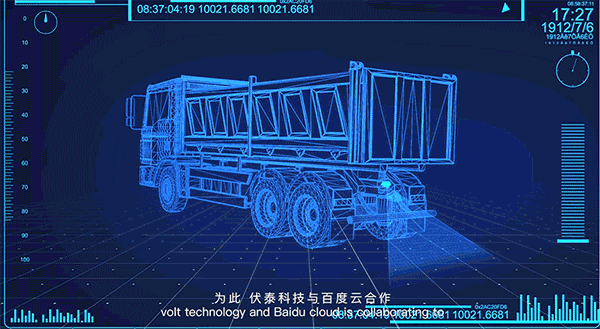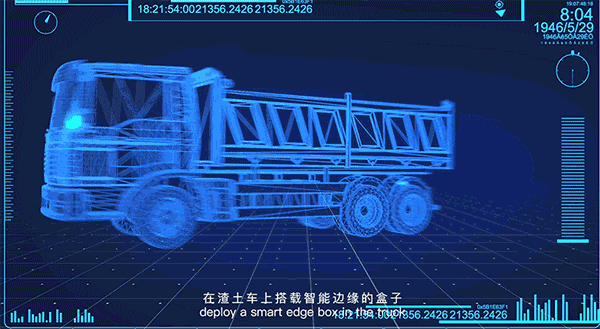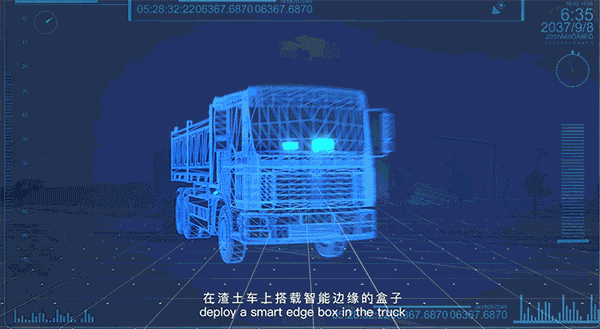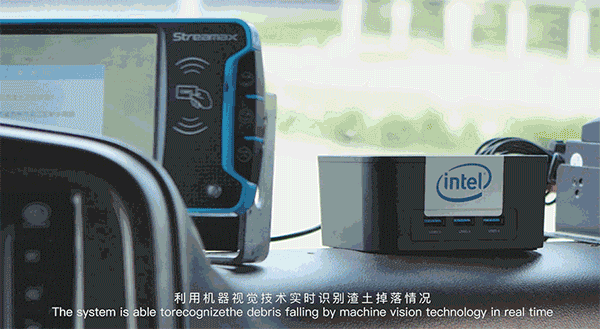
其中,和英格尔合作推出的BIE-AI-BOX,是一款融合了百度智能边缘技术专为车内AI机器设计,可连接摄像头进行优化视频分析的硬件产品,主要应用于车内视频监控和分析,包括路况识别、车身监测和驾驶人监测。

而和恩智浦及麦飞科技联手打造的BIE-AI-Board,是一款融合了百度智能边缘技术为移动设备检测设计的硬件产品,具备可拓展、低能耗的优势,主要应用于无人机(农业)、手持移动设备检测工具和检测机器人等场景。
于此同时,百度还以实物的形式,展示出了百度自主研发的超级AI计算平台X-MAN3.0,以及以背板的形式展示了支撑百度AI计算层面的FAST-FAI存储、百度AI计算训练平台KongMing GPU、AI计算系统Anakin等软件产品!

截止目前,X-MAN 3.0出货量位于中国第一,其深度运算的能力达到了每秒2万亿次!
是的,你没有看错,一次比一次猛烈!一次比一次震撼!不鸣则已,一鸣惊人!
作为中国人工智能的领头羊,百度仿佛在向世人展示着来自中国的人工智能速度。在短短的一年时间里,百度在人工智能领域,再次实现突破。无论是智能驾驶技术、还是智能语音技术、以及智能云计算,百度都达到了世界领先的水平!

当全世界的无人驾驶技术,还普遍停留在测试阶段之时;百度的无人驾驶技术已经率先达到L3、L4水平,完成了从简单环境到复杂环境的跨越。无人车量产不再是一个遥远的梦想!
当谷歌、亚马逊的智能语音技术,还停留在听懂简单的英文之时,百度的智能语音技术已经征服了人类最复杂的语言 —— 中文!
当美国还在为自己的云计算能力沾沾自喜之时,殊不知,来自中国的云计算能力,正在全面冲击!
一切的一切,都在印证着一个事实。百度正在打造属于中国自主创新的人工智能时代!
或许有人会说,虽然百度进步很快,但是亚马逊、谷歌在市场占有率上依旧有着优势。是的,你说的没错,但是这并不能说明什么问题,并不代表他们是不可超越的。况且,他们领先的只是市场,并不是技术。在人工智能的整体技术上,百度很明显更具备着竞争力。更重要的是,在人工智能时代,中国在核心的底层技术上,不在受制于人,全面实现自主化!
要知道,科学技术不仅关乎着一个国家的前途命运,更关乎着13亿人民的福祉!就如主席说的,中国要想强盛、要想复兴,就一定要抓住科技创新的“牛鼻子”!关键技术是要的来、买不来、更讨不来的,只能靠我们自己奋发图强!
今天,在第四工业革命到来的前夕、在人工智能、云计算等新技术全面覆盖的前夕,百度让我们看到了希望的曙光。在人工智能时代,中国将不再是跟随者,而是引领世界的领头者之一!
别了,那个任人宰割的时代!别了,那个没有任何核心技术话语权的时代!百度为首的中国科技企业,正在把科技创新的“牛鼻子”牢牢的掌控在自己手中!




