爬网页、洗数据、创建海量数据集一条龙!英伟达工程师小姐姐开源工具库
乾明 发自 凹非寺
量子位 报道 | 公众号 QbitAI
想做研究,却没有足够的数据,着实让人抓狂、苦恼。
现在,你可以自己动手创建数据集了。
英伟达工程师小姐姐Chip Huyen,在GitHub上开源了一个名为“lazynlp”的工具库。
爬网页、清洗数据、创建数据集都可以搞定。
她说,使用这个库,你应该能创建一个比大于40G的文本数据集,比OpenAI训练GPT-2时使用的还要大。
开源仅一天,项目在GitHub上就获得了300多星,Twitter上获得上千次点赞。fast.ai创始人Jeremy Howard等人也转发推荐。
而且,用这个工具库创建数据集的过程,也并不麻烦。
五步走,一条龙
第一步,获取你想抓取的网页的网址。
小姐姐提供了三个你可以直接拿走使用的网址集合,分别来自Reddit、古腾堡计划(电子书)、维基百科。
当然,你也可以下载自己的。
第二步,删除重复的网址。
网址有很多,重复也在所难免。
这里提供了两种方法,来删除重复的网址。
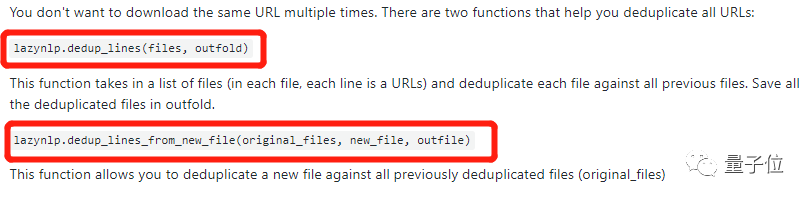
第三步,下载网址内容。
这里提供了两种方法,一种可以并行下载多个文件,另一种可以单独下载网页内容。
如果网址数量比较大,可以将列表分成多个文件的,分别调用函数。
小姐姐说,自己能够并行40个脚本,下载起来也更容易一些。
第四步,清理网页。
这一步有3个方法可以选择,一是使用lazynlp/cleaner.py中的方法,二是直接调用命令行:
lazynlp.clean_page(page)
另外,也可以使用lazynlp.download_pages ( )函数,同时爬网页并清理。
第五步,删除重复网页。
网站下载好了,该清理的东西都清理了,接下来需要去重。
不然就会有一些文本重复出现,从而影响数据集的表现。
小姐姐提供了3个函数,可以帮你完成步骤。
做完这些,你就有自己的NLP数据集了,想干什么就可以放手去做了。
如果你有想法,请收好下面的传送门:
https://github.com/chiphuyen/lazynlp
— 完 —
一份小调查
大噶好,
为了了解大家感兴趣的话题,丰富我们的报道内容,带来更好的阅读体验,请大家帮我们填一份调查问卷鸭,扫码即可进入问卷页面。
笔芯。( ̄︶ ̄)➷➷➷


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「好看」吧 !




