中央音乐学院开招「音乐人工智能」博士,要会写代码,还要吹拉弹唱
郭一璞 假装发自 鲍家街
量子位 报道 | 公众号 QbitAI

「音乐人工智能」?
这是什么神奇的专业啊?
这两天,中央音乐学院发布了一则招聘博士生的通告,专业全称是音乐人工智能与音乐信息科技,要培养音乐与理工科交叉融合的复合型拔尖创新人才,是中央音乐学院首次招收这个方向的博士生。
因为是一个“跨界”专业,想成为中央音乐学院的音乐人工智能博士,要求还不低。
会写代码,还会吹拉弹唱
这个三年制的博士虽然是音乐方向,但是需要计算机等相关专业出身,报考条件中明确写着“报考本方向者须为计算机、智能和电子信息类考生”。
除了计算机专业背景之外,作为一个音乐人工智能博士,还必须懂音乐。
在面试中,考生除了需要展示专业能力、研究计划之外,还需要展示自己的音乐能力,要求可演奏某种乐器或演唱。
当然,英语能力也要过关。
会写代码,会唱歌奏乐,英语还好,怕不是要找个神仙似的小哥哥/小姐姐呀~

△ B站鬼畜区第一歌手、写代码如写诗的雷军
中央音乐学院还给出了书单:
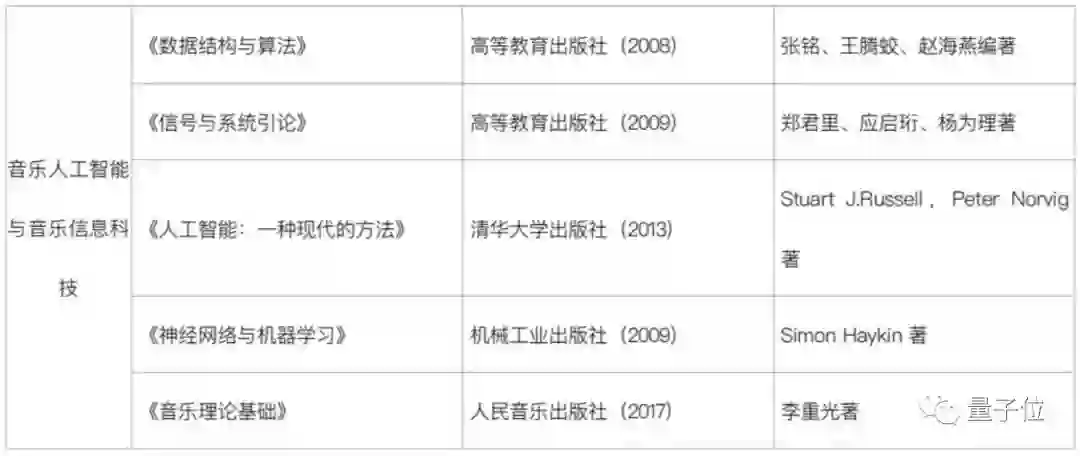
一共四本AI相关的书《数据结构与算法》、《信号与系统引论》、《人工智能:一种现代的方法》、《神经网络与机器学习》,音乐相关的只有一本《音乐理论基础》。
记住,要考的!
导师都是大牛
招生要求高,导师自然都是大牛。
因为是“跨界”专业,音乐人工智能博士采取的是双导师培养制,有音乐方面的导师,也有AI方面的导师。

△ 俞峰
音乐方面的导师是中央音乐学院院长俞峰教授,他是中国指挥学会会长、全国艺术专业学位研究生教指委副主任,享受国务院政府特殊津贴。

△ 孙茂松,图片来自清华大学
AI方面的导师想必量子位的读者们会熟悉一些。
一位是清华大学人工智能研究院常务副院长、国家973计划项目首席科学家、国家社会科学基金重大项目首席专家孙茂松教授,他主要研究领域为自然语言处理、人工智能、机器学习和计算教育学,曾在2017年领衔研制出“九歌”人工智能古诗写作系统。

△ 吴玺宏
另一位AI方面的导师是北京大学信息科学技术学院副院长、智能科学系主任、言语听觉研究中心主任吴玺宏教授,他致力于机器听觉计算理论、语音信息处理、自然语言理解以及音乐智能等领域的研究,先后主持国家级、省部级项目40余项,获国家授权发明专利10余项,发表学术论文200余篇,在智能音乐创作、编配领域颇有成就。
高端操作:AI音乐会
其实,中央音乐学院不是第一次对AI+音乐产生兴趣了。

就在去年11月,他们在学校里举办了一场人工智能音乐会,音乐会上演奏的方式是人机合作,由12位中央音乐学院的演奏家与AI合作,分别演奏12首乐曲。
12位演奏家擅长的乐器分别是:小提琴、中提琴、大提琴、小号、长号、圆号、长笛、双簧管、单簧管、萨克斯、巴松管、二胡,每首曲目由演奏家演奏自己的乐器,AI“解读”音乐后,生成贴近音乐家个性化表现需求的伴奏和协奏模版。

这样,就可以你奏乐,AI来和,一弹一和,相得益彰。
至于“应和”的技术,来自于中央音乐学院与美国印第安纳大学信息计算与工程学院的一项合作,半年前,两所学校合作开设了“信息学爱乐乐团”实验室。
印第安纳大学的克里斯托弗·拉斐尔(Christopher Raphael)教授发明了“信息爱乐”系统,他曾为双簧管职业演奏家,后获布朗大学应用数学博士学位,专注于音乐人工智能研究。
至于具体的演出效果,中央音乐学院在今年春节期间发布了发布了一个表演视频,大家可以戳开围观一下↓
视频中iPad上运行的应用是“Cadenza人工智能伴奏系统”,就是“信息爱乐”的iOS版,App Store里可以下载。

有设备和琴技的同学可以去体验一下,量子位先给大家上读博传送门了~
传送门
最后,送上中央音乐学院的招生通告,想尝试这个新方向的话不妨试一试:
https://mp.weixin.qq.com/s/yyyUrk2FSE1Fmhl4-5JvCw
— 完 —
一份小调查
大噶好,
为了了解大家感兴趣的话题,丰富我们的报道内容,带来更好的阅读体验,请大家帮我们填一份调查问卷鸭,扫码即可进入问卷页面。
笔芯。( ̄︶ ̄)➷➷➷


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「好看」吧 !




