数据分析师应该知道的16种回归技术:弹性网络回归
通过前面的学习我们知道,岭回归通过添加回归系数的L2范数对回归系数进行收缩,从而增加估计值的稳定性;LASSO回归则通过添加回归系数的L1范数回归系数进行收缩。不同于岭回归的是,只要惩罚系数足够大,LASSO回归就可把所有系数收缩到0。因此,LASSO回归可以用来进行变量选择,对数据的解释性也更强。然而,LASSO也存在如下不足:
当
时,至多可选择
个特征变量。
若变量中存在高度相关的变量组,LASSO回归仅选择一个而忽视其他变量,就这一点而言,岭回归要优于LASSO回归。
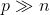 时,至多可选择
时,至多可选择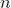 个特征变量。
个特征变量。弹性网络回归可以克服这些不足,它在LASSO回归的惩罚项中加入回归系数的L2范数,使得损失函数严格凸,保证目标函数有唯一最优解。因此,弹性网络回归的目标函数为:
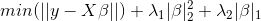
因为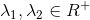
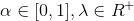
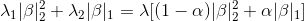
若设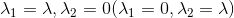
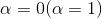
类似于岭回归和LASSO回归,可以用交叉验证的方法来寻找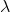
案例
我们使用的是MASS包中的Boston数据集,该数据集记录506个波士顿不同区域的14项社会指标,详细内容见下图所示。我们想通过这组数据探究不同区域的房价中值(mdv)同其他指标之间的关系。

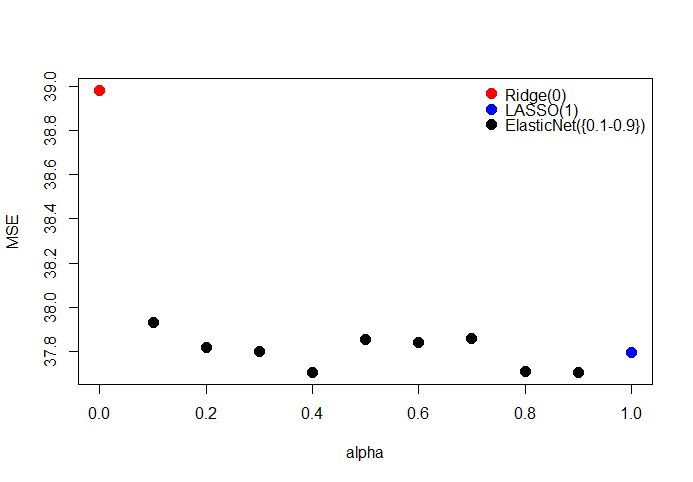
用网格搜索法找到最优alpha,最优alpha值为0.4。
# 加载数据集合
data("Boston", package = "MASS")
set.seed(5)
id <- sample(1:nrow(Boston),nrow(Boston)*2/3)
#训练集
x1 <- Boston[id,-14];y1 <- Boston[id,14]
#测试集
x2 <- Boston[-id,-14];y2 <- Boston[-id,14]
library(glmnet)
fun <- function(alp){
model <- cv.glmnet(as.matrix(x1),y1,alpha = alp)
fit <- predict(model,s = model$lambda.min,newx=as.matrix(x2))
return(mean((fit-y2)^2))
}
mse=sapply(0:10*.1, fun)
cols=c(2,rep(3,8),4)
plot(1,type = 'n',xlab = 'alpha',ylab = 'MSE',
xlim = c(0,1),ylim = c(min(mse),max(mse)))
points(1:9*.1,mse[2:10],cex=1.5,pch=16)
points(0,mse[1],cex=1.5,pch=16,col='red')
points(1,mse[11],cex=1.5,pch=16,col='blue')
legend('topright',c('Ridge(0)','LASSO(1)','ElasticNet({0.1-0.9})'),
pch=16,col = c('red','blue','black'),bty = 'n',pt.cex = 1.5)
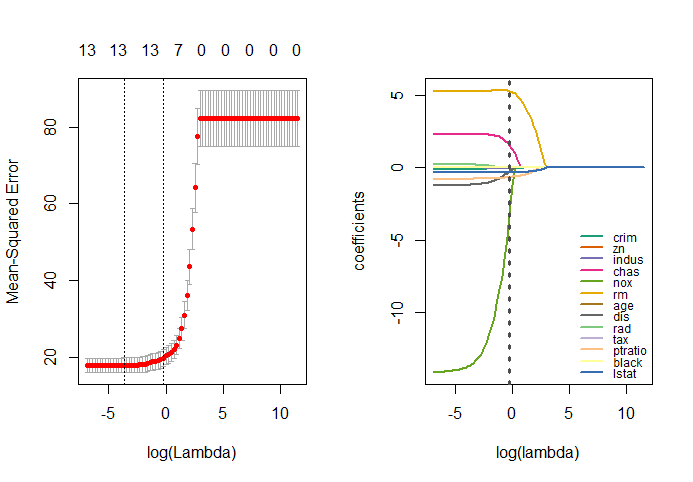
在最优alpha值下用交叉验证法寻找最优lambda,最优lambda值为0.025。
model <- cv.glmnet(as.matrix(x1),y1,alpha = 0.4,keep=T,
lambda = 10^seq(5,-3,-0.1))
model$lambda.min

绘制回归系数在不同lambda下的变化曲线
op=par(mfrow=c(1,2))
plot(model)
library(RColorBrewer)
hatbeta <- as.matrix(model$glmnet.fit$beta)
lambda = log(10^seq(5,-3,-0.1))
plot(1,type = 'n',xlim = c(min(lambda),max(lambda)),
ylim = c(min(hatbeta),max(hatbeta)),
xlab = 'log(lambda)',ylab = 'coefficients')
colrs = c(brewer.pal(8,"Dark2"),brewer.pal(5,"Accent"))
for (i in 1:13) {
lines(lambda,hatbeta[i,],col=colrs[i],lwd=2)
}
abline(v=log(best_lambda),lty=3,lwd=3,col='gray30')
legend('bottomright',rownames(hatbeta),lty = 1,lwd=2,
col=colrs,bty = 'n',cex = 0.75)
par(op)
推荐阅读
从零开始深度学习第8讲:利用Tensorflow搭建神经网络


长按二维码关注“数萃大数据”



