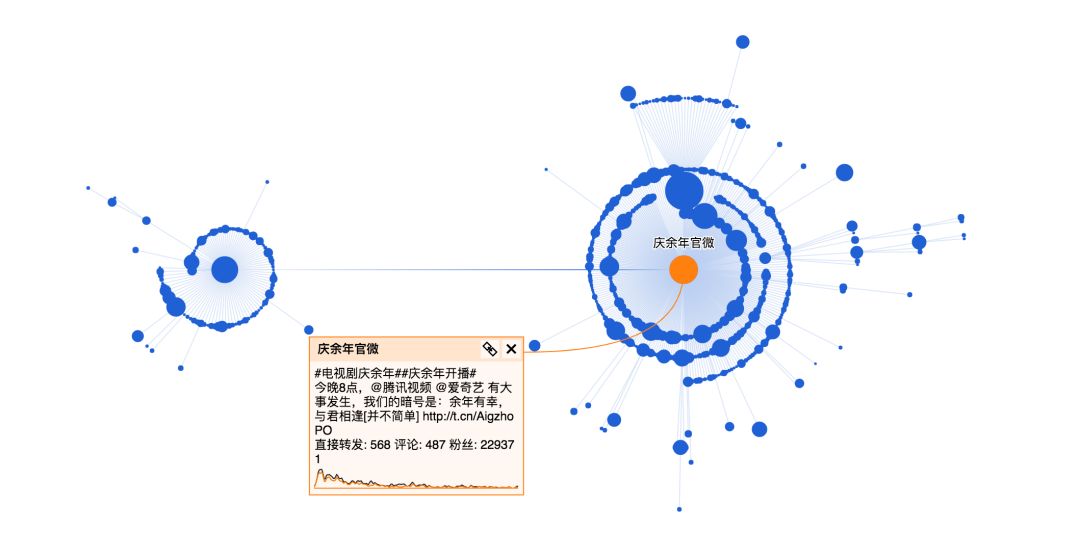
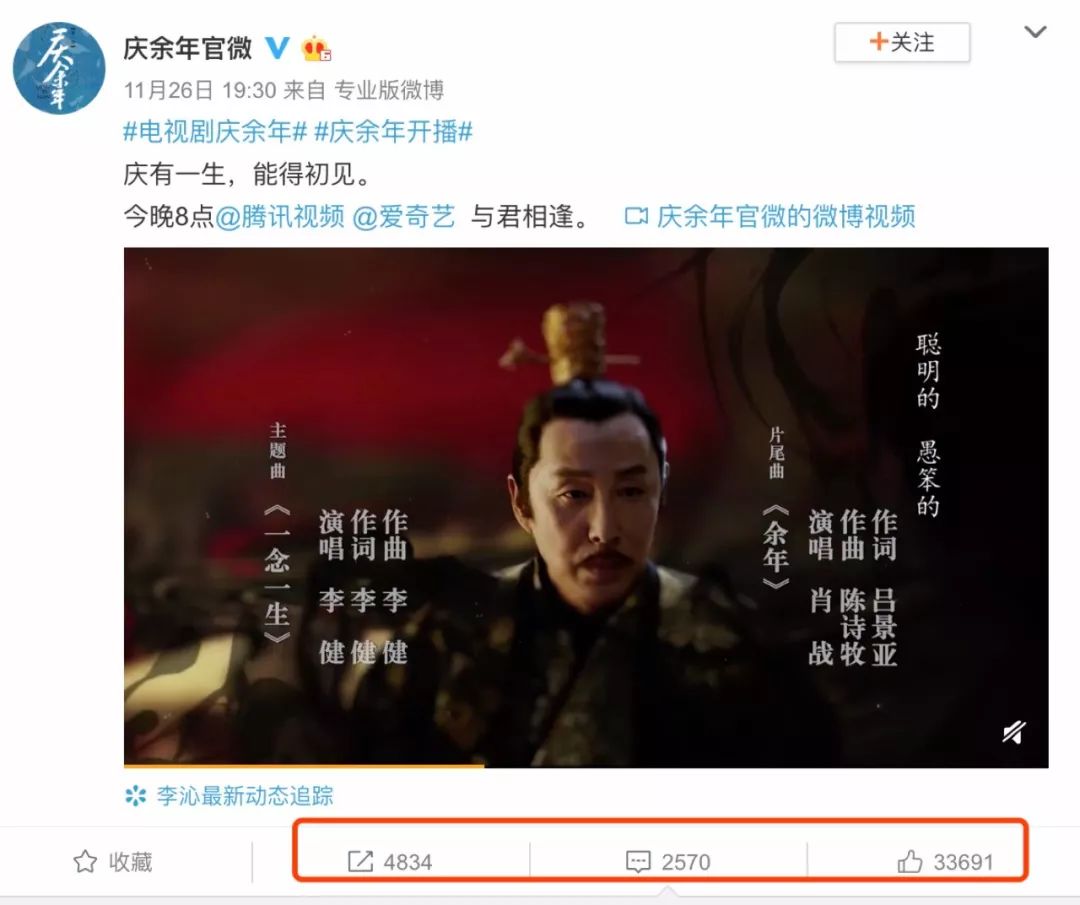
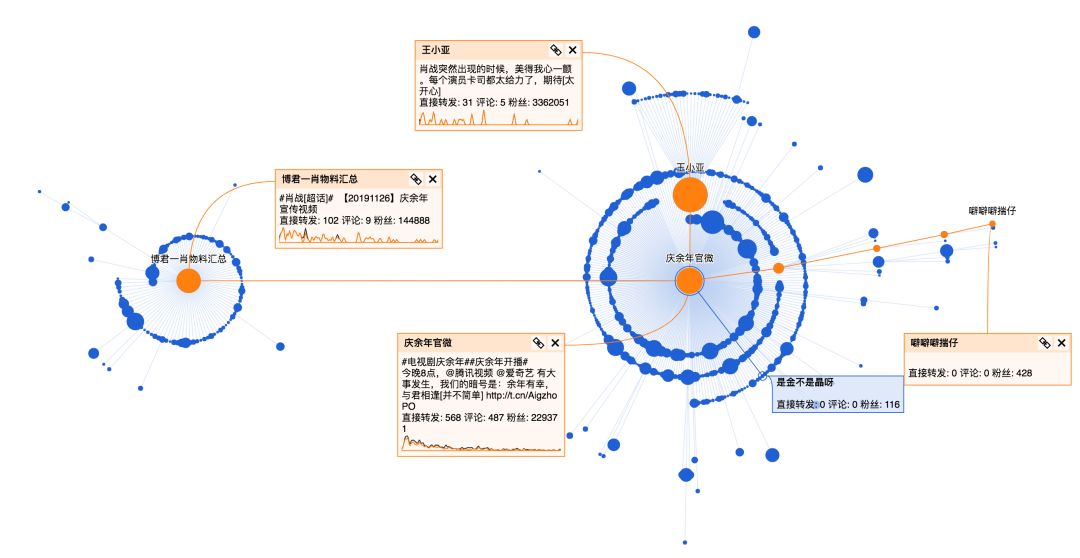
Python 分析到底是谁操纵《庆余年》上了热搜?






import argparse
parser = argparse.ArgumentParser(description="weibo comments spider")
parser.add_argument('-u', dest='username',
help=
'weibo username',
default=
'')
#输入你的用户名
parser.add_argument(
'-p', dest=
'password',
help=
'weibo password',
default=
'')
#输入你的微博密码
parser.add_argument(
'-m', dest=
'max_page',
help=
'max number of comment pages to crawl(number<int> larger than 0 or all)',
default=)
#设定你需要爬取的评论页数
parser.add_argument(
'-l', dest=
'link',
help=
'weibo comment link',
default=
'')
#输入你需要爬取的微博链接
parser.add_argument(
'-t', dest=
'url_type',
help=
'weibo comment link type(pc or phone)',
default=
'pc')
args = parser.parse_args()
wb = weibo()
username = args.username
password = args.password
try:
max_page =
int(
float(args.max_page))
except:
pass
url = args.link
url_type = args.url_type
if
not username
or
not
password
or
not max_page
or
not
url
or
not url_type:
raise ValueError(
'argument error')
wb.login(username,
password)
wb.getComments(
url, url_type, max_page)








import jieba
test=
'temp.txt'
#设置要分析的文本路径
text = open(test,
'r',
'utf-8')
seg_list = jieba.cut(text, cut_all=
True, HMM=
False)
print(
"Full Mode: " +
"/ ".join(seg_list))
# 全模式

def synonymous_names(synonymous_dict_path):
with codecs.open(synonymous_dict_path,
'r',
'utf-8')
as f:
lines = f.read().split(
'\n')
for l
in lines:
synonymous_dict[l.split(
' ')[
0]] = l.split(
' ')[
1]
return synonymous_dict
def clean_text(text):
new_text = []
text_comment = []
with open(text, encoding='gb18030') as f:
para = f.read().split(
'\r\n')
para = para[
0].split(
'\u3000')
for i in range(len(para)):
if para[i] !=
'':
new_text.append(para[i])
for i in range(len(new_text)):
new_text[i] = new_text[i].replace(
'\n',
'')
new_text[i] = new_text[i].replace(
' ',
'')
text_comment.append(new_text[i])
return text_comment
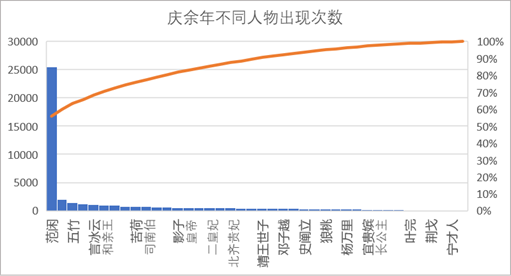
text_node = []
for name, times in person_counter.items():
text_node.
append([])
text_node[
-1].
append(name)
text_node[
-1].
append(name)
text_node[
-1].
append(str(times))
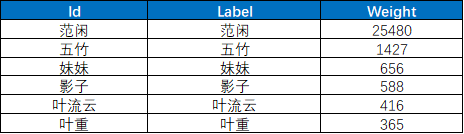
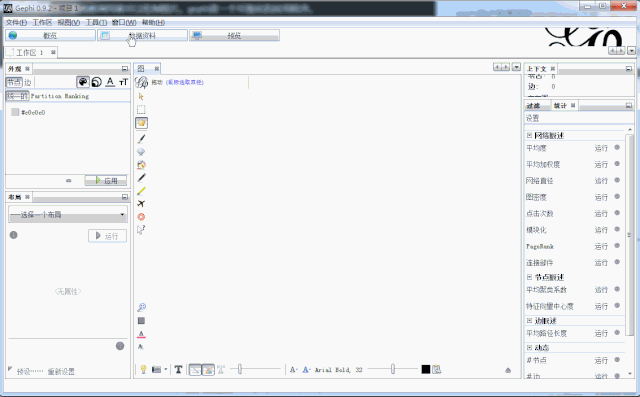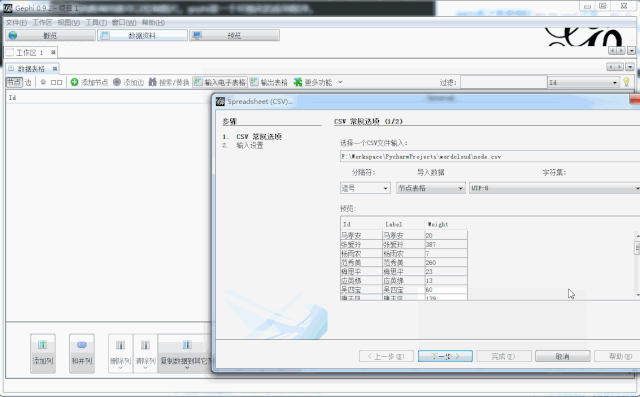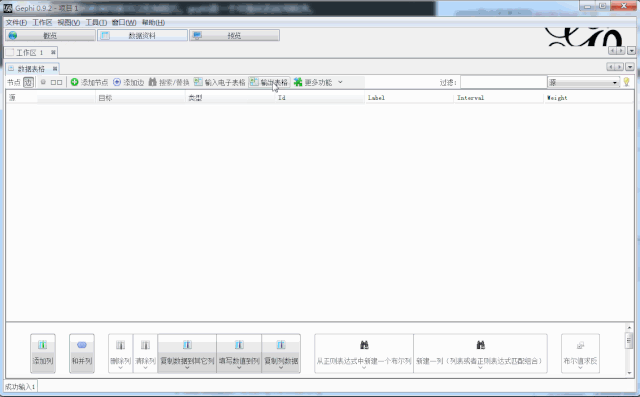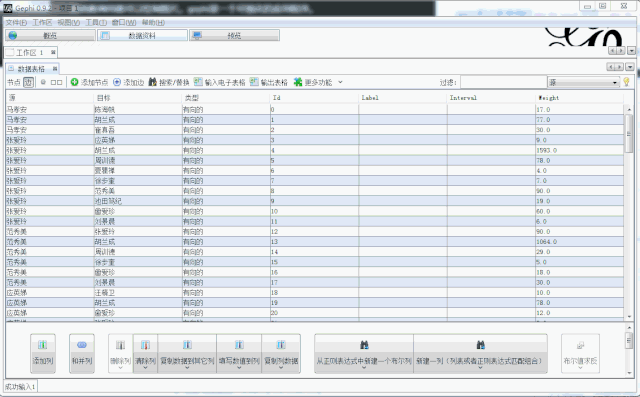
node_data = DataFrame(text_node, columns=[
'Id',
'Label',
'Weight'])
node_data.to_csv(
'node.csv', encoding=
'gbk')
登录查看更多
相关内容

Arxiv
10+阅读 · 2020年3月31日
Arxiv
3+阅读 · 2019年3月6日





相关VIP内容
相关资讯
相关论文
Arxiv
10+阅读 · 2020年3月31日
Arxiv
3+阅读 · 2019年3月6日