![]()
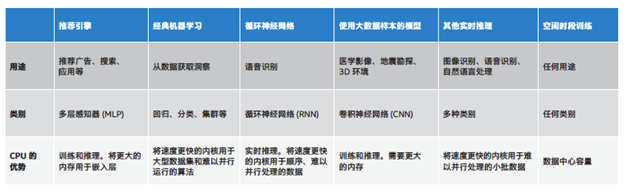
AI时代不一定是GPU为王,针对不同的业务,如推荐引擎、经典机器学习、循环神经网络,CPU有其不同的优势。
正在采用AI加速发展的企业,和将会采用AI的企业。
人工智能的重要性不必赘言——新一轮产业变革的核心驱动力量,将推动数万亿数字经济产业转型升级。
![]()
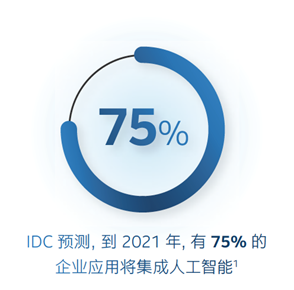
IDC 预测,到 2021 年,有 75% 的企业应用将集成人工智能。即使有些企业目前不考虑使用人工智能,但总是需要处理越来越复杂的数据。
AI这趟顺风车当然要搭上,
然而飞得高不高固然重要,飞得累不累也不可忽视
:企业该选择怎样的计算基础设施?革新的同时如何保证成本在可接受范围?如何保持经济高效的运营和灵活性?
「因地制宜」:IT基础设施何须推翻重来?基于CPU运行人工智能吧
这些「灵魂拷问」都直接涉及企业未来的AI路线,其中关于IT基础设施的部署工作是重中之重。
事实上,企业通常已经在IT基础设施上做了投资,
改弦更张推倒重来的代价太大
。但AI应用的计算需求极高,为保证准确性对延迟和巨大吞吐量有着苛刻的要求。数据中心的负责者应该怎么样部署IT基础设施?
![]()
在增加新的AI工作负载时,必须先确保新功能可以优化现有资源,然后再考虑投资新计算资源。
在现有的计算基础设施上,即基于CPU的基础设施上运行人工智能工作负载可能是理想的选择。这样既能满足数据科学家的加速和性能需求,又能达成效率、可扩展性和灵活性目标。
或许不少数据科学家认为基于 GPU 的硬件平台能够为某些深度学习训练工作负载提供非常高的吞吐量,因此能够加快人工智能模型开发。
但深度学习氛围训练及推理两大阶段,如今推理比重越来越大,实际上开发速度很大程度上取决于涉及的人工智能工作负载、数据类型和要求。
![]()
针对不同的业务,如推荐引擎、经典机器学习、循环神经网络,CPU有其不同的优势,
大可以抱着开放的态度选择合适的平台对症下药。
灵活高效可扩展,阿里云基于第三代英特尔至强提升 BERT 模型性能
在确定工作负载本身的特征时,可以先向自己提问以下几个问题:
BERT是阿里云人工智能平台的主要模型之一。在与AI相关的各类服务中,它被广泛用于自然语言处理任务。阿里云希望通过降低延迟来提升用户体验。
而对于 BERT,模型参数庞大且固定在推理过程中。
![]()
集成在第三代英特尔至强可扩展处理器中的英特尔深度学习加速技术支持全新 Brain Floating Point (bfloat16,BF16) 指令。阿里云利用这一性能优势,优化主要人工智能模型的推理性能,进而提升服务体验并降低总体拥有成本。
内置BF16指令可以说是第三代至强可扩展平台的最大特性,进一步增强了现有的深度学习优化能力——对于新至强平台来说,
BF16相对于原有的FP32可以获得近2倍的性能。
这将提升大大提升AI人工智能、ML机器学习、DL深度学习等应用的性能、效率。
![]()
支持 BF16 的英特尔深度学习加速技术可在将准确率影响降至最低与大幅提高吞吐量之间达成平衡。
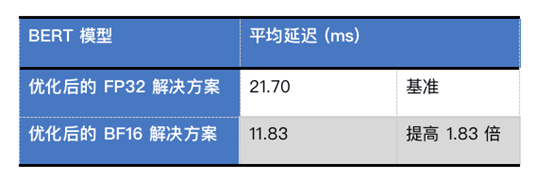
使用 BF16 MatMul 替代了 FP32 MatMul,并在第三代英特尔至强可扩展处理器上使用 oneAPI 深度神经网络库 (oneDNN) 1.3 版本进行测试。结果表明,BF16 解决方案实现了 1.83 倍的增益。此外,在处理用于分类任务的 MRPC 数据集时,BF16 解决方案的准确率与 FP32 解决方案相同(两者对于代理模型的准确率均为 83.59%)。
![]()
灵活性、高效率、可扩展性是英特尔至强平台运行人工智能工作负载的三大优势。
英特尔至强平台原本就具有多种用途,因此能够支持广泛的工作负载。
借助大量针对机器学习和深度学习所做的软件优化和集成英特尔深度学习加速技术的推理加速功能,基于 CPU 运行人工智能的速度大幅提高。
在许多情况下,CPU 是深度学习训练的理想选择。
通过针对常见人工智能软件框架(例如 TensorFlow 和 PyTorch)、库和工具所做的优化,帮助保持较高的性能功耗比和性价比,使 PUE 比率尽可能接近 1。
软硬结合,在数据生命周期中融入人工智能
海量数据、算力和AI算法,被称为AI的三大支柱。而英特尔至强平台是一个理想的基础,可让企业和机构利用现有的数据、数据分析程序和基础设施资源,依靠这个平台开启人工智能之旅。
![]()
需要企业长期投入积累才能获取的数据是企业推进AI时最重要的先决条件。
即使有些企业目前不考虑使用人工智能,但总是需要处理越来越复杂的数据,进行数据分析。
企业和机构不仅必须要厘清哪些数据可用于提高竞争力和经营绩效,还必须攻克采集、分析和使用数据方面的挑战。
进入企业的数据在来源、体量、格式、结构和频率上多种多样。单单是收集和清洗数据,就耗费了数据科学家大约 40% 的时间。关键的第一步就是创建一个系统,在数据进入企业时,立即采集、存储和处理这些数据(从边缘到云)。
英特尔QuickAssist 技术等压缩技术有助于减小需要传输的数据大小。
同时,英特傲腾持久内存能够将更多数据保存在靠近 CPU 的位置,进而实现更多实时处理。数据准备妥当后,可以使用英特尔傲腾固态盘,实现经济高效的高容量数据存储。
![]()
软件算法对于人工智能同样至关重要。从头开始为每个应用重新构建所需的数学和算法是一项费时费力的复杂工作,
何不借助前辈的框架、库、工具和预先训练模型,从中直接受益?
为了满足这一需求,英特尔面向英特尔架构对被广泛采用的人工智能软件框架进行了各类优化,以期大幅提高应用性能,方便企业能够在现有环境中使用熟悉的英特尔至强平台开发高效的人工智能模型。
例如,对在 ResNet-50 上运行图像分类工作负载而言,利用集成面向ResNet-50 的英特尔深度学习加速技术的至强铂金 8280 处理器以及面向英特尔架构优化的 Caffe 版本框架,与最初发布的至强铂金 8180 处理器相比,
推理性能提升高达 14 倍。
其他优化还包括面向 TensorFlow、MXNet 和 Python 的优化,可助力企业能够在已知的数据中心服务器上实现所需的性能。
英特尔针对主流框架进行了优化。
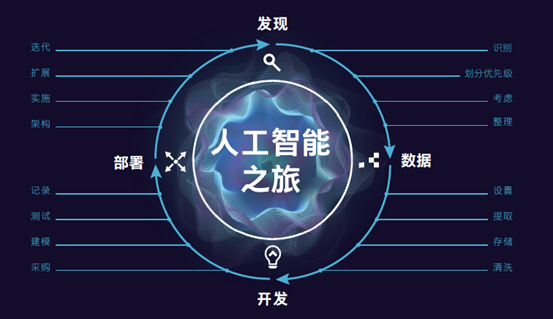
算力(IT基础设施)、算法、数据,无论是从推进人工智能发展的三大支柱,亦或数据自身生命周期(发现、数据、开发、部署),企业拥抱人工智能,加速AI落地都需要进行思量,做出选择。
在做出选择时,企业的业务需求是推动力,其自身已有的IT环境则是做出决策的大前提,持续开发广泛AI计算产品组合的英特尔可以提供高性价比方法。