苏黎世联邦理工DS3Lab:构建以数据为中心的机器学习系统

机器之心知识站与国际顶尖实验室及研究团队合作,将陆续推出系统展现实验室成果的系列技术直播,作为深入国际顶尖团队及其前沿工作的又一个入口。赶紧点击「阅读原文」关注起来吧!
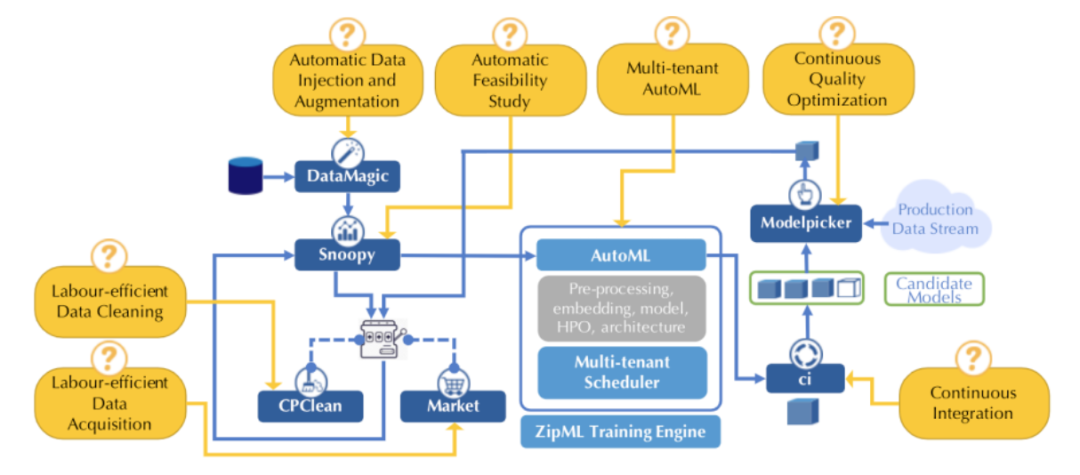
Ease.ML项目地址:https://ease.ml
ZipML项目地址:https://zip.ml

12月15日 20:00-21:30
Speaker: Ce Zhang
Biography: Ce is an Assistant Professor in Computer Science at ETH Zurich. The mission of his research is to make machine learning techniques widely accessible---while being cost-efficient and trustworthy---to everyone who wants to use them to make our world a better place. He believes in a system approach in enabling this goal, and his current research focuses on building next generation machine learning platforms and systems that are data-centric, human-centric, and declaratively scalable. Before joining ETH, Ce was advised by Christopher Ré. He finished his PhD at University of Wisconsin-Madison and spent another year as a postdoctoral researcher at Stanford. His work has received recognitions such as the SIGMOD Best Paper Award, SIGMOD Research Highlight Award, and Google Focused Research Award, and has been featured and reported by Science, Nature, the Communications of the ACM, and a various media outlets such as Atlantic, WIRED, Quanta Magazine, etc.
Abstract: In this talk, I will provide a broad overview of the research activities of DS3Lab, centered on improving the scalability and usability of machine learning systems and platforms. Many of these activities will be discussed in detail in the following six sessions.
Speaker: Bojan Karlas
Biography: Bojan is a fourth-year PhD student at the Systems Group of ETH Zurich advised by Prof. Ce Zhang. His research revolves around data management systems for machine learning. Particularly, he works on building principled tools for managing machine learning workflows, data debugging and data cleaning for ML. His industry experience involves research internships at Microsoft, Oracle and Logitech, as well as a two-year software engineer position at the Microsoft Development Center Serbia where he worked in the SQL Server Parallel Data Warehouse team. Prior to joining ETH, he got a computer science master's degree at EPFL in Lausanne and a software engineering bachelor's degree at ETF Belgrade.
Abstract: Which training examples in my training set are more “guilty” to make my trained machine learning (ML) model low accuracy, unfair, or non-robust to adversarial attacks? If some of my training examples contain missing information, which incomplete training example should I repair first? Answering questions like these will have a profound impact on future ML systems to guide users through both development (MLDevs) and operation (MLOps). This requires us to understand the fundamental concept of data importance with respect to model training.In this talk, we focus on two types of data errors (missing values and wrong values) and examine principled methods for guiding the attention of our data debugging effort. Specifically, for each of these types of data errors, we will go over two kinds of ways to represent data importance which we focus on in our work. For missing data we look at information gain, and for wrong data we look at the Shapley value. There have been intensive recent efforts in speeding up and scaling up the calculation of these importance measures via MCMC or proxy models such as k-nearest neighbors. However, all these efforts only deal with ML training in isolation and ignore the data processing pipelines (or queries) precursing ML training in most, if not all, ML applications. This significantly limits the application of these techniques in real-world scenarios. Our work takes the first step towards jointly analyzing data processing pipeline with ML training and we develop novel algorithms for computing these important metrics in polynomial time.
12月16日 20:00-21:00
Speaker: Cedric Renggli and Merve Gurel
Biography:
Cedric is a PhD Student supervised by Ce Zhang in the Systems Group at ETH Zurich. His main research interest lies in the foundation of usable, scalable and efficient data-centric systems to support all kinds of interactions in a machine learning model lifecycle, broadly known as MLOps. This notably led to the definition of new engineering principles, such as how to run a feasibility study for ML application development, or how to perform continuous integration (CI) of ML models with statistical guarantees. Cedric is furthermore working on efficient methods to enable model search functionalities in pre-trained model collections. This typically serves as a starting point to solve new machine learning tasks using transfer learning.Cedric holds a bachelor's degree from the Bern University of Applied Sciences and received his MSc in Computer Science from ETH Zurich in 2018. His work on Efficient Sparse AllReduce For Scalable Machine Learning was awarded with the silver medal of ETH Zurich for outstanding master thesis. During his PhD, Cedric has worked as a research intern and student research consultant at Google Brain in Zurich.
Merve is a PhD candidate within theSystems Group in theDepartment of Computer Science at ETH Zurich. Her research goal is to form a principled understanding of many aspects of machine learning systems: from hardware to label efficiency and robustness. Moreover, using this knowledge, she aims to build theoretically-sound, usable, robust and scalable machine learning systems. Recently, her efforts have been recognized by Google where she has received the 2021 Google Scholarship award. She obtained her masters from theSchool of Computer and Communication Sciences at EPFL, where she was a research scholar at the Information Theory Laboratory. There she worked on topics of advanced probability and information theory such as convergence rates of bounded martingales and rate-distortion theory. During and after her masters, she was also a researcher at IBM Research in Zurich, and worked on building denoising algorithms for modern radio telescopes.
Abstract:Machine learning projects are usually not completed after having successfully trained a machine learning model satisfying the required performance indicators (e.g., accuracy). Rather the model enters into the operational phase, whereby multiple new challenges can occur. In this talk, we will focus on two main data-centric challenges in the operational stage of a ML model lifecycle: (1) how to continuously integrate and test a model to fulfill some requirements with strong statistical guarantees, and (2) how to select the best generalizing model for a target classification task by querying as minimum label as possible. We illustrate their benefits in several practical scenarios.
In the first part of this talk, we focus on continuous integration, an indispensable step of modern software engineering practices to systematically manage the life cycles of system development. Developing a machine learning model is no difference — it is an engineering process with a life cycle, including design, implementation, tuning, testing, and deployment. However, most, if not all, existing continuous integration engines do not support machine learning as first-class citizens. In this talk we present ease.ml/ci, to our best knowledge, the first continuous integration system for machine learning providing statistical guarantees. The challenge of building ease.ml/ci is to provide rigorous guarantees, e.g., single accuracy point error tolerance with 0.999 reliability, with a practical amount of labeling effort, e.g., 2K labels per test. We design a domain specific language that allows users to specify integration conditions with reliability constraints, and develop simple novel optimizations that can lower the number of labels required by up to two orders of magnitude for test conditions popularly used in real production systems.
In the second part, we present Model Picker, a set of active model selection strategies to select the model with the best generalization capability for a target task. Specifically, we ask: “Given k pre-trained classifiers and a stream or pool of unlabeled data examples, how can we actively decide whose label to query so that we can distinguish the best model from the rest while making a small number of queries?” Towards that, we introduce two active model selection strategies under the umbrella of Model Picker for pool- and stream-based settings. We also establish their theoretical guarantees, and extensively demonstrate its effectiveness in our experimental studies. We show that the competing methods often require up to 2.5x more labels to reach the same performance with Model Picker.
12月17日 20:00-21:00
Speaker: Luka Rimanic
Biography:Luka Rimanic earned his PhD in 2018 in the mathematics department at University of Bristol, after completing Part III at the University of Cambridge. Back in the days, he was exploring the field of additive combinatorics, whilst using a number of other fields in conjunction. Upon completing his PhD degree, Luka had a spell in industry as a consultant for machine learning tasks before joining the DS3Lab, Systems Group at ETH, in October 2019. He currently works on several projects concerning differential privacy, transfer learning and the usability of machine learning systems, with particular focus on the theory behind such systems. In recent years his work has been published in various top-tier conferences.
Abstract:A common problem that domain experts who are using today’s AutoML systems encounter is what we call unrealistic expectations - when users are facing a very challenging task with a noisy data acquisition process, while being expected to achieve startlingly high accuracy with machine learning. Many of these are predestined to fail from the beginning. In traditional software engineering, this problem is addressed via a feasibility study, an indispensable step before developing any software system. In practice, if these were done by human machine learning consultants, they would first analyze the representative dataset for the defined task and assess the feasibility of the target accuracy - if the target is not achievable, one can then explore alternative options by refining the dataset, the acquisition process, or investigating different task definitions. In this talk, we ask: Can we automate this feasibility study process?
We will present a system whose goal is to perform an automatic feasibility study before building machine learning applications. We approach this problem by estimating the irreducible error of the underlying task, also known as the Bayes error. Over the years, we have been conducting a series of work which provide important insights into many decisions taken when designing our system. These consist of building a novel framework for evaluating Bayes error estimators, theory behind applying feature transformation to improve the performance of certain estimators, and system optimisations that involve a multi-armed bandit approach, together with an improved version of the successive-halving algorithm under certain assumptions. We will describe each of these ingredients, culminating in end-to-end experiments that show how users are able to save substantial time and monetary efforts.
12月20日 20:00-21:00
Speaker: Shaoduo Gan and Binhang Yuan
Biography:
Shaoduo Gan has attained his PhD degree from ETH Zurich in 2021. His research is focused on distributed learning systems and the framework of machine learning. His work has been published at VLDB, SIGMOD, IEEE TPDS, ICML and NeurIPS.
Binhang Yuan is a Postdoc researcher in the Computer Science Department, ETH Zürich. He obtained his Ph.D in Computer Science from the Computer Science Department, Rice University. His research interests include database for machine learning, distributed machine learning, and recommendation systems.
Abstract:The increasing scalability and performance of distributed machine learning systems has been one of the main driving forces behind the rapid advancement of machine learning techniques. In this talk, we will introduce two recently released open source distributed learning toolkits (Bagua and Persia) developed under the collaboration between DS3Lab and Kwai Seattle AI Lab.
Bagua is a general purpose distributed data-parallel training system, which is designed to bridge the gap between the current landscapes of learning systems and optimization theory. Recent years have witnessed plenty of algorithmic design advances for data parallelism in order to lower the communication via system relaxations: quantization, decentralization, and communication delay. However, existing systems only rely on standard synchronous and asynchronous stochastic gradient (SG) based optimization, therefore, cannot take advantage of all possible optimizations that the machine learning community has been developing recently. Therefore, we build BAGUA, a MPI-style communication library, providing a collection of primitives that is both flexible and modular to support state-of-the-art system relaxation techniques of distributed training. Powered by this design, BAGUA has a great ability to implement and extend various state-of-the-art distributed learning algorithms. In a production cluster with up to 128 GPUs, BAGUA can outperform PyTorch-DDP, Horovod and BytePS in the end-to-end training time by a significant margin (up to 2 times) across a diverse range of tasks.
Persia is a distributed training system specialized for extremely large scale recommender systems. Deep learning based models have dominated the current landscape of production recommender systems. Furthermore, recent years have witnessed an exponential growth of the model scale--from Google's 2016 model with 1 billion parameters to the latest Facebook's model with 12 trillion parameters. Significant quality boost has come with each jump of the model capacity, which makes us believe the era of 100 trillion parameters is around the corner. However, the training of such models is challenging even within industrial scale data centers. This difficulty is inherited from the staggering heterogeneity of the training computation--the model's embedding layer could include more than 99.99% of the total model size, which is extremely memory-intensive; while the rest of the neural network is increasingly computation-intensive. We resolve this challenge by careful co-design of both the optimization algorithm and the distributed system architecture. Specifically, in order to ensure both the training efficiency and the training accuracy, we design a novel hybrid training algorithm, where the embedding layer and the dense neural network are handled by different synchronization mechanisms. Both theoretical demonstration and empirical study up to 100 trillion parameters have been conducted to justify the system design and implementation of Persia.
12月21日 20:00-21:00
Speaker: Jiawei Jiang and Lijie Xu
Biography:
Jiawei Jiang is now a postdoctoral researcher in the Department of Computer Science of ETH Zürich. He obtained his Ph.D in Computer Science from Peking University in 2018. His research interests include scalable machine learning, distributed optimization, and automatic machine learning.
Lijie Xu is now a postdoctoral researcher in the Department of Computer Science of ETH Zürich. He obtained his PhD degree from the Institute of Software, Chinese Academy of Sciences. His current research interests include in-database machine learning, big data systems, and distributed systems.
Abstract:How to integrate machine learning to today’s data ecosystems effectively and efficiently is a challenging problem. Today’s data ecosystems have different data storage and computation paradigms, which may degrade the ML performance and scalability if implemented on them. In this talk, we focus on integrating ML to two types of data ecosystems:
(1) ML on serverless: The appeal of serverless (FaaS) has triggered a growing interest on how to use it in data-intensive applications such as ETL, query processing, or machine learning (ML). Several systems exist for training large-scale ML models on top of serverless infrastructures (e.g., AWS Lambda) but with inconclusive results in terms of their performance and relative advantage over serverful infrastructures (IaaS). In this talk, we will present a systematic, comparative study of distributed ML training over FaaS and IaaS. We present a design space covering design choices such as optimisation algorithms and synchronization protocols, and implement a platform, LambdaML, that enables a fair comparison between FaaS and IaaS. We present experimental results using LambdaML, and further develop an analytic model to capture cost/performance tradeoffs that must be considered when opting for a serverless infrastructure. Our results indicate that ML training pays off in serverless only for models with efficient (i.e., reduced) communication and that quickly converge. In general, FaaS can be much faster but it is never significantly cheaper than IaaS.
(2) In-DB ML (DB4AI): One key problem for in-DB ML is about how to implement an effective and efficient Stochastic Gradient Descent (SGD) paradigm in DB. SGD requires random data access that is inherently inefficient when implemented in database systems that rely on block-addressable secondary storage such as HDD and SSD. In this talk, we will present a new SGD paradigm for in-DB ML with a novel data shuffling approach. Compared with existing approaches, our approach avoids a full data shuffle while maintaining a comparable convergence rate of SGD as if a full shuffle was performed. We have integrated it into PostgreSQL and openGauss, by introducing three new physical operators. The experimental results show that our approach can achieve comparable convergence rate with the full shuffle based SGD, and outperform the state-of-the-art in-DB ML tools.
12月22日 20:00-21:00
Speaker: Zeke Wang and Wenqi Jiang
Biography:
Dr. Zeke Wang is currently a research Professor, affiliated to the Artificial Intelligence Collaborative Innovation Center, School of Computer Science, Zhejiang University. In 2011, he received his Ph.D. from Zhejiang University's School of Instrumental Studies, and worked as an assistant researcher at Zhejiang University's School of Instrumental Studies from 2012 to 2013. From 2013 to 2017, he was a postdoctoral fellow at Nanyang Technological University and National University of Singapore. From 2017 to December 2019, he was a postdoctoral fellow in the Systems Group of ETH Zurich. Served as a program committee member of multiple international conferences (such as KDD) and reviewers of multiple international journals (such as TPDS, TC, TCAD).
Wenqi Jiang is a PhD student at ETH Zurich advised by Prof. Gustavo Alonso. His research is centered around improving and replacing state-of-the-art software-based systems by emerging heterogeneous hardware. To be more specific, he is exploring how reconfigurable hardware (FPGAs) can be applied and deployed in data centers efficiently. Such research ranges from application-specific designs such as recommendation systems and information retrieval systems to infrastructure development such as distributed frameworks and virtualization on the cloud.
Abstract:Various hardwares have been adopted for (distributed) machine learning, in this talk, we will first talk about some recent attempts to combine SmartNIC and FPGAs to efficiently support machine learning workflows; to be more specific, in the second half of the talk we will talk about some advances about leveraging FPGAs to accelerate the inference procedure in recommendation systems.
As Moore’s Law is about to end, the computing power of traditional CPUs cannot continue to increase rapidly, and the current network speed continues to increase rapidly, so the current CPU computing power cannot meet the requirements of the network for data processing capabilities, so we need to offload the network protocol stack to the SmartNIC to reduce the computing pressure of the server CPU; on the other hand, we can also reasonably offload some computing tasks in the Machine Learning training system to the SmartNIC to improve the overall performance of the training system. At present, ASIC-based SmartNICs can only support specific and limited application offloading; and ARM processor-based SmartNICs have very limited computing power and cannot support the offloading of complex functions. For this reason, we think that the SmartNIC based on high-end FPGA can flexibly support the Machine Learning training system. Our SmartNIC has enough computing power to allow for communication-related task offloading, such as compression/decompression.
Deep neural networks are widely used in personalized recommendation systems. Unlike regular DNN inference workloads which are typically bound by computation, recommendation inference is largely bound by memory due to the many random accesses needed to lookup the embedding tables. To this end, we first present MicroRec (MLSys'21), a high-performance FPGA inference engine for recommendation systems that tackles the memory bottleneck by both computer architecture and data structure solutions. Once the memory bottleneck is removed, the DNN computation becomes the main bottleneck again due to the limited power of computation delivered by FPGAs. Thus, we further design and implement a high-performance and heterogeneous recommendation inference cluster named FleetRec (KDD'21) that takes advantage of the strengths of both FPGAs and GPUs. Experiments on three production models up to 114 GB show that FleetRec outperforms optimized CPU baseline by more than one order of magnitude in terms of throughput while achieving significantly lower latency.
加群看直播


机动组是机器之心发起的人工智能技术社区,聚焦于学术研究与技术实践主题内容,为社区用户带来技术线上公开课、学术分享、技术实践、走近顶尖实验室等系列内容。机动组也将不定期举办线下学术交流会与组织人才服务、产业技术对接等活动,欢迎所有 AI 领域技术从业者加入。
点击阅读原文,访问机动组官网,观看往期回顾;
关注机动组服务号,获取每周直播预告。



