使用Scrapy构建可扩展Web Scraper的终极指南

快速摘要:Scrapy是一种流行的开源Python框架,用于编写可伸缩的Web scraper。在本教程中,我们将逐步引导您使用Scrapy从维基百科中收集获得奥斯卡奖的电影列表。
Web抓取是一种从网站获取数据而无需访问API或网站数据库的方法。您只需要访问网站的数据 -只要您的浏览器可以访问数据,您就可以抓取它。
实际上,大多数情况下,您可以手动浏览网站并使用复制和粘贴“手动”获取数据,但在很多情况下,您需要花费数小时的手动工作,最终您花费的成本甚至超过了数据的价值,特别是如果你雇用了其他人为你完成任务。当您可以使用每隔几秒自动执行一次查询的程序,为什么还要雇用每次查询要一两分钟的人?
例如,假设您希望编制一份获得奥斯卡最佳影片的影片名单,以及他们的导演,主演演员,发行日期和上映时间。使用Google,您可以看到几个列出这些电影名称的网站,也许还会有一些其他信息,但通常您必须通过链接来获取所需的所有信息。
显然,通过1927年到今天的每个链接来手动查找信息是不切实际和费时的。通过网络抓取,我们只需要找到一个包含所有信息页面的网站,然后用正确的指示将我们的程序指向正确的方向。
在本教程中,我们把维基百科作为我们的目标网站,因为它包含我们需要的所有信息,然后把python的Scrapy作为我们抓取信息的工具。
在我们开始之前需要注意几点:
数据抓取会导致您正在抓取的站点的服务器负载增加,这意味着托管该站点的公司的成本变高,并且该站点的其他用户的体验变差。运行网站的服务器的质量,您尝试获取的数据量,以及向服务器发送请求的速率等因素都将决定您对服务器的影响。记住这一点,我们需要确保遵守一些规则。
大多数网站的主目录中也有一个名为robots.txt的文件。此文件为不希望scraper访问的站点目录设置了规则。网站的条款和条件页面通常会让您知道他们的数据抓取政策是什么。例如,IMDB的条件页面具有以下子句:
机器人和屏幕抓取:您不得在本网站上使用数据挖掘,机器人,屏幕抓取或者类似的数据收集、提取工具,除非我们明确书面同意,如下所述。
在我们尝试获取网站数据之前,我们应该坚持查看网站的条款和robots.txt来确保我们获取合法数据。在构建我们的scraper时,我们还要确保我们不会使用无法处理的请求,避免压倒服务器。
幸运的是,许多网站认识到用户有获取数据的需求,并且他们通过API提供数据。如果这些可用,通过API获取数据通常比通过抓取更容易。
维基百科允许数据抓取,只要机器人不“太快”,就像他们robots.txt里面所说的那样。它们还提供可下载的数据集,以便人们可以在自己的机器上处理数据。如果我们抓取得太快,服务器将自动阻止我们的IP,所以我们将实现定时器来保证机器人遵守其规则。
入门,使用Pip安装相关的库
首先,开始吧,让我们安装Scrapy
WINDOWS
从https://www.python.org/downloads/windows/安装最新版本的Python
注意:Windows用户还需要Microsoft Visual C ++ 14.0,您可以从此处获取“Microsoft Visual C ++ Build Tools” 。
您还需要确保拥有最新版本的pip。
在cmd.exe中,键入:

这将自动安装Scrapy和所有依赖项。
LINUX
首先,您需要安装所有依赖项:
在终端中,输入:

一旦安装完毕,只需输入:

要确保更新pip,然后:

这一切都完成了。
MAC
首先,您需要确保系统上有c编译器。在终端中,输入:

之后,从https://brew.sh/安装自制软件。
更新PATH变量,以便在系统软件包之前使用自制软件包:

安装Python:

然后确保一切都更新:

完成后,只需使用pip安装Scrapy:

Scrapy概述,如何拼凑各部分,解析器,蜘蛛等
您将用Scrapy编写一个名为'蜘蛛'的脚本,并运行它,但不要担心,Scrapy蜘蛛一点也不可怕尽管它名字叫蜘蛛。Scrapy蜘蛛和真正的蜘蛛唯一的相似之处就是他们都喜欢在网上爬行。
蜘蛛内部是您定义的class,它告诉Scrapy该做什么。例如,从何处开始爬网,它所做的请求类型,如何跟踪页面上的链接以及如何解析数据。在数据输到文件之前,您甚至可以添加自定义函数来处理数据。
编写你的第一个蜘蛛,写一个简单的蜘蛛,允许动手学习
开始编写我们的第一个蜘蛛,首先我们需要创建一个Scrapy项目。为此,请在命令行中输入:

这将为您的项目创建一个文件夹。
我们将从一个基本的蜘蛛开始。将以下代码输入到python脚本中。在文件夹/oscars/spiders中新建一个新的python脚本并命名为oscars_spider.py
我们导入Scrapy:

然后我们开始定义我们的Spider类。首先,我们设置名称,然后设置允许蜘蛛爬取的域名。最后,我们告诉蜘蛛从哪里开始爬取。

接下来,我们需要一个能捕获我们想要的信息的函数。现在,我们只是抓住页面标题。我们使用CSS来查找带有标题文本的标签,然后我们将其提取出来。最后,我们将信息返回给Scrapy以记录或写入文件。
现在保存在 /oscars/spiders/oscars_spider.py里的代码
要运行此蜘蛛,只需转到命令行并键入:
你应该看到这样的输出:
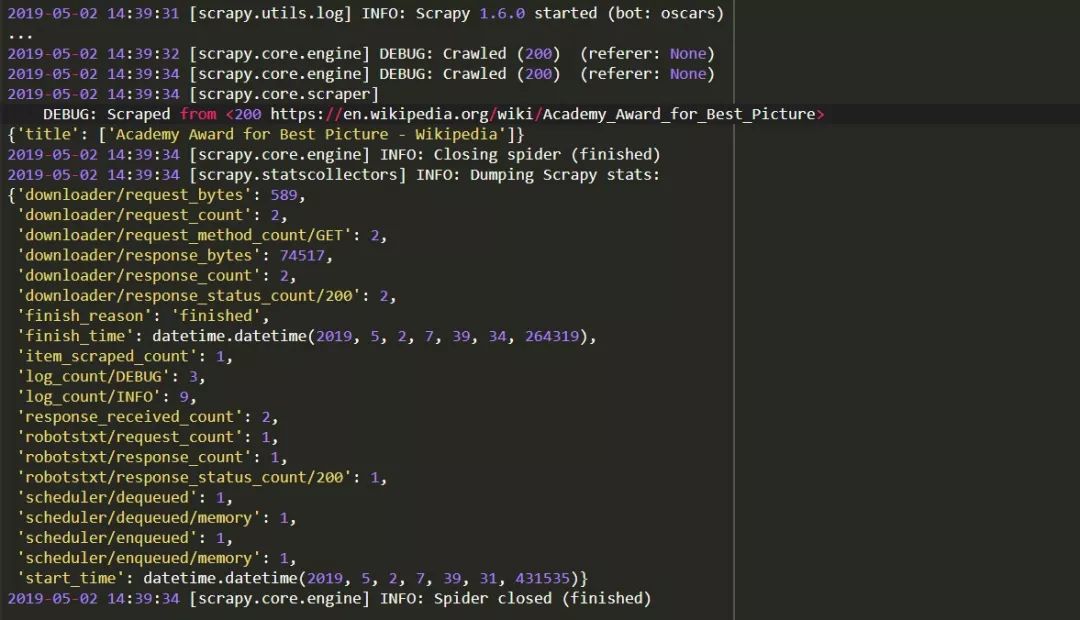
恭喜你,你已经建立了你的第一个基本的Scrapy scraper!
完整代码:
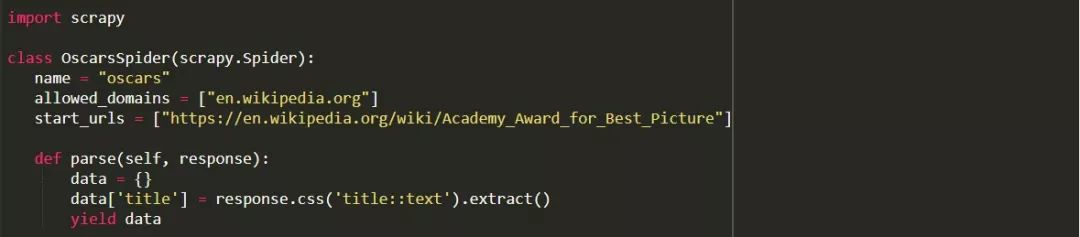
显然,我们希望它做得更多,所以让我们看一下如何使用Scrapy来解析数据。
首先,让我们熟悉一下Scrapy shell。Scrapy shell可以帮助您测试代码,以确保Scrapy正在抓取您想要的数据。
要访问shell,请在命令行中输入:

这基本上是打开您所指向的页面,它允许您运行单行代码。例如,您可以通过键入以下内容来查看页面的原始HTML:

或者通过输入以下内容在默认浏览器中打开页面:

我们的目标是找到包含我们想要的信息的代码。现在,让我们尝试仅获取电影标题名称。
找到我们需要的代码的最简单方法是在浏览器中打开页面并检查代码。在此示例中,我使用的是Chrome DevTools。只需右键单击任何电影标题,然后选择“检查”:
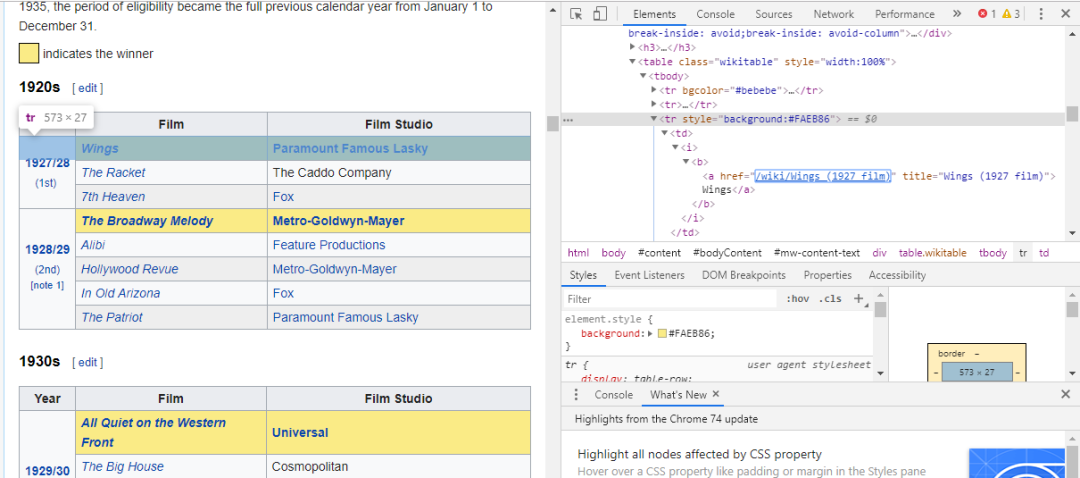
正如你所看到的,奥斯卡获奖者有黄色背景,而被提名者只有一个简单的背景。这还有关于电影标题的文章的链接,以及以film)为结束标记的电影链接。现在我们知道了这一点,我们可以使用CSS选择器来获取数据。在Scrapy shell中,输入:

如您所见,您现在拥有所有奥斯卡最佳影片获奖者名单!

回到我们的主要目标,我们想要一份奥斯卡最佳影片获奖者名单,以及他们的导演,主演演员,发行日期和上映时间。为此,我们需要Scrapy从每个电影页面中获取数据。
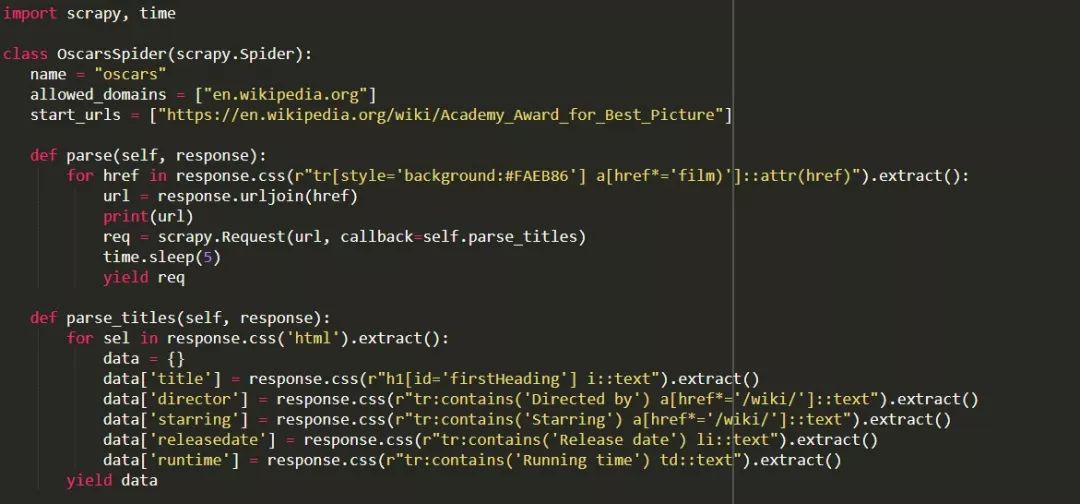
我们必须重写一些东西并添加一个新函数,但不要担心,它非常简单。
我们将以与以前相同的方式启动scraper。

但这一次,两件事情会发生变化。首先,我们将导入time和scrapy,因为我们想创建一个计时器来限制机器人的爬取速度。此外,当我们第一次解析页面时,我们只想获得一个有每个标题链接的列表,这样我们就可以从这些页面获取信息。

在这里,我们创建一个循环来查找页面中每一个以film)结尾、带有黄色背景的链接,然后我们将这些链接一起加入到URL列表中,我们将其发送到parse_titles函数以进一步传递。我们也会在计时器中输入它,每5秒钟只能请求一次页面。请记住,我们可以使用Scrapy shell来测试我们的response.css字段,以确保我们获得正确的数据!

真正的工作在我们的parse_data函数中完成,我们在其中创建一个名为data的字典,然后用我们想要的信息填充每个键。同样,所有这些选择器都是使用Chrome DevTools发现的,如前所示,然后使用Scrapy shell进行测试。
最后一行将数据字典返回Scrapy进行存储。
完整代码:
有时我们会想要使用代理,因为网站会试图阻止我们的抓取尝试。
要做到这一点,我们只需要改变一些事情。使用我们的示例,在我们中def parse(),我们需要将其更改为以下内容:

这将通过您的代理服务器发送请求。
部署和记录,显示如何管理实际生产中的蜘蛛
现在是时候运行我们的蜘蛛了。要使Scrapy开始抓取,然后输出到CSV文件,请在命令提示符中输入以下内容:

您将看到一个大输出,几分钟后,它将完成,您的项目文件夹中会有一个CSV文件。
编译结果,显示如何使用前面步骤中编译的结果
当您打开CSV文件时,您将看到我们想要的所有信息(按标题列排序)。这真的很简单。
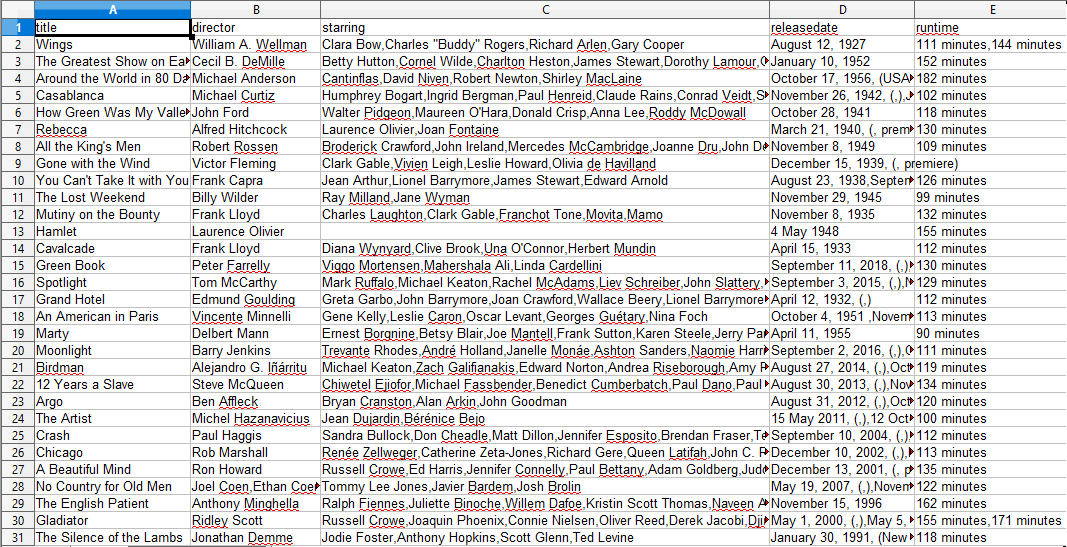
通过数据抓取,我们几乎可以获得我们想要的任何自定义数据集,只要信息是公开可用的。您想要对此数据做什么取决于您。此技能对于做市场调查,更新网站信息以及许多的其他内容非常有用。
设置自己的Web scraper以获取自己的自定义数据集,这相当容易,但是,请始终记住,可能还有其他方法可以获取所需的数据。企业在提供您想要的数据方面投入了大量资金,因此我们尊重他们的条款和条件是公平的
英文原文:https://www.smashingmagazine.com/2019/07/ultimate-guide-scalable-web-scrapers-scrapy/
译者:ZH





