引入鲁棒性作为连续参数,这种新的损失函数实现了自适应、随时变换
作者:Saptashwa Bhattacharyya
机器之心编译
编辑:陈萍
损失函数是机器学习里最基础也是最为关键的一个要素,其用来评价模型的预测值和真实值不一样的程度。最为常见的损失函数包括平方损失、指数损失、log 对数损失等损失函数。这里回顾了一种新的损失函数,通过引入鲁棒性作为连续参数,该损失函数可以使围绕最小化损失的算法得以推广,其中损失的鲁棒性在训练过程中自动自我适应,从而提高了基于学习任务的性能。


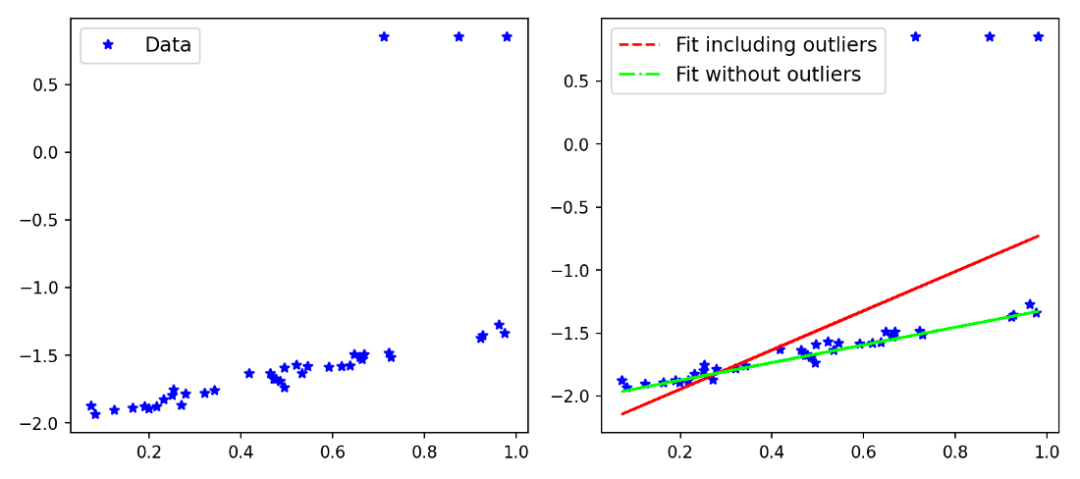
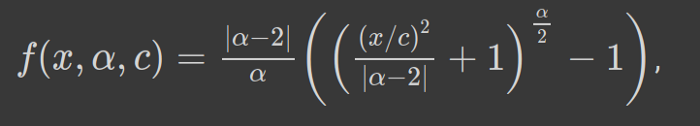


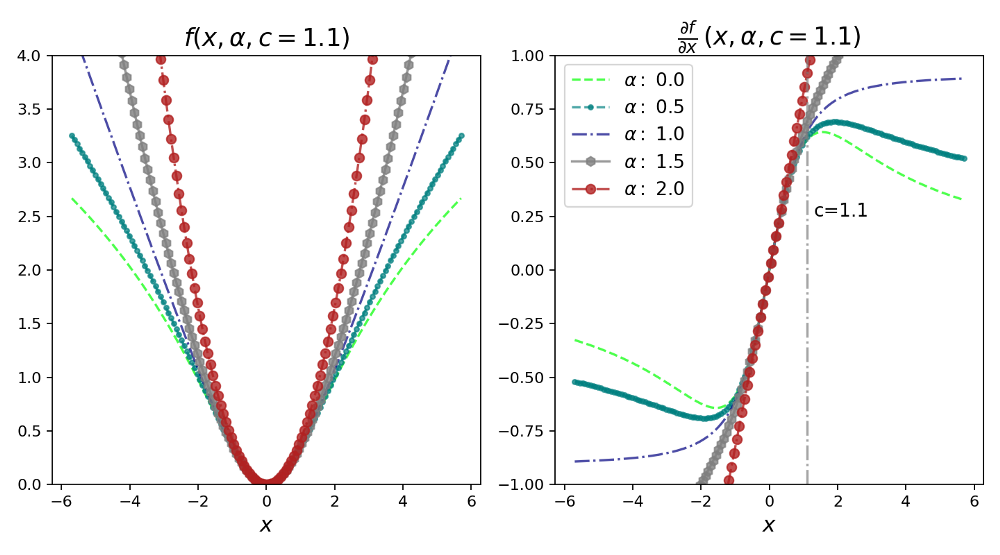
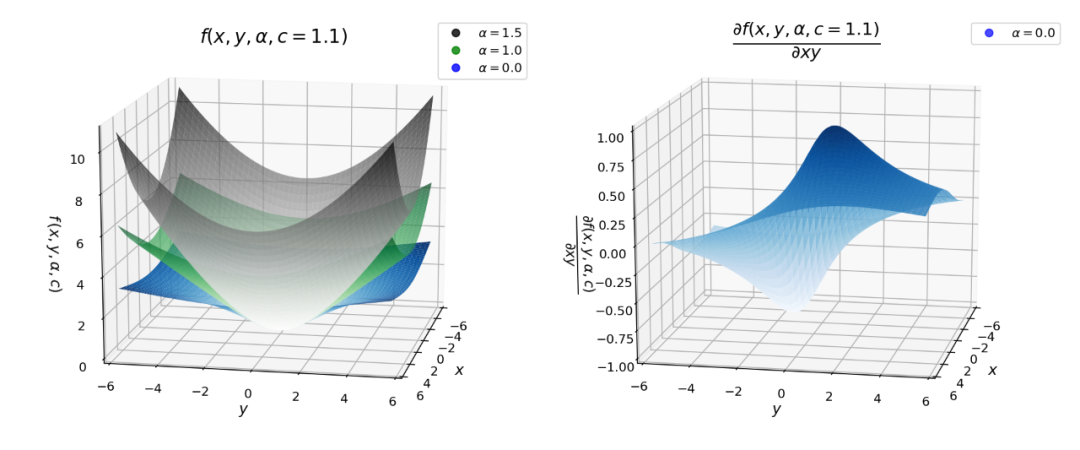
!pip install git+https://github.com/jonbarron/robust_loss_pytorch
import robust_loss_pytorch
import numpy as np
import torch scale_true = 0.7
shift_true = 0.15
x = np.random.uniform(size=n)
y = scale_true * x + shift_true
y = y + np.random.normal(scale=0.025, size=n) # add noise
flip_mask = np.random.uniform(size=n) > 0.9
y = np.where(flip_mask, 0.05 + 0.4 * (1. — np.sign(y — 0.5)), y)
# include outliers
x = torch.Tensor(x)
y = torch.Tensor(y)
class RegressionModel(torch.nn.Module):
def __init__(self):
super(RegressionModel, self).__init__()
self.linear = torch.nn.Linear(1, 1)
## applies the linear transformation.
def forward(self, x):
return self.linear(x[:,None])[:,0] # returns the forward pass
regression = RegressionModel()
params = regression.parameters()
optimizer = torch.optim.Adam(params, lr = 0.01)
for epoch in range(2000):
y_i = regression(x)
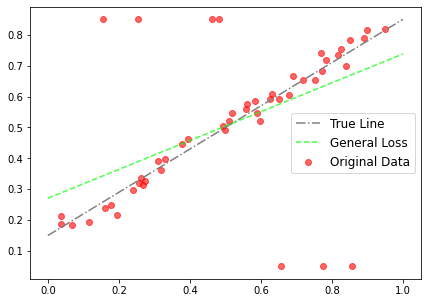
# Use general loss to compute MSE, fixed alpha, fixed scale.
loss = torch.mean(robust_loss_pytorch.general.lossfun(
y_i — y, alpha=torch.Tensor([2.]), scale=torch.Tensor([0.1])))
optimizer.zero_grad()
loss.backward()
optimizer.step()
regression = RegressionModel()
adaptive = robust_loss_pytorch.adaptive.AdaptiveLossFunction(
num_dims = 1, float_dtype=np.float32)
params = list(regression.parameters()) + list(adaptive.parameters())
optimizer = torch.optim.Adam(params, lr = 0.01)
for epoch in range(2000):
y_i = regression(x)
loss = torch.mean(adaptive.lossfun((y_i — y)[:,None]))
# (y_i - y)[:, None] # numpy array or tensor
optimizer.zero_grad()
loss.backward()
optimizer.step()
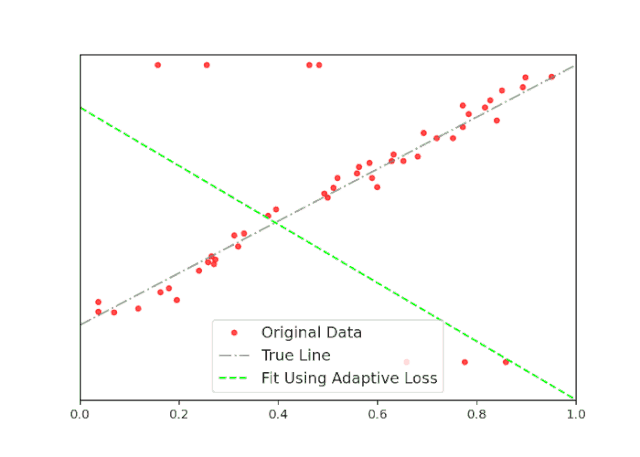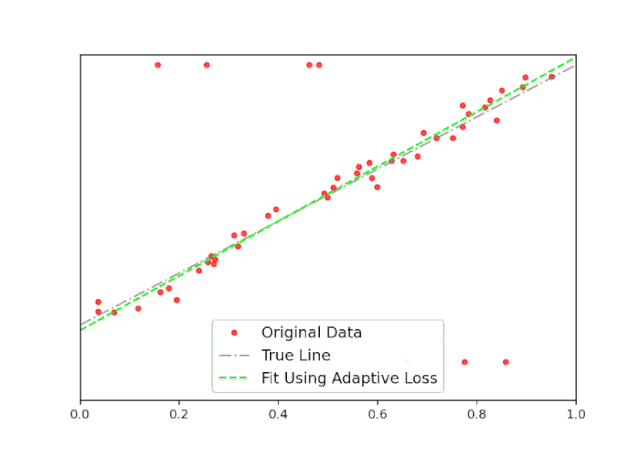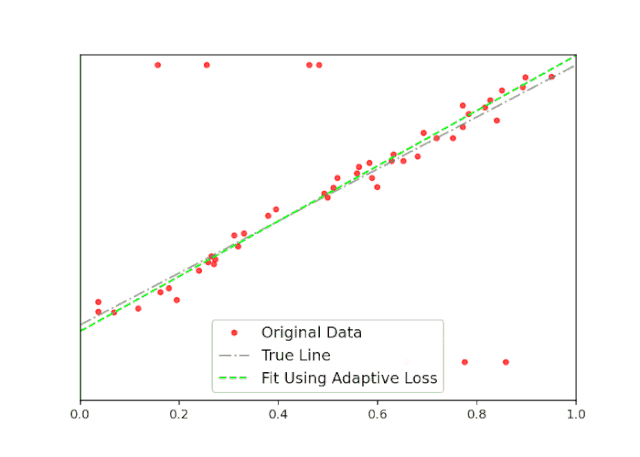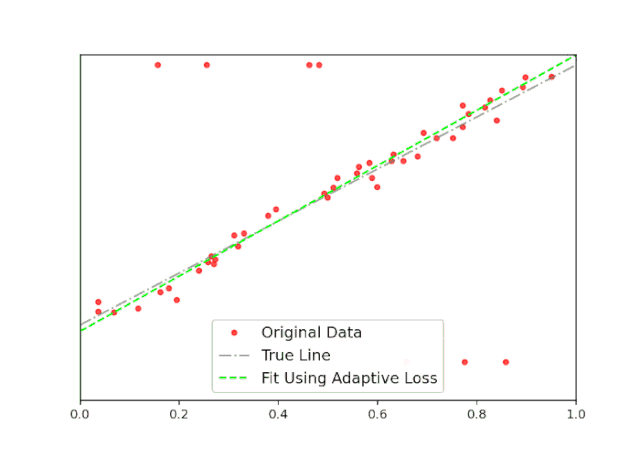
Amazon SageMaker实战教程(视频回顾)
Amazon SageMaker 是一项完全托管的服务,可以帮助机器学习开发者和数据科学家快速构建、训练和部署模型。Amazon SageMaker 完全消除了机器学习过程中各个步骤的繁重工作,让开发高质量模型变得更加轻松。
10月15日-10月22日,机器之心联合AWS举办3次线上分享,全程回顾如下:

视频回顾地址:https://app6ca5octe2206.h5.xiaoeknow.com/v1/course/alive/l_5f715443e4b005221d8ea8e3

视频回顾地址:https://app6ca5octe2206.h5.xiaoeknow.com/v1/course/alive/l_5f715d38e4b0e95a89c1713f

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
登录查看更多
相关内容
专知会员服务
25+阅读 · 2020年3月26日
专知会员服务
35+阅读 · 2019年12月12日


相关VIP内容
专知会员服务
25+阅读 · 2020年3月26日
专知会员服务
35+阅读 · 2019年12月12日
相关资讯
相关论文