特征筛选还在用XGB的Feature Importance?试试Permutation Importance

©作者 | 刘秋言
研究方向 | 机器学习
本文目录
模型默认的 Feature Importance 存在什么问题?
什么是 Permutation Importance?
它的优劣势是什么?
Amex 数据实例验证

模型默认的Feature Importance存在什么问题?

什么是Permutation Importance?
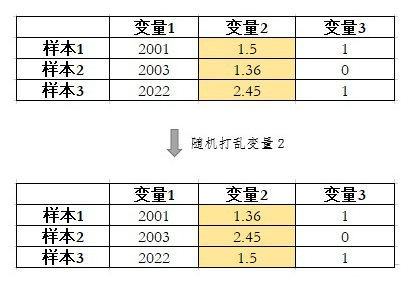
-
1. 将数据分为 train 和 validation 两个数据集 -
2. 在 train 上训练模型,在 validation 上做预测,并评价模型(如计算 AUC) -
3. 循环计算每个变量的重要性: -
(3.1) 在 validation 上对单个变量随机打乱; -
(3.2)使用第 2 步训练好的模型,重新在 validation 做预测,并评价模型; (3.3)计算第 2 步和第 3.2 步 validation 上模型评价的差异,得到该变量的重要性指标
def permutation_importances(model, X, y, metric):
baseline = metric(model, X, y)
imp = []
for col in X.columns:
save = X[col].copy()
X[col] = np.random.permutation(X[col])
m = metric(model, X, y)
X[col] = save
imp.append(baseline - m)
return np.array(imp)

Permutation Importance的优劣势是什么?
3.1 优势
-
可以在任何模型上使用。不只是在基于决策树的模型,在线性回归,神经网络,任何模型上都可以使用。 -
不存在对连续型变量或高基数类别型变量的偏好。 -
体现了变量的泛化能力,当数据发生偏移时会特别有价值。 相较于循环的增加或剔除变量,不需要对模型重新训练,极大地降低了成本。但是循环地对模型做预测仍然会花费不少时间。
3.2 劣势
-
对变量的打乱存在随机性。这就要求随机打乱需要重复多次,以保证统计的显著性。 对相关性高的变量会低估重要性,模型默认的 Feature Importance 同样存在该问题。

Amex数据实例验证

-
模型默认的 Feature Importance -
Permutation Importance 标准化后的 Permutation Importance:Permutation Importance / 随机 100 次的标准差。这考虑到了随机性。如果在 Permutation Importance 差不多的情况下,标准差更小,说明该变量的重要性结果是更稳定的。
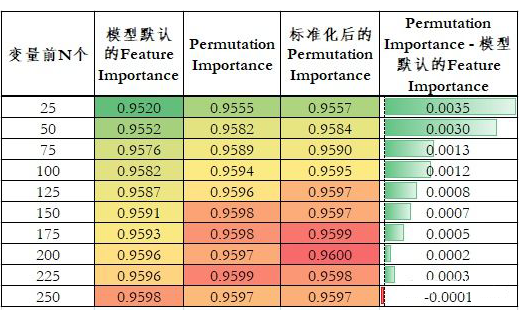
-
Permutation Importance 相较于模型默认的 Feature Importance 具有更好的排序性。当变量个数小于 250 个时,使用 Permutation Importance 排序的变量模型效果都更好。 -
随着变量个数的增加,模型默认的 Feature Importance 和 Permutation Importance 两种排序的模型 AUC 差异逐渐减小。这也间接说明 Permutation Importance 的重要性排序更好。因为在变量个数少的时候,两种排序筛选的变量差异会更大。随着变量的增加,两种排序下变量的重合逐渐增加,差异逐渐减小。 标准化后的 Permutation Importance 效果仅略微好于 Permutation Importance,这在真实业务场景意义较低,在建模比赛中有一定价值。

参考文献
[1] Breiman, Leo.“Random Forests.” Machine Learning 45 (1). Springer: 5-32 (2001).
[2] Fisher, Aaron, Cynthia Rudin, and Francesca Dominici. “All models are wrong, but many are useful: Learning a variable’s importance by studying an entire class of prediction models simultaneously.” http://arxiv.org/abs/1801.01489 (2018).
[3] Strobl C, et al. Bias in random forest variable importance measures: Illustrations, sources and a solution, BMC Bioinformatics, 2007, vol. 8 pg. 25
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编





