ICLR 2019 | 与胶囊网络异曲同工:Bengio等提出四元数循环神经网络
选自 openreview
作者:Titouan Parcollet
机器之心编译
近日,Yoshua Bengio 等人提出了一种新型的循环神经网络,其以四元数来编码序列输入,称为四元循环神经网络。四元数神经网络是流形网络和胶囊网络之外又一种非同构表征架构,也可以看成是实值、复值 RNN 的扩展。实验表明,该网络相比传统的实值 RNN 可以显著减少参数数量,适用于低资源应用。相关论文已被 ICLR 2019 接收,评审得分为 7、7、8。
在该论文的 ICLR 2019 双盲评审页面中,一位评审写道:
本文通过探索在循环神经网络中使用四元数,朝着开发更加结构化的表征迈出了一大步。其思想的动机是观察到在许多情况下,向量元素之间存在的局部关系应该得到明确表征。这也是胶囊网络背后的思想:让每个「单元」输出一个参数向量而不是一个数字。在这里,作者表明,通过将四元数结合到 RNN 或 LSTM 使用的表征中,可以使用更少的参数在语音识别任务中实现更好的性能。
引言
由于具备学习高度复杂的输入到输出映射的能力,在过去的几年里,深度神经网络(DNN)在多个领域取得了广泛的成功。在各种基于 DNN 的模型中,循环神经网络(RNN)非常适合处理序列数据,它在每个时间步上创建一个向量,用来编码输入向量之间的隐藏关系。深度 RNN 近来被用来获取语音单元序列(Ravanelli et al., 2018a)或文本词序列(Conneau et al., 2018)的隐藏表征,在许多语音识别任务中取得了当前最佳性能(Graves et al., 2013a;b; Amodei et al., 2016; Povey et al., 2016; Chiu et al., 2018)。然而,最近的许多基于多维输入特征的任务(如图像的像素、声学特征或 3D 模型的方向)需要同时表征不同实体之间的外部依赖关系和组成每个实体的特征之间的内部关系。而且,基于 RNN 的算法通常需要大量参数才能表征隐藏空间中的序列数据。
四元数是一种包含实数和三个独立的虚分量的超复数,完全适用于三维和四维特征向量,如图像处理和机器人运动学(Sangwine, 1996; Pei & Cheng, 1999; Aspragathos & Dimitros, 1998)。最近的流形网络和胶囊网络也探索了将成组数字创建为独立实体的想法(Chakraborty et al., 2018; Sabour et al., 2017)。与传统的同构表征相反,胶囊网络和四元网络将特征集捆绑在一起。因此,四元数允许基于神经网络的模型在学习过程中,以比 RNN 更少的参数编码输入特征组之间的潜在依赖关系,利用 Hamilton 乘积代替普通乘积,但这个乘积是四元数之间的。四元数值反向传播算法的早期应用(Arena et al., 1994; 1997)有效地解决了四元数函数逼近任务。最近,复数和超复数神经网络受到越来越多的关注(Hirose & Yoshida, 2012; Tygert et al., 2016; Danihelka et al., 2016; Wisdom et al., 2016),一些研究已经在不同的应用中得到了颇有前景的结果。深度四元网络(Parcollet et al., 2016; 2017a;b)、深度四元卷积网络(Gaudet & Maida, 2018; Parcollet et al., 2018)或深度复杂卷积网络(Trabelsi et al., 2017)已经应用于图像、语言处理等颇具挑战性的任务。然而,这些应用不包括运算由四元代数决定的循环神经网络。
本文提出将局部谱特征整合到四元循环神经网络(QRNN)及其门控型扩展即四元长短期记忆网络(QLSTM)中。该模型结合了良好的参数初始化方案而提出,经证实其可以学习多维输入特征和参数较少的序列基本元素之间的相互依赖性和内部依赖性,使该方法更适用于低资源应用。QRNN 和 QLSTM 的有效性是在实际的 TIMIT 音素识别任务上进行评估的,结果表明 QRNN 和 QLSTM 都获得了比 RNN 和 LSTM 更好的性能,且获得的最佳音素错误率(PER)分别为 18.5% 和 15.1%,而 RNN 和 LSTM 分别为 19.0% 和 15.3%。此外,它们在获得性能提升的情况下,自由参数量减少了 70%。在更大的数据集——Wall Street Journal (WSJ) 上也观察到类似的结果,其详细性能参见附录 6.1.1。
论文:QUATERNION RECURRENT NEURAL NETWORKS

论文链接:https://openreview.net/pdf?id=ByMHvs0cFQ
摘要:循环神经网络是建模序列数据的强大架构,因为它能够学习序列基本元素之间的长短期依赖。然而,如语音或图像识别等流行任务都涉及多维输入特征,这些特征的特点在于输入向量的维度之间具有很强的内部依赖性。本文提出一种新的四元循环神经网络(QRNN)以及相应的四元长短期记忆网络(QLSTM),将四元代数的外部关系和内部架构依赖性皆考虑在内。与胶囊网络类似,四元数允许 QRNN 通过将多维特征整合和处理为单个实体来编码内部依赖性,而循环操作建模了组成序列的元素之间的相关性。实验证明,与 RNN 和 LSTM 相比,QRNN 和 QLSTM 都在自动语音识别的实际应用中达到了更好的性能。最后作者表明,为了获得更好的结果,与实值 RNN 和 LSTM 相比,QRNN 和 QLSTM 最大限度地减少了所需的自由参数量(减少了 70%),从而使相关信息的表征更加紧凑。
3 四元循环神经网络
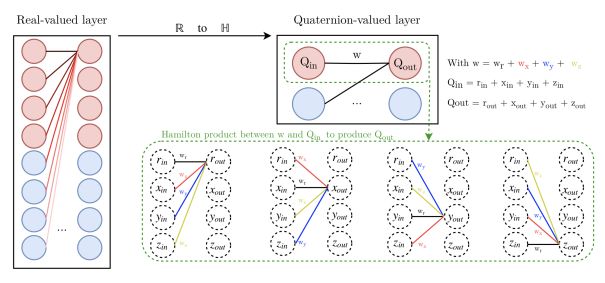
图 1:基于 Hamilton 乘积(等式 5)的四元权重共享,与标准实值层(左)相比,四元值层(右)的输入特征(Qin)潜在关系学习能力图示。
3.2 四元数表征
QRNN 是实值和复值 RNN 到超复数的扩展。在一个四元数密集层中,所有的参数都是四元数,包括输入、输出、权重和偏置。四元数代数通过操作实值矩阵实现。因此,对于大小为 N 的每个输入向量和大小为 M 的输出向量,维度被分离为四个部分:第一个等于 r,第二个等于 x_i,第三个等于 y_j,最后一个等于 z_k,从而构成一个四元数 Q = r1 + xi + yj + zk。全连接层的推断过程通过一个输入向量和一个实值 MxN 权重矩阵之间的点积在实值空间中定义。在一个 QRNN 中,这种运算由带四元数值矩阵的哈密顿乘积取代(即权重矩阵中的每一项都是四元数)。
3.3 学习算法
QRNN 在每个学习子过程中都不同于实值的 RNN。因此,令 x_t 为 t 时间步的输入向量,h_t 为隐藏状态,W_hx、W_hy、W_hh 为输入、输出和隐藏状态权重矩阵。向量 b_h 是隐藏状态的偏差,p_t、y_t 是输出以及期望目标向量。
基于实值 RNN 的前向传播,QRNN 的前向方程扩展如下:
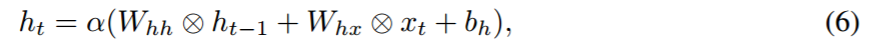
其中α是四元数分离的激活函数,定义为:
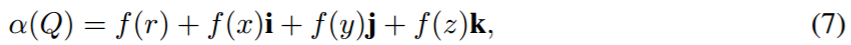
f 对应任意标准的激活函数。基于先验假设、更好的稳定性(即,纯四元数激活函数包含奇点)和更简单的计算,本研究偏向于使用分离方法。输出向量 p_t 计算如下:

其中β是任意的分离激活函数。最后目标函数是经典 component-wise 的损失函数(例如,均方误差、负对数似然度)。
反向传播的梯度计算公式如下:
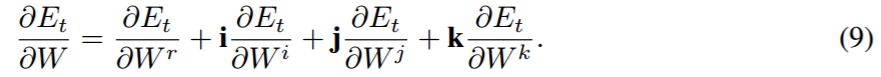
权重更新公式如下:
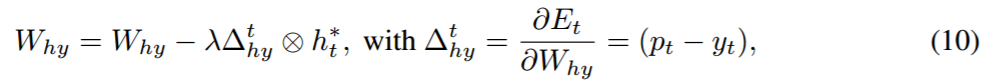
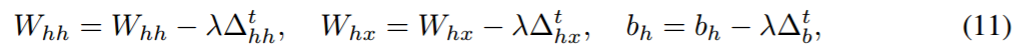
4 实验
这一节详细描述了声学特征提取、实验设置,以及用 QRNN、QLSTM、RNN 和 LSTM 在 TIMIT 语音识别任务上获得的结果。表格中粗体标记的结果是使用在验证集中表现最佳的神经网络配置获得的。
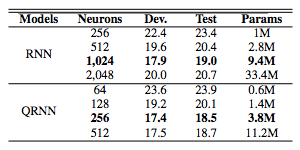
表 1:QRNN 和 RNN 模型在 TIMIT 数据集的开发集和测试集上的音素误差率(PER%)。「Params」代表可训练参数的总数量。
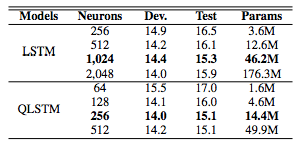
表 2:QLSTM 和 LSTM 模型在 TIMIT 数据集的开发集和测试集上的音素误差率(PER%)。「Params」代表可训练参数的总数量。
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



