【深度学习基础】5. Long Short Term Memory


如今深度学习如火如荼,各种工具和平台都已经非常完善。各大训练平台比如 TensorFlow 让我们可以更多的聚焦在网络定义部分,而不需要纠结求导和 Layer 的内部组成。本系列我们来回顾一下深度学习的各个基础环节,包括线性回归,BP 算法的推导,卷积核和 Pooling,循环神经网络,LSTM 的 Memory Block 组成等,全文五篇,前三篇是斯坦福深度学习 wiki 整理,第四第五两篇是 Alex Graves 的论文读书笔记,图片来自网络和论文,有版权问题请联系我们。

如之前所述,RNN 最大的好处是可以利用上下文信息对输入和输出进行建模。但是标准的 RNN 网络,对上下文能够利用的序列长度实际上是有上限的,主要表现在随着前期的输入不断在网络中递归,其对隐藏层和对输出层的影响(这里可以理解为对梯度的贡献),要么衰减到没有了,要么指数级的爆炸了。在实际应用的过程中,这种梯度衰减的影响,使得标准 RNN 基本上只能做 10 个 timestep 以内的序列建模。
我们把这种影响,称为 vanishing gradient 。示意图如下,颜色深浅表达对梯度的贡献,随着序列往后移,前期输入数据产生的梯度的影响越来越弱,基本上后面就没有了:
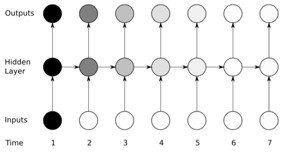
针对这个问题,有很多种改进方案,其中最有效的是 LSTM(Long Short Term Memory)。
LSTM 本质上仍然是一种类 RNN 的递归神经网络结构,只不过处理的单元不再是简单的一个 summation hidden unit(直接对输入加权求和后调用激活函数产生输出),而是一个叫 memory block 的结构。这一点很重要,同一个隐藏层的所有的 memory block 之间是平行的,他们相互之间也是能全连接的(主要体现在前后两个 timestep 之间的递归关系)。类似之前的 summation hidden unit ,可以认为是把 summation unit 扩展成了更复杂的 memory block 。其他的可以认为跟标准 RNN 并没用太多变化,甚至他们可以混合在一起使用。而且标准 RNN 的输出层也不需要做任何变更就可以直接使用。
现在对单一 memoryblock 展开,一个 block 里面包含至少一个 memory cell ,以及三个乘法单元:输入门、输出门、忘记门。这三个门分别模拟对 memory cell 的写、读、重置操作。下图是 LSTM memory block 的示意图,内含一个 memory cell ,和三个 gate 。大圆圈内的操作表示要对输入进行 sigmoid 变换,f 表示 logistic,g 和 h 表示 tanh ,当然也可以是 logistic :
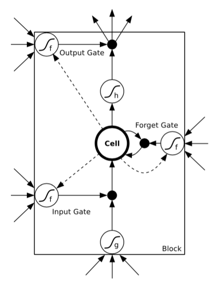
为了更好的理解上述三个门的作用,我们先列出 LSTM unfold 之后的效果:
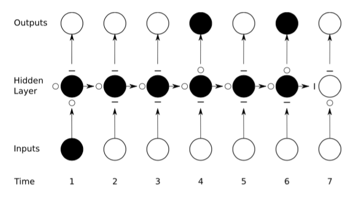
由于 gate 的激活函数是 logistic sigmoid ,所以输出范围是 (0,1) ,0可以认为门要关闭,1 表示门打开,并通过乘法操作作用到相关输出上。举个例子,如果输入门(input gate)持续接近于 0,memory cell 中 input 这部分的输入影响会非常小,它在这个 timestep 的激活值不会被新的输入给覆盖掉(overwrite)。上图中
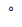
正是借助 memory cell 和上述三个门,可以实现比较长周期的序列输入记忆功能。
LSTM 已经在很多需要长时依赖的合成任务中取得了不错的效果,比如学习长文本的上下文,在实际应用中能解决很多标准 RNN 无法解决的问题。
用一个实际的图来对比标准 RNN 和 LSTM 在 vanishing gradient 问题上的结果,途中的噪声表示梯度的值。可以明显看出 LSTM 对梯度的传递可以更加持久:

最后补一个图,是同一个 hidden layer 不同的 LSTM memory block 之间的递归关系示意图:
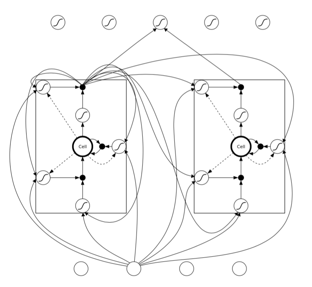
有了之前 RNN 的基础,相信大家应该看的明白。这个图同一层的递归调用关系,实际上是不同 timestep 之间的连接。展开为 RNN 的 unfold 的示意图比较好理解。
讲了LSTM这么多的好处,其实我们忽略了一点:如果我把比较长的输入序列数据预先处理一次,变为比较短的序列数据,也就是对input-output的建模只需要做短时依赖的话,其实可以不用LSTM这么复杂的。
比如一些时序数据,通过调整采样或者一些信号处理的方法,可以把数据进行压缩,变成一个相对短的时序数据,然后用一些短时依赖的模型也是可以取得好的效果。
但是不管怎么说,这种预处理有时候比较麻烦,或者根本不知道如何预处理,或者干脆就不想对原始输入做任何任务相关的预处理,而且有时候此类预处理会带来数据的精度损失,那么一个能处理长时依赖的模型还是很有必要的。
LSTM的数学表达和编程实现
LSTM也是可导的,因此可以用梯度下降的方法来进行训练。它的后向反馈可以用之前提到的BPTT算法来进行梯度更新。但是由于LSTM的memory block包含三个门,BPTT在反馈的时候要对这三个门分别进行梯度更新。公式比较多,我们这里就不详细列出反馈过程了,感兴趣的可以找本LSTM的参考文献详细看看。
我们重点描述LSTM的前馈过程,因为很多symbol编程的Deep Learning框架需要我们编写forward的公式以及编程实现,而backward是可以自动求导的。
下面的公式中,都是把input summation以及activation过程单独列出,a是summation的结果,b是activation的结果。为了方便讲解把两个图放在一起对照。公式中之所以写Cell Output而不是Block Output,主要是因为一个Block可能包含多余1个的Cell,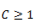
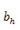
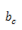
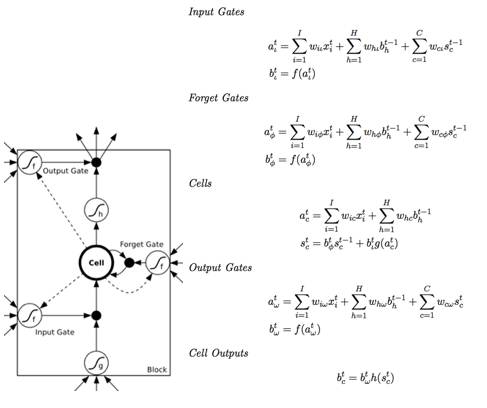
Input Gate
输入:本时刻的所有前一层输入 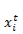
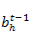
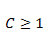
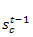
输出:输入加权求和的f激活函数结果(logistic)
Forget Gate
输入:本时刻的所有前一层输入
输出:输入加权求和的f激活函数结果(logistic)
Memory Cell
输入:a)本时刻的所有前一层输入 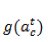
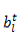
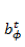
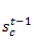
输出:上述两项输入部分直接求和,无需额外激活函数。
Output Gate
输入:本时刻的所有前一层输入 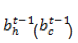
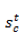
输出:输入加权求和的f激活函数结果(logistic)
Cell Output
输出:本时刻的Cell状态计算h(tanh)激活函数的结果 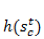
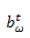
实际编程过程中,不同的应用LSTM的Memory Block如何构建,门的输入是否需要调整,都会带来很大的影响,要根据应用来进行调整。比如对Memory Block中的虚线部分,也就是公式中各个Gate中关于Cell State的第三项,MXNet的LSTM example代码,就没有包含着一部分。但是在其他应用场景,可能加上这部分后效果就截然不同。所以LSTM的变种问题就很值得深入研究。

 微信ID:WeChatAI
微信ID:WeChatAI
 长按左侧二维码关注
长按左侧二维码关注
登录查看更多
相关内容

Arxiv
16+阅读 · 2018年1月31日




相关VIP内容
相关资讯
相关论文
Arxiv
16+阅读 · 2018年1月31日