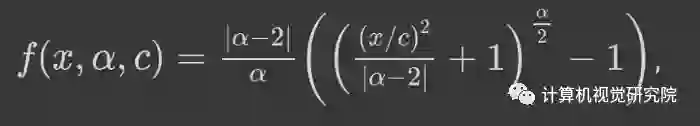————————计算机视觉研究院专栏————————
![]()
![]()
扫描二维码 关注我们
微信公众号 : 计算机视觉研究院
回复“鲁棒性”获取论文集下载
知乎专栏:计算机视觉战队
损失函数是机器学习里最基础也是最为关键的一个要素,其用来评价模型的预测值和真实值不一样的程度。最为常见的损失函数包括平方损失、指数损失、log 对数损失等损失函数。这里回顾了一种新的损失函数,通过引入鲁棒性作为连续参数,该损失函数可以使围绕最小化损失的算法得以推广,其中损失的鲁棒性在训练过程中自动自我适应,从而提高了基于学习任务的性能。
![]()
下面分享的文章对 CVPR 2019 的一篇论文《A General and Adaptive Robust Loss Function》进行了回顾性综述,主要讲述了为机器学习问题开发鲁棒以及自适应的损失函数。论文作者为谷歌研究院的研究科学家 Jon Barron。
![]() 异常值(Outlier)与鲁棒损失
异常值(Outlier)与鲁棒损失
考虑到机器学习问题中最常用的误差之一——
均方误差
(Mean Squared Error, MSE),其形式为:(y-x)²。该损失函数的主要特征之一是:与小误差相比,对大误差的敏感性较高。并且,使用MSE训练出的模型将偏向于减少最大误差。例如,3个单位的单一误差与1个单位的9个误差同等重要。
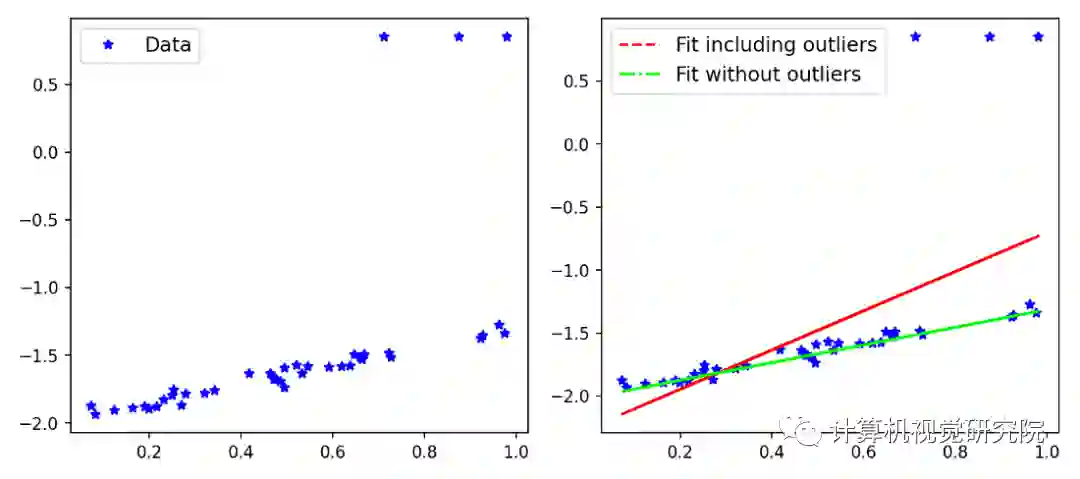
下图为使用Scikit-Learn创建的示例,演示了在有/无异常值影响的情况下,拟合是如何在一个简单数据集中变化的。
![]()
如上图所示,包含异常值的拟合线(fit line)受到异常值的较大影响,但是优化问题应要求模型受内点(inlier)的影响更大。在这一点上,你可能认为平均绝对误差(Mean Absolute Error, MAE)会优于 MSE,因为 MAE 对大误差的敏感性较低。也不尽然。目前有各种类型的鲁棒损失(如 MAE),对于特定问题,可能需要测试各种损失。
所以,这篇论文引入一个泛化的损失函数
,其鲁棒性可以改变,并且可以在训练网络的同时训练这个超参数,以提升网络性能。与网格搜索(grid-search)交叉验证
寻找最优损失函数
相比,这种损失函数
花费的时间更少。让我们从下面的几个定义开始讲解:
![]()
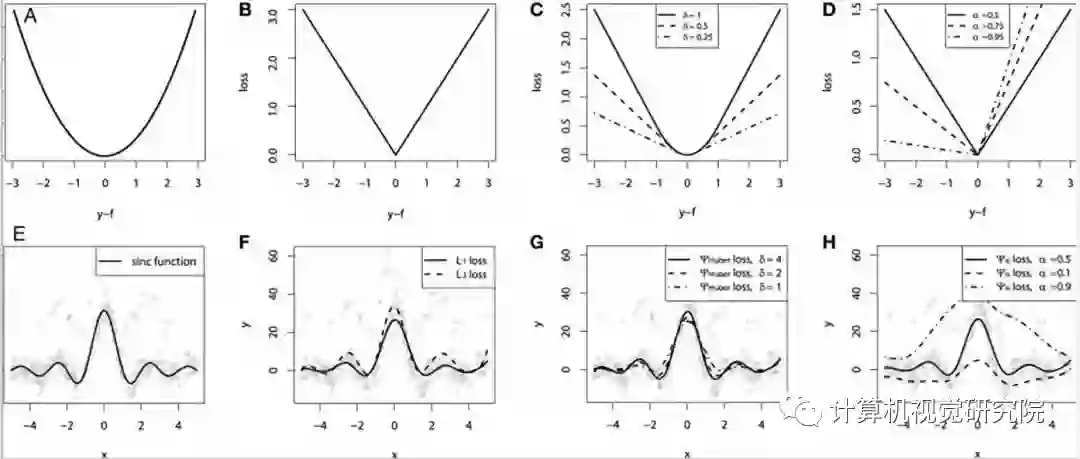
公式 1:鲁棒性损失,其中α为超参数,用来控制鲁棒性
α控制损失函数
的鲁棒性。c 可以看作是一个尺度参数,在 x=0 邻域控制弯曲的尺度。由于α作为超参数,我们可以看到,对于不同的α值,损失函数
有着相似的形式。
![]()
在α=0和α=2时,损失函数
是未定义的,但利用极限可以实现近似。从α=2到α=1,损失函数
平稳地从L2损失过渡到L1损失。对于不同的α值,我们可以绘制不同的损失函数
,如下图所示。
导数对于优化损失函数非常重要。下面研究一下这个损失函数的一阶导数,我们知道,梯度优化涉及到导数。对于不同的α值,x的导数如下所示。上图还绘制了不同α的导数和损失函数。
![]()
公式 3:鲁棒损失(表达式 1)对于不同的α的值相对于 x 的导数
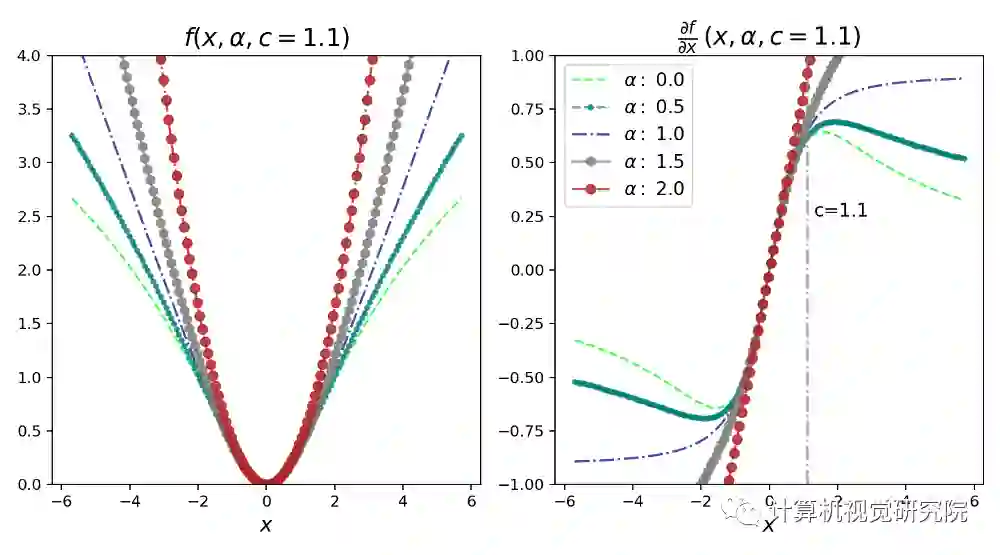
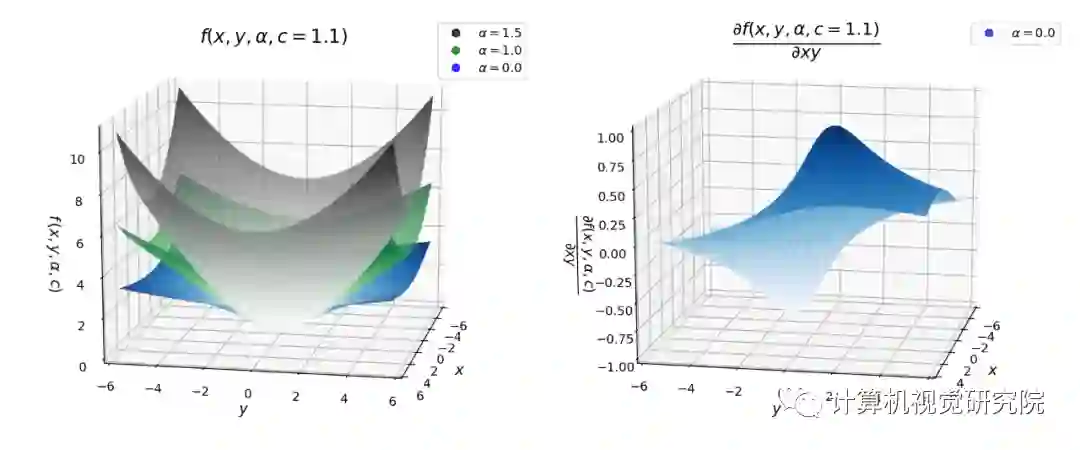
下图对于理解此损失函数
及其导数非常重要。在下图中,尺度参数c固定为1.1。当x = 6.6时,可以将其视为x = 6×c。可以得出以下有关损失及其导数的推论:
1. 当 x、α和c>0时,损失函数
是光滑的,因此适合于基于梯度的优化;
2. 损失函数
总是在原点为零,并且在| x |>0时单调增加。损失的单调性也可以与损失的对数进行比较;
3. 损失也随着α的增加而单调增加。此属性对于损失函数
的鲁棒性很重要,因为可以从较高的α值开始,然后在优化过程中逐渐减小(平滑)以实现鲁棒的估计,从而避免局部最小值;
4. 当| x |<c时,对于不同的α值,导数几乎是线性的。这意味着当导数很小时,它们与残差的大小成正比;
5. 对于α= 2,导数始终与残差的大小成正比。通常,这是 MSE(L2)损失的特性;
6. 对于α=1(L1 损失),我们看到导数的幅度在| x |>c之外饱和至一个常数值(正好是 1/c)。这意味着残差的影响永远不会超过一个固定的量;
7. 对于α<1,导数的大小随着| x |>c而减小。这意味着当残差增加时,它对梯度的影响较小,因此异常值在梯度下降
过程中的影响较小。
![]()
![]()
图 3:自适应损失函数
(左)及其导数(右)的曲面图
鲁棒损失的实现:Pytorch 和 Google Colab
关于鲁棒损失的理论掌握了,怎么实现呢?使用的代码在 Jon Barron 的 GitHub 项目「robust_loss_pytorch」中稍加修改。此外还创建了一个动画来描述随着迭代次数的增加,自适应损失如何找到最佳拟合线。
GitHub 地址:
https://github.com/jonbarron/arom_loss_pytorch
不需要克隆存储库,我们可以使用 Colab 中的 pip 在本地安装它。
此外还创建了一个简单的线性数据集,包括正态分布的噪声和异常值。
首先,由于使用了 Pythorch 库,利用 torch 将 x, y 的 numpy 数组转换为张量。
import numpy as npimport torchscale_true = 0.7shift_true = 0.15x = np.random.uniform(size=n)y = scale_true * x + shift_truey = y + np.random.normal(scale=0.025, size=n) flip_mask = np.random.uniform(size=n) > 0.9y = np.where(flip_mask, 0.05 + 0.4 * (1. — np.sign(y — 0.5)), y) x = torch.Tensor(x)y = torch.Tensor(y)
其次,使用 pytorch 模块定义线性回归类,如下所示:
class RegressionModel(torch.nn.Module): def __init__(self): super(RegressionModel, self).__init__() self.linear = torch.nn.Linear(1, 1) def forward(self, x): return self.linear(x[:,None])[:,0]
接下来,用线性回归模型拟合自创建的线性数据集,首先使用损失函数
的一般形式。这里使用一个固定值α(α=2.0),它在整个优化过程中保持不变。正如在α=2.0 时看到的,损失函数
等效 L2 损失,这对于包括异常值在内的问题不是最优的。对于优化,使用学习率
为 0.01 的 Adam 优化器。
regression = RegressionModel()params = regression.parameters()optimizer = torch.optim.Adam(params, lr = 0.01)for epoch in range(2000): y_i = regression(x) # Use general loss to compute MSE, fixed alpha, fixed scale.loss = torch.mean(robust_loss_pytorch.general.lossfun(y_i — y, alpha=torch.Tensor([2.]), scale=torch.Tensor([0.1]))) optimizer.zero_grad() loss.backward() optimizer.step()
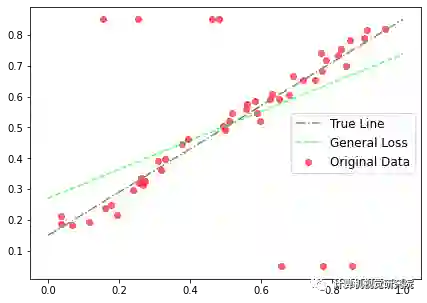
利用鲁棒损失函数
的一般形式和固定α值,可以得到拟合线。原始数据、真直线(生成数据点时使用的具有相同斜率和偏差的线,排除异常值)和拟合线如下图4所示:
损失函数的
一般形式不允许α发生变化,因此必须手动微调α参数或执行网格搜索进行微调。
此外,正如上图所示,由于使用了L2损失,拟合受到异常值的影响。这是一般的情况,但如果使用损失函数
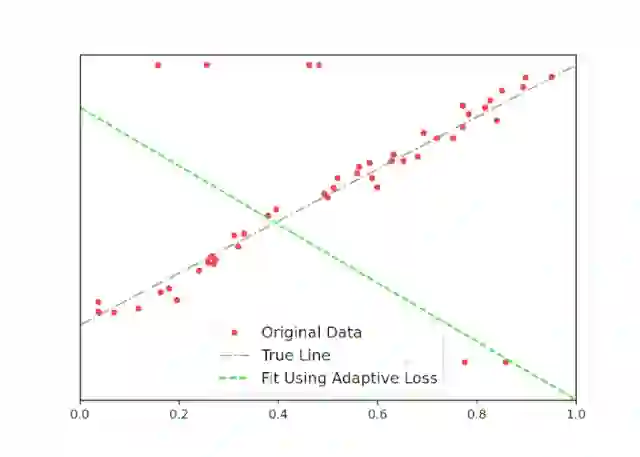
的自适应版本,会发生什么呢?调用自适应损失模块,并初始化α,让α在每个迭代步骤中自适应。
regression = RegressionModel()adaptive = robust_loss_pytorch.adaptive.AdaptiveLossFunction( num_dims = 1, float_dtype=np.float32)params = list(regression.parameters()) + list(adaptive.parameters())optimizer = torch.optim.Adam(params, lr = 0.01)for epoch in range(2000): y_i = regression(x) loss = torch.mean(adaptive.lossfun((y_i — y)[:,None])) # (y_i - y)[:, None] # numpy array or tensor optimizer.zero_grad() loss.backward() optimizer.step()
此外,还有一些额外的代码使用celluloid模块,见下图5。在这里,可以清楚地看到,随着迭代次数的增加,自适应损失如何找到最佳拟合线。这个结果接近真实的线,对于异常值的影响可以忽略不计。
我们开创“计算机视觉协会”知识星球一年有余,也得到很多同学的认可,我们定时会推送实践型内容与大家分享,在星球里的同学可以随时提问,随时提需求,我们都会及时给予回复及给出对应的答复。
![]()
如果想加入我们“
计算机视觉研究院
”,请扫二维码加入我们。我们会按照你的需求将你拉入对应的学习群!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”
研究
“。之后我们会针对相应领域分享实践过程,让大家真正体会
摆脱理论
的真实场景,培养爱动手编程爱动脑思考的习惯!
长按扫描二维码关注我
回复“鲁棒性”获取论文集下载