NeurIPS 2019 | 香侬科技开源Glyce2.0,中文字形增强BERT表征能力


前言
-
序列标注 -
NER 命名实体识别: MSRA、OntoNotes4.0、Resume、Weibo -
POS 词性标注: CTB5/6/9、UD1 -
CWS 中文分词:PKU、CityU、MSR、AS -
句对分类: BQ Corpus、XNLI、LCQMC、NLPCC-DBQA -
单句分类: ChnSentiCorp、Fudan、Ifeng -
中文 SRL: CoNLL-2009 -
中文依存句法分析: CTB5.1
研究思路
中文作为世界上最典型的意音文字(Logogram),其每个字既表示语素,又表示音节,其中,最为特殊的是汉字的表意功能,即象形表意能力。尽管当今的简体字在很大程度上已经无法推知其最初的象形意义,但是汉字的发展过程依然可以给我们很多的字义信息,如下图所示:

对 NLP 而言,过去也有很多相关针对中文字形的研究,期望可以把字形表示和词向量结合,增强语义表征能力,但一直未能取得显著成功。
比如,[Liu et al., 2017, Zhang and LeCun, 2017] 未能取得一致的效果提升,之在相当有限的情况下才有少许提升,甚至 [Dai and Cai, 2017]得到了负提升。[Su and Lee, 2017] 发现字形信息对词语类比和词相似度任务有帮助,但并未对更高层次的语言单位如短语、句子进行实验。
经分析后认为,[Dai and Cai, 2017] 得到负效果的原因在于:
未使用正确的字体。当前的简体字(繁体字同理)已经十分抽象化,基本无法得到字的表义信息,单纯地使用简化字隔离了字形的象形意义。
未使用正确的 CNN 结构。不同于一般图片,字体图片很小,一般为 12*12,需要谨慎设计 CNN 结构。
未使用正则约束。中文汉字共计约 10000 个,远少于 ImageNet 等大型数据集的图片数量,因此极容易导致过拟合。
对此,提出了三种策略对字形进行建模、训练:
使用汉字的多种历史字形、字体
使用田字格 CNN
使用图像分类的多任务学习
在这三种策略下,Glyce 能够很好地补充词向量(如 Word2Vec、BERT 等)在中文上欠缺的字形信息,在多项任务上取得较 Bert 的一致性提升。同时,香侬还进行了 Ablation Study,探究多种因素的影响。
具体方法
Glyce-Bert 在 Glyce 基础上加入 BERT 与 Transformer。具体来说,Glyce 使用了下述三种策略。
一是历史汉字字形的使用。使用了金文、隶书、篆书、魏碑、繁体中文、简体中文(宋体)、简体中文(仿宋)和草书这八种字体。
二是设计了 Tianzige(田字格)-CNN 结构。对 12 * 12 的汉字图片,首先用一个大小为 5 的卷积核去做卷积,得到一个 1024 通道的输出,然后用大小为 4 的 max-pooling 将 8 * 8 的特征图降为 2 * 2 的田字格尺寸。
三是使用图像分类损失。将得到的 Glyce 向量过一层全连接进行图像分类,得到的损失为 L("cls" ),从而总的损失为 L=(1-λ(t))L("task" )+λ(t)L("cls"),这里 λ(t) 随着训练递减。
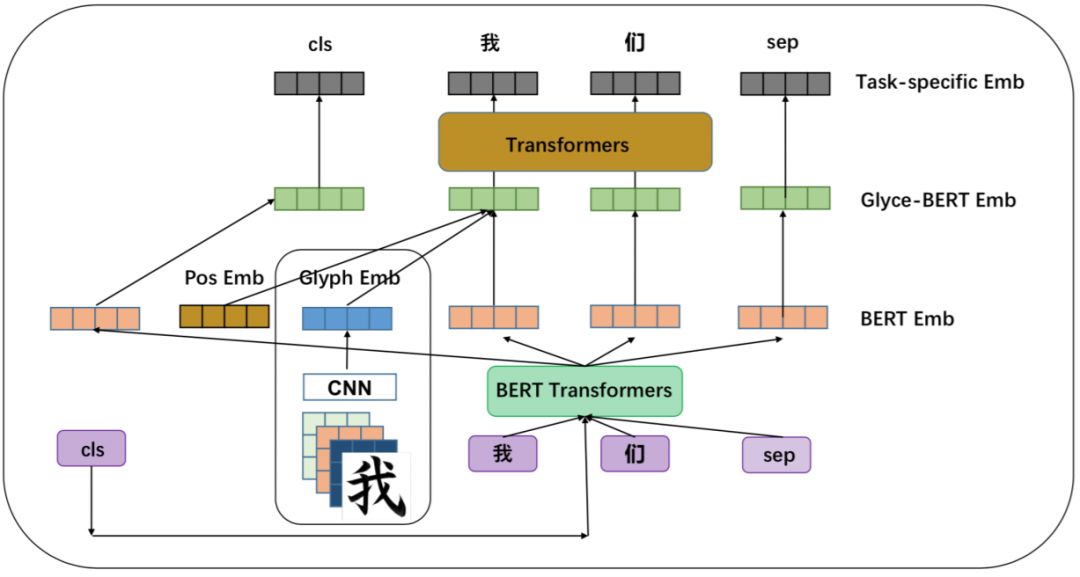
对 Glyce-Bert,在 Glyce 的基础上加入了 Bert,期望可以在 Bert 的基础上进一步提高模型效果。总的来说,Glyce-Bert 分为下面四部分:
Bert 层:得到字的 Bert 表示
Glyph 层:得到字的 Glyph 表示
Glyce-Bert 层:将位置表示加到 Glyph 表示上,然后再和 Bert 表示连接
Task-specific 输出层:将 Glyce-Bert 向量输入到 Transformer,再用得到的输出进行预测
实验结果
Glyce2.0 在如下任务和数据集上取得了 SOTA 结果:
NER 命名实体识别
POS 词性标注
CWS 中文分词
句对分类
单句分类
中文 SRL
中文依存句法分析
NER 实验结果如下:
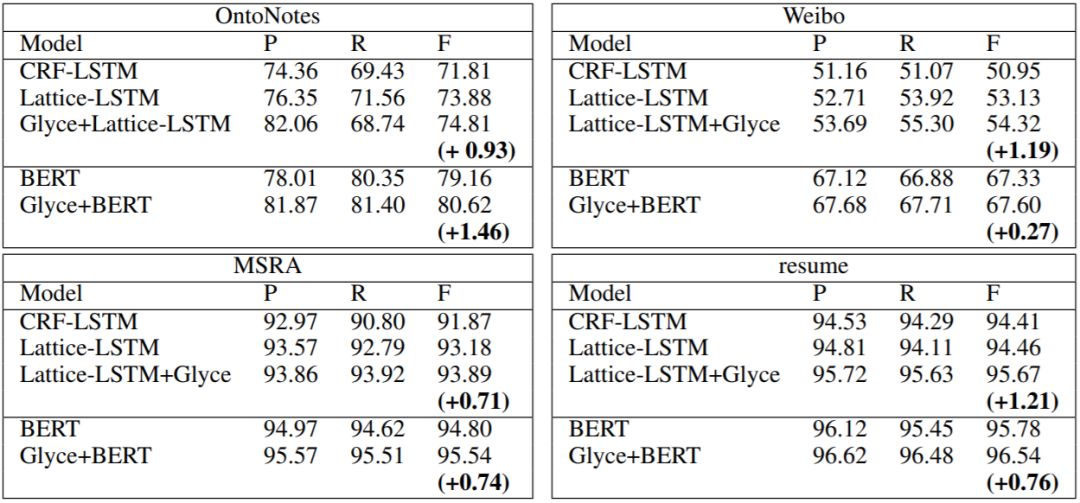
可以看到,Lattice-LSTM 超过所有的非 Bert 模型,而 Bert 模型超过所有非 Bert 模型。在使用了 Glyce 之后,Lattice-LSTM 涨约 1 个点,Bert 模型涨幅不定,这与数据集有关。
下面是 CWS 实验结果:
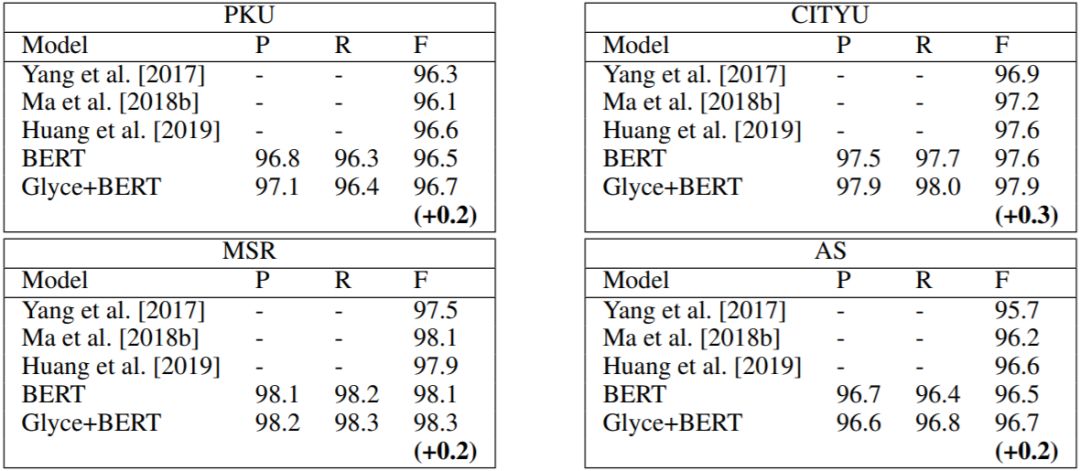
对 CWS,F1 值在 Bert 上涨幅较少,这是由 CWS 本身的难度和数据集较小导致的。
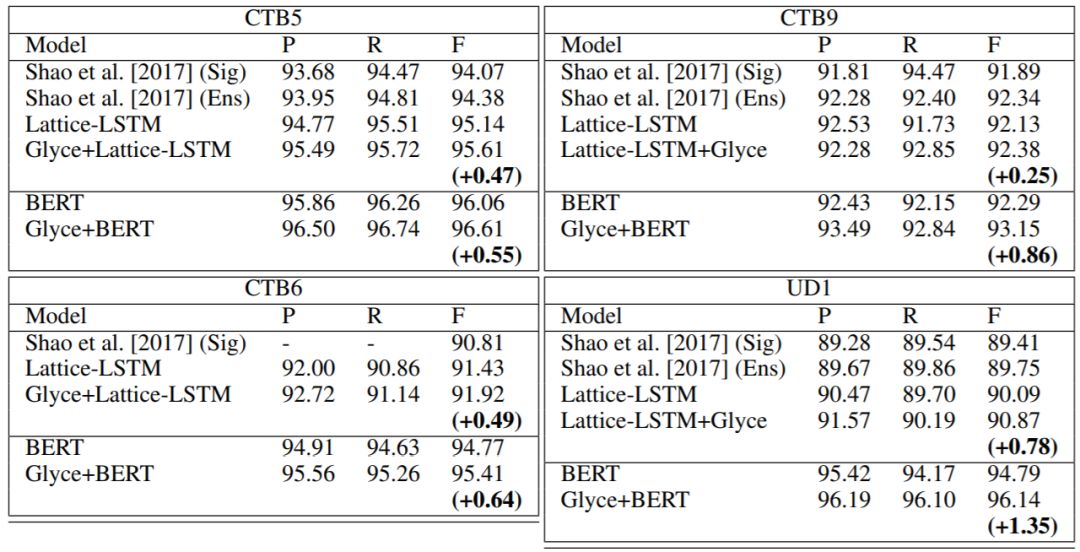
下表是 POS 实验结果,加入 Glyce 后,对 Lattice-LSTM 和 Bert 都有相应的提升。
此外,在句对分类、单句分类任务的各个数据集上 Glyce-Bert 都能取得较 Bert 更好的结果,下表是实验结果。

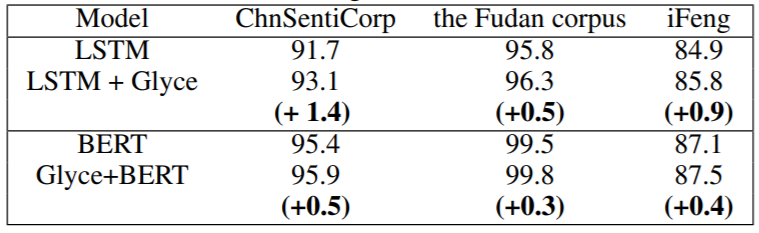
在中文 SRL 和中文依存句法分析上,相比之前的最优结果(未使用 Bert),使用 Glyce 之后能取得接近 1 个点的提升。

语表示方法是理解成语的关键。能够看到将成语表示为独立的语义单元比基于合成性假设的表示效果更好,而后者又显著地优于基于字面含义的理解。这说明一个好的模型不仅应该有合适的模型结构,也要有好的表示成语的方法。
分析讨论
本节我们对 Glyce 的几种策略进行讨论,探究它们的实际影响。在下面的所有实验中,我们使用 LCQMC 数据集进行说明。
训练策略
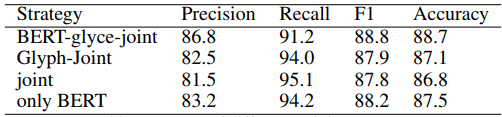
首先探究几种不同的训练策略:
Glyph-Joint:首先固定 Bert 去微调 Glyce,然后再结合微调 Bert 和 Glyce。
Bert-Glyph-Joint:首先微调 Bert,再固定 Bert 微调 Glyce,最后综合两者微调。
Joint:直接训练 Bert 和 Glyce。
下图是几种训练策略的实验结果,可以看到,Bert-Glyph-Joint 的训练策略效果最佳,而 Joint 效果最差。这是因为,Bert 是经过预训练的,而 Glyce 是随机初始化的,这样就会有预训练-随机初始化的失配。
图像分类损失
下表是有无图像分类损失 $\mathcal{L}(\text{cls})$ 的结果,可以看到,加上图像分类损失后,F1 值提高了 0.4,Accuracy 提高了 0.8。使用图像损失,是为了避免小数据(约 10000 个字符)下的过拟合。

输出层的影响
Glyce-Bert 使用两层 Transformer Block,我们把 Transformer 替换为 BiLSTM、CNN 与 BiMPM 探求其影响。
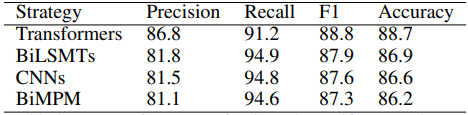
显然,Transformer 结果显著更优,这是因为 Bert 和 Transformer 结构更加匹配。
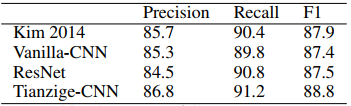
CNN结构的影响
最后,来分析 CNN 结构的影响。在对比了 [Kim, 2014]、[He, 2016] 和 Vanilla-CNN 后,结果如下。可以看到,使用 Tianzige-CNN 能显著提高 F1 值。
小结
香侬科技提出的 Glyce-Bert 模型通过实验证明了 Glyce 字形特征与 Bert 向量的互补性,能够在 Bert 上得到一致提升。同时,香侬还开源了 Glyce 代码,方便研究者复现使用。在未来,希望他们还会继续加强对中文字形信息的挖掘,改进模型,并发布高质量预训练字形向量。
参考文献

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 下载论文 & 源码



