简单新颖神操作,截断骨干用于检测!YOLO-ReT开源:边缘GPU设备上的高性能检测器

极市导读
本文提出了一种边缘GPU设备上的高性能检测器YOLO-ReT,它包含两个关键性的改进:(1) 边缘GPU友好的模块RFCR用于多尺度特征交互;(2) 一种基于迁移学习的骨干截断机制。尤其值得称道的是:文中关于骨干截断分析与实验。为下游任务的模型缩放提供了一种更好的骨干网络设计机制。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

论文链接:https://arxiv.org/pdf/2110.13713.pdf
代码链接:https://github.com/prakharg24/yoloret
Abstract
目标检测模型在模型精度与效率两条主线上得到了长足发展。然而,为将DNN检测器部署到边缘设备上,我们需要对齐进行大幅压缩,这就导致了模型性能的牺牲。
本文提出了一种新颖的边缘GPU友好的模块RFCR用于多尺度特征交互 ;此外,我们还提出一种新颖的迁移学习骨干调节方案 以补充特征交互模块,并协同提升模型在不同边缘GPU设备上的推理速度以及模型精度。
比如,当硬件平台为Jetson Nano时,YOLO-ReT+MobileNetV2(x0.75)能够实时推理并取得68.75mAP@VOC、34.91mAP@COCO指标,以3.05mAP@VOC、0.91mAP@COCO以及3.05FPS提升优于对标方案 ;当引入了RFCR模块后,YOLOv4-tiny与YOLOv4-tiny(3l)可以取得了1.3与0.9mAP指标提升达到41.5mAP@COCO与48.1mAP@COCO。
Method
本文提出一种新的监测模型YOLO-ReT,它采用了RFCR模块与迁移学习启发的骨干截断机制提升模型性能与边缘GPU设备上的推理速度。下图为本文所提方案的整体架构示意图。
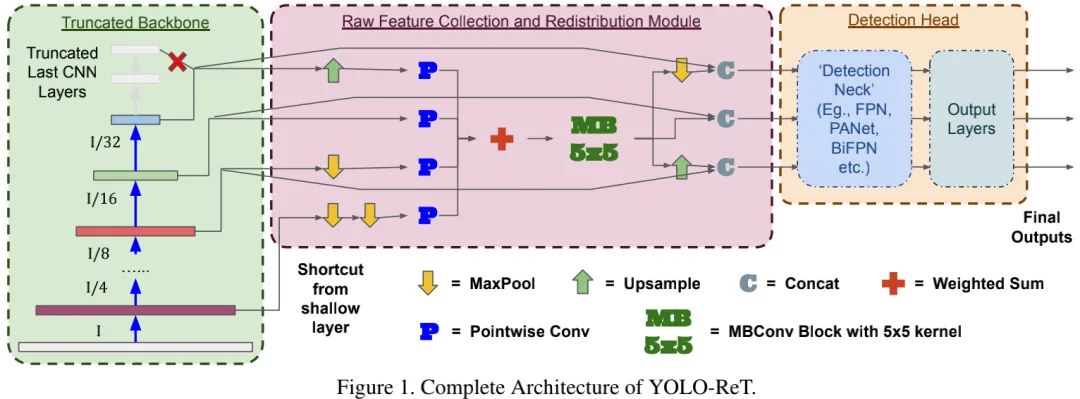
Raw Feature Collection and Redistribution
RFCR(见上图红色区域)的目标在于:对骨干网络提供的原生特征进行进一步增强,进而提升检测性能,同时不会大幅影响推理速度。注:尽管本文聚焦于检测,但RFCR可以扩展到其他相似任务。
现有的多尺度特征交互方案可以划分为top-down与bottom-up两种,两者均聚焦于相邻尺度特征交互,而忽视非相邻尺度特征交互。受NAS-FPN中的非相邻尺度特征连接启发,我们提出了一种轻量型RFCR模块:它对骨干网络的多尺度特征进行融合并重分布回每个特征尺度。因此,每个尺度包含了直接包含其他所有尺度的特征。
需要注意的是:RFCR并不是用于替换其他特征聚合方案,而是提供一个超轻量特征处理模块对送入FPN等特征聚合方案的特征进行增强,并进一步提升整体性能 。
此外值得注意的是,RFCR独立于检测头的输出尺度数量,即输入输出特征数量之间无约束 。比如,尽管YOLOV3检测头有三个输出尺度,我们在特征收集阶段采用骨干网络提供的四个不同特征以利用更细粒度底层特征提升模型性能。
如所知,特征融合方式与聚合路径同等重要。为尽可能降低额外的延迟负担,我们将原生特征融入 卷积并采用简单的加权方式融合,将融合后特征融入MBConv模块处理后重分布回不同尺度 。
当对不同尺度特征进行融合时,常规上采样与下采样会导致语义不一致、局部位置不匹配问题。因此,我们在MBConv中采用 卷积以提升检测性能 。注:卷积核尺寸提升到 并不会带来进一步的性能提升。
Backbone Truncation
从分类模型预训练向下游任务迁移的重要性已受到过质疑,恺明大大也曾针对此写了《Rethinking ImageNet Pre-training》一文;此外某些文章甚至专门针对检测设计骨干模型。
基于这样的直觉:通过连续CNN层处理的信息流会随任务而变化 。比如,分类模型不需要尺度空域信息;而检测模型则需要保持空域信息完整性以输出细粒度检测结果。我们认为:骨干网络的初始层的迁移学习能力非常重要,而尾部层并不会给检测/识别提供重要信息 。
The transfer learning capabilities of the initial layers of the feature extraction backbone are quite vital, and it iis the last layers that do not provide critical information for the detection/recognition.
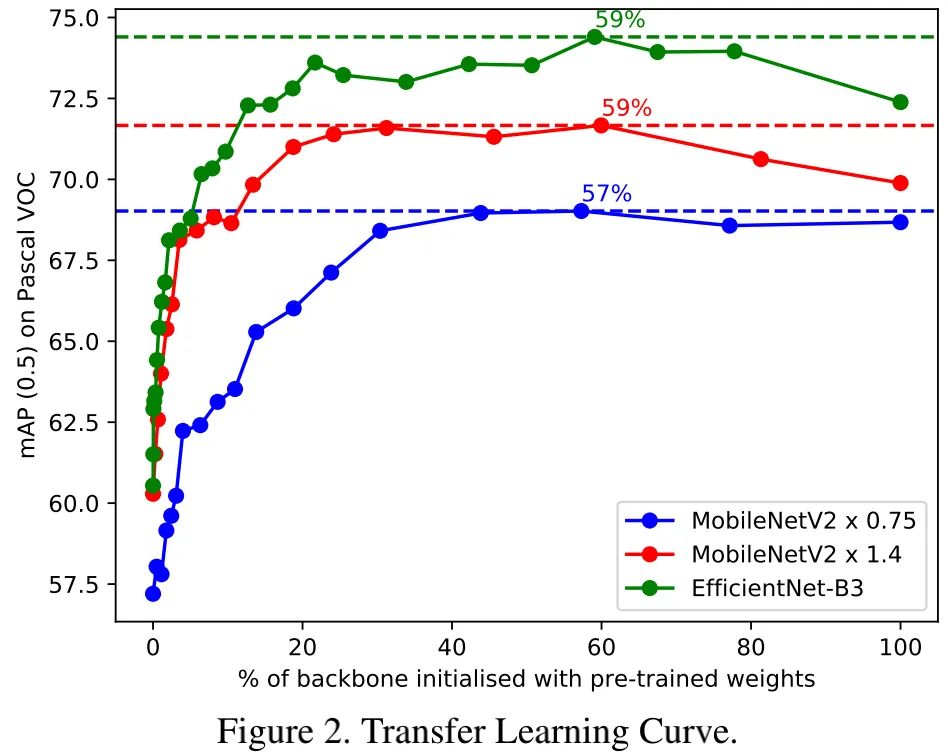
上图以PANet+YOLOV3检测头+不同比例层骨干预训练的性能对比,可以看到:
-
随着预训练初始化骨干层比例提升,模型性能逐渐提升。这说明:迁移学习非常重要 ;
-
当预训练初始化层的比例达到60%左右时,模型性能开始恶化。这说明:相比随机初始化,采用预训练初始化骨干的尾部层会影响模型性能 。可能原因:这些层因与任务相关而陷入局部最优。
从上图可以看到最后2-3层包含约40%参数量。因此,我们采用截断版骨干用于最终的目标检测模型 ,提供了一种比降低缩放因子更优的选择。结合上图,我们截断MobileNetV2的后两个模块、截断EfficientNet的后三个模块后作为检测器的骨干 。
Experiments
我们采用meanAP指标进行算法性能评估,采用FPS评估其效率。
Evaluation Setups
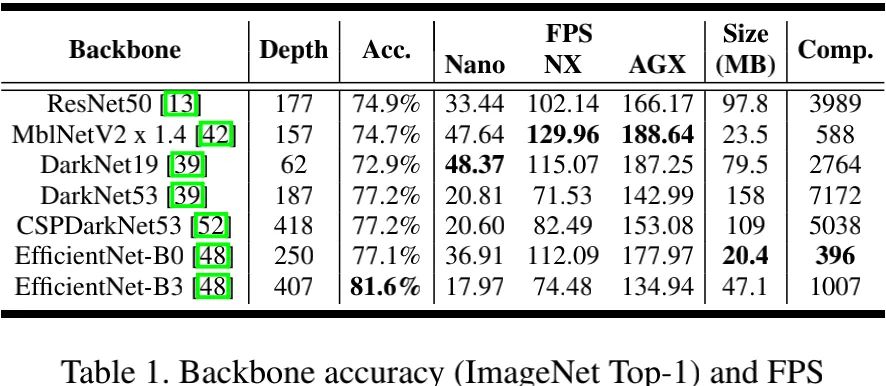
上表给出了不同骨干网络的深度、精度、参数量、FLOPs以及在不同硬件上的FPS。基于该表汇总信息,在骨干方面 ,我们主要聚焦于三个常用轻量型骨干:MobileNetV2(x0.75)、MobileNetV2(x1.4)以及EfficientNet-B3;在检测头方面 ,我们采用PANet+YOLOV3检测头 ;在数据集方面,我们主要采用了Pascal VOC与COCO;在度量指标方面 ,我们主要采用meanAP与FPS,评价用的硬件平台包含Jetson Nano、Jetson Xavier NX以及AGX Xavier。
在训练方面,我们主要考虑两种类型的数据增广:
-
geometric augmentations: 随机裁剪、旋转、镜像、缩放等;
-
photometric augmentation:HSV调整、亮度调整等。
此外,我们还采用YOLOV4提到的自对抗训练;对定位方面,我们采用了GIoU损失。训练过程中,我们首先冻结迁移学习部分预训练参数训练100epoch,然后解冻所有参数训练150epoch。
在推理测试方面,我们以TenorRT+FP16进行加速,batch=1,推理1000张图像取平均计算FPS。与此同时,我们还提供了TensorRT+INT8配置的FPS以对标特定平台的整数推理计算(注:由于Jetson Nano不支持INT8加速,故相比FP16并无任何优势)。
Ablation Study
我们先来看一下消融分析并构建最终的检测模型,消融分析包含骨干截断 与RFCR模块 。
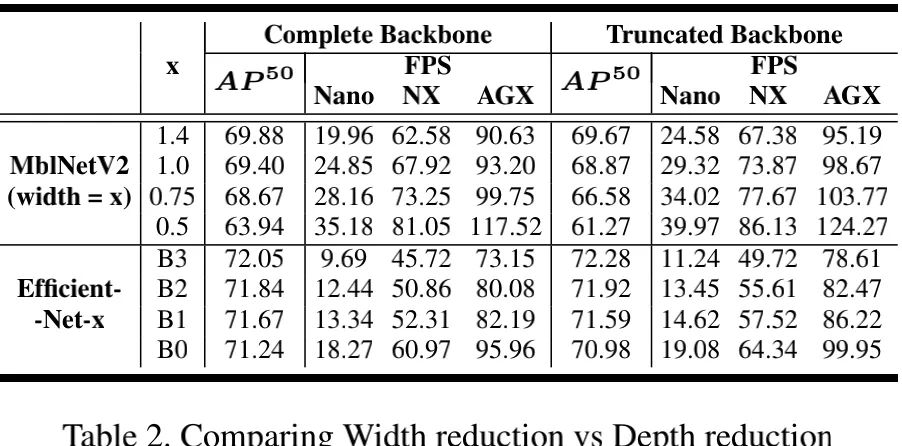
上表对比了完整骨干与截断骨干的性能对比,从中可以看到:
-
对于EfficientNet ,截断版本能够取得更佳的精度与FPS ;
-
对于MobileNetV2 ,当具有相似FPS时,截断版本具有更高的性能 。比如MobileNetV2(x1.4)的截断版本比MobileNetV2(x1.0)完整版本具有相似FPS,但截断版本的性能高0.27AP;MobileNetV2(x0.75)的截断版本比MobileNetV2(x0.5)完整版本具有相似FPS,但截断版本的性能高2.64AP。
-
总而言之,相比完整骨干,骨干截断能提供更精确、更快速的特征提取网络 。
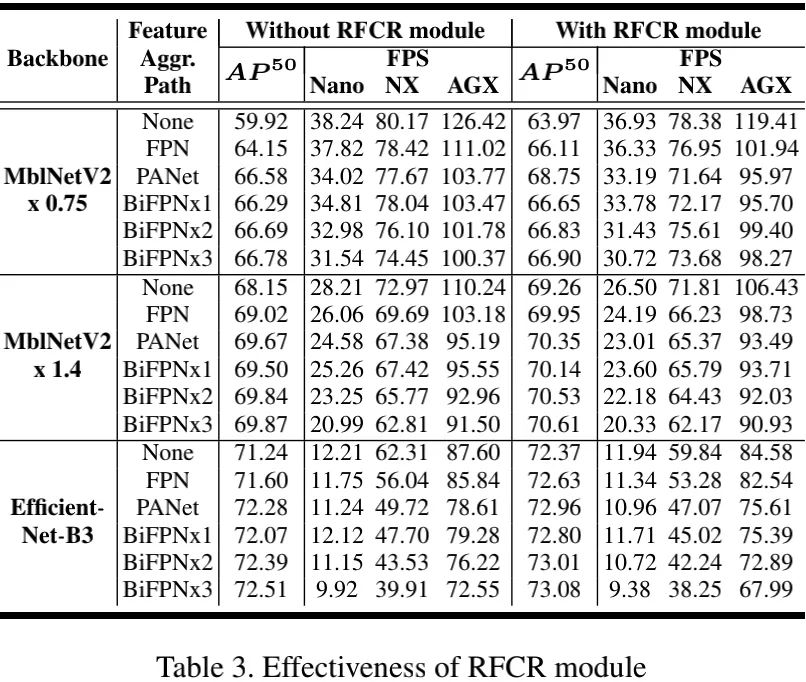
上图对比了 RFCR模块添加前后的性能与速度对比,从中可以看到:
-
无论何种骨干与特征聚合方案,所提RFCR均能取得一致的性能提升 ,当然FPS也会轻微下降;
-
当不存在特征聚合时,所提RFCR可以带来更多的性能提升;对于BiFPNx3,所提RFCR仍可进一步提升其性能,说明了非近邻层连接的重要性 。
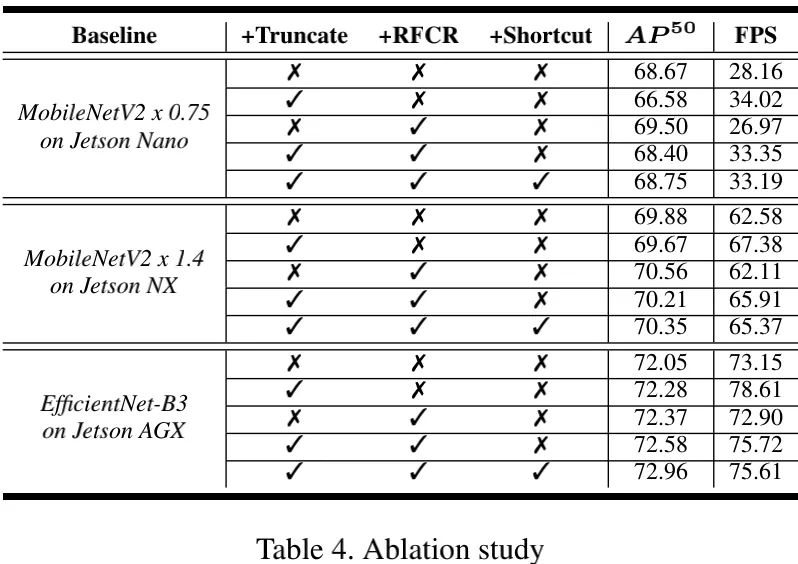
上图给出了复合消融分析,可以看到:
-
对于骨干截断与完整骨干,RFCR均表现良好;而完整版骨干方案FPS下降明显;
-
RFCR+短连接组合可以进一步提升性能,FPS几乎不变;
-
总而言之,通过组合骨干截断与RFCR,我们可以提升推理速度与模型性能 。
Comparison with SOTA Models
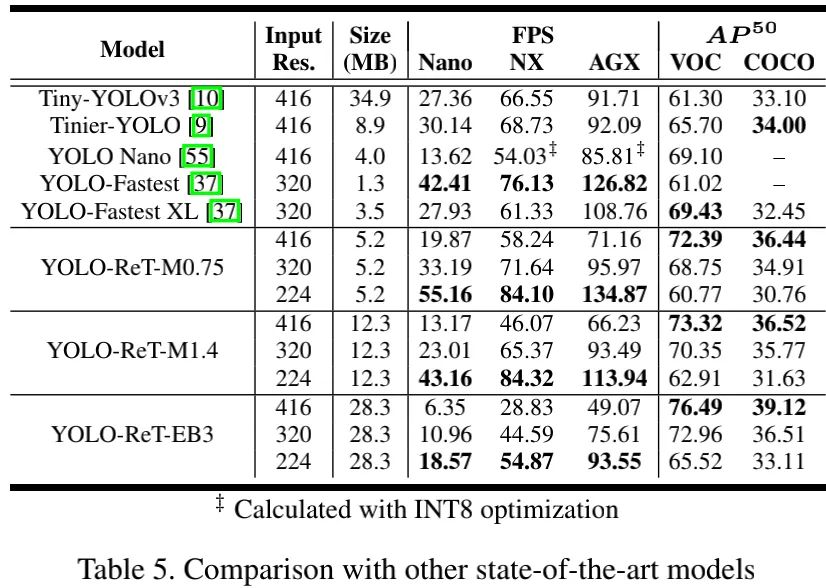
上表给出了不同实时检测器的性能对比,从中可以看到:
-
当输入分辨率变小时,模型具有更快的推理速度、更低的模型精度 。
-
当硬件平台为Jetson Nano时,YOLO-ReT-M0.75@320x320具有比Tinier-YOLO高3.05mAP@VOC、0.91mAP@COCO的性能,同时推理速度快3.05FPS;
-
当硬件平台为Jetson Xavier NX时,YOLO-ReT-M1.4@320x320具有比YOLO-Fastest-XL高0.92mAP@VOC、3.34mAP@COCO的性能,同时推理速度快4.02FPS;
-
当平键平台为AGX Xavier时,YOLO-ReT-EB3@416x416取得了最佳性能,同时仍具有实时推理速度;
-
需要注意的是:在具有相似FPS时,基于MobileNetV2的检测器性能要优于骨干为EfficientNet的检测器。
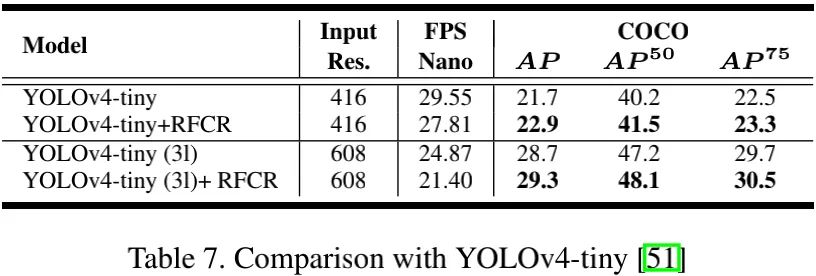
上表对比了YOLOv4与RFCR组合前后的性能对比,从中可以看到:RFCR可以显著提升基线模型性能;RFCR对YOLOv4-tiny的提升更大 。
本文亮点总结
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# 极市平台签约作者#

happy
知乎:AIWalker
AIWalker运营、CV技术深度Follower、爱造各种轮子
研究领域:专注low-level,对CNN、Transformer、MLP等前沿网络架构
保持学习心态,倾心于AI技术产品化。
公众号:AIWalker
作品精选




