NeurIPS 2021 | MSRA提出:目标检测与分割的零标签视觉学习
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
编者按:随着自监督学习的研究逐步深入,迁移学习的范式已经广泛应用于视觉学习的各个领域,大量的视觉任务都通过使用自监督预训练和有监督微调的方式来部署任务。而微软亚洲研究院的研究员们希望打破这一范式,在 NeurIPS 2021 发表的论文中,研究员们提出了一个可以从无标签视频中学习物体检测和分割的模型,使得自监督预训练模型可以直接服务于应用,而不需要任何有监督微调,实现了零标签的学习。
对比学习是当前训练视觉自监督模型中的主流方法。其核心思想是将训练数据集中的每一个独立样本视为一个类别,设计预训练的任务为独立个体的识别。由于每个类别只有一个样本,个体识别会非常简单。研究者们通常会利用数据增强技术为每个样本创造丰富的类内样本。对于图片来说,数据增强大致包括:图片的平移、缩放、翻转、颜色对比度和色泽的变化、模糊以及灰度变换等等。这些图像增强技术虽然改变了图像的细节,但是却没有改变图片描述的语义内容。实际上,对比学习是在学习对于这些增强变换具有不变性的特征表示。从实验中可以观察到,对比学习对数据增强的依赖是非常显著的。

图1:对比学习强烈依赖于底层的图像增强技术从而学习不变性。常用的图像增强技术包括平移、缩放、颜色增强、局部模糊等。
作为一种预训练的方法,对比学习只是学习到了一种特征表示,但是这种特征表示需要一些(少量的)有监督的下游数据做微调训练之后,才可以应用于下游任务。预训练的表征虽然可以大幅度提升下游任务的微调性能,但依赖于微调的特性却成为了自监督模型本身的缺陷和短板。
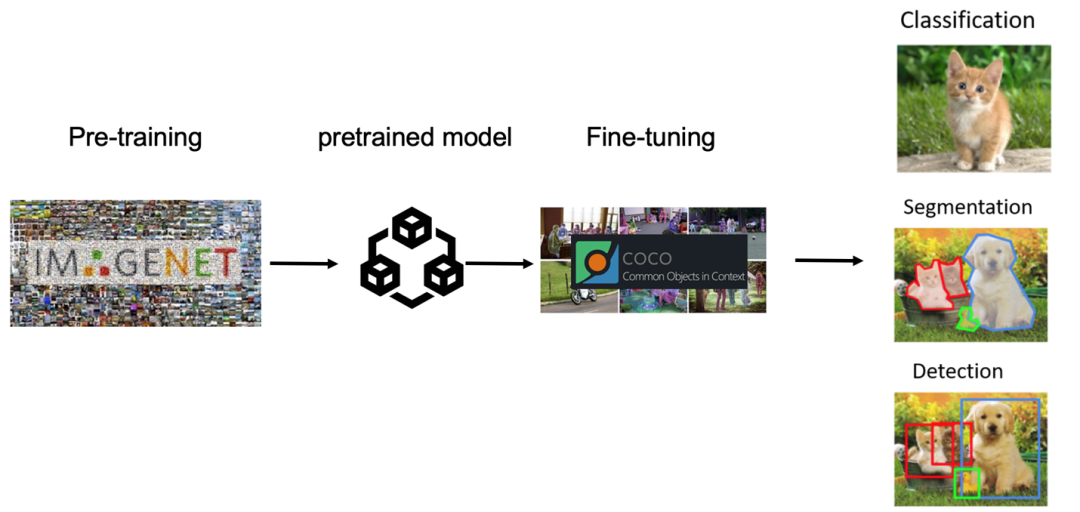
图2:迁移学习的框架:通用预训练 + 特定任务的微调。自监督学习成为了强大的预训练方法,然而其必须利用下游任务的少量监督数据才可以服务于应用。

基于针对对比学习缺陷的分析和理解,微软亚洲研究院的研究员们希望设计一种不需要微调就可以直接应用到下游任务的自监督模型。为了达成这个目的,研究员们开始从视频中寻找有用的信息。区别于计算机学习图片识别任务,人类是从一个连续变换的时序信号中实现学习的。一个时序的视频信号包含了很多图片中不可能存在的有用信息。比如,视频可以描述一个物体的运动(motion)以及它的形态变化(deformation);然而,对于静态图片数据集,一个物体很难在数据集中被多次捕捉到。再如,通过几何学的方法,研究员们可以从视频中重建一个物体的三维形态,但这也很难从静态图片中恢复。因此,研究员们希望可以从视频中分析物体的运动形态,借助其运动形态帮助检测物体的存在,并分割出物体的外形。
视图合成任务(View Synthesis)
首先,研究员们需要从视频中寻找到合适的免费监督信息来学习物体的检测和分割。视频中常用到的一个学习目标就是视图合成任务。具体来说,给定一个视频的两帧图片,一帧初始图片,一帧目标图片,视图合成任务会尝试学习一个扭曲函数(warping function),用来建模从初始帧到目标帧的像素重建过程。这个看似简单的任务有着丰富的应用场景。例如,若用像素点对点的对应关系来表示这个扭曲函数,那么视觉合成任务就可以实现自监督的光流(optical flow)学习。再如,若可以获得相机的参数,视觉合成任务可用来实现自监督单通道深度(depth)的估计。实现不同自监督任务的关键是:找到一个合适的表示方法(representation),使其既能够完成视图合成任务,同时又能实现所关心的应用任务,比如光流和深度的估计。再举一个例子,先前的工作为了完成双目图像的立体增强(stereo magnification),设计了新的多平面图(multi-plane images)表示方法。
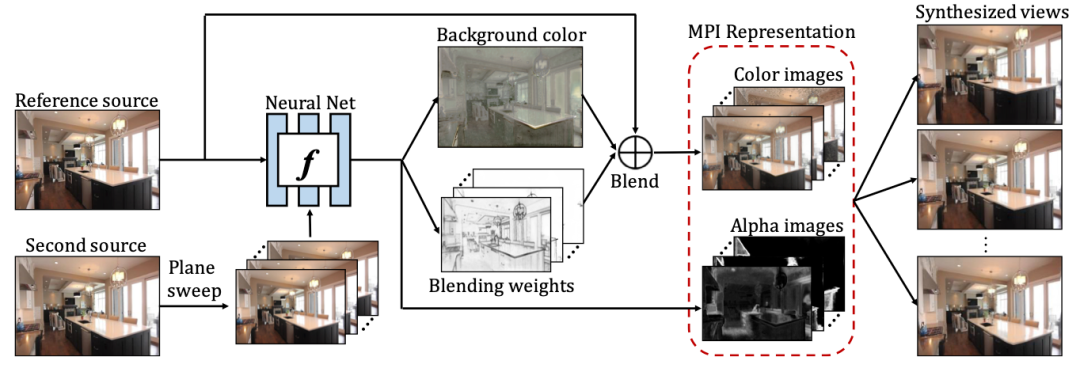
图3:视图合成任务可以驱使一种新的多平面图表示,这种新的表示可以帮助生成大 baseline 情况下的视图。图片摘自论文“Stereo Magnification: Learning View Synthesis using Multiplane Images”。
研究员们寄希望于应用视图合成任务来实现物体的检测和分割,这与先前工作最大的不同是试图提取和学习图片中层甚至高层的表示,而并非仅停留在学习图像的一些低层表示。出于此目的,研究员们设计了一种新的表示和模型 AMD(Appearance-Motion Decomposition),用来实现零标签的物体分割。
相关论文“The Emergence of Objectness: Learning Zero-Shot Segmentation from Videos”已被 NeurIPS 2021 接收。

论文链接:
https://papers.nips.cc/paper/2021/file/6d9cb7de5e8ac30bd5e8734bc96a35c1-Paper.pdf
分割流以及 AMD 模型
图4展示了 AMD 模型的基本构架。模型主要由两个构架网络组成:外形网络(appearance pathway)和运动网络(motion pathway)。给定一帧的输入frame i,外形网络会将其分割成为若干个区域,在此例子中为3个。给定连续两帧的输入 frame i 和 frame j,运动网络则会首先抽取出描述空间对应关系的运动特征,接着为外形网络预测的每个区域估计一个整体的光流(flow offset)。
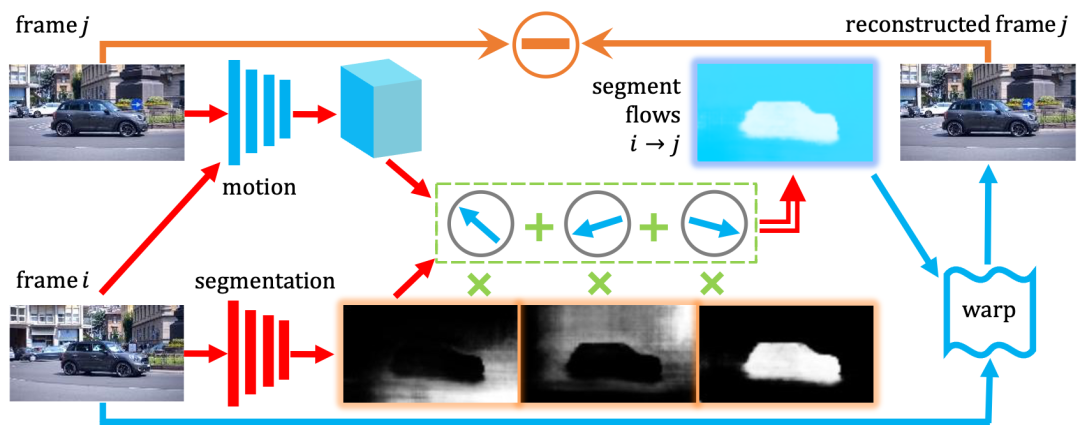
图4:AMD 模型的基本构架。下分支为预测分割的外形网络,上分枝为预测分割流的运动网络。整个模型使用视图合成任务做为训练目标。
在这里,研究员们应用 gestalt principle common fate 的假定,认为每个区域内部共享一个单独的光流。这种假定对于一些刚性物体的运动是不错的估计,但对于复杂形变的物体,这种假定是不成立的。根据预测的每个区域以及相应区域的光流值,研究员们重构了一个光流图。因为这个光流受限于分割的结果,只有很低的自由度,因此称之为分割流(segment flow)。得到这个分割流之后,就可以将 frame i warp 到 frame j 这一帧上。重建的 frame j 可以和实际观测做对比,监督整个网络的学习。
AMD 模型将一个视频的外形(appearance)信息和运动 (motion)信息解耦开(decomposition),从而实现了对图像分割零标签的应用。在实现上,外形网络应用传统的 ResNet50 结构,运动网络应用常见的 PWC-Net, 两个网络均从零训练,未加入任何的预训练初始化。预训练完成后,外形分支可以直接应用在全新的图片上实现图像分割,而不需要任何微调。值得注意的是,训练 AMD 模型并不需要加入大量的图像增强技术。这在一定程度上缓解了对于对比学习的依赖。

图5:光流和分割流的对比。光流以单个像素为基本单元描述物体的运动,分割流以局部的区域为基本单元描述运动。可以看出,由于其精确的描述,光流在时间上的变化很大,很难准确的分割物体。研究员们的分割流尽管牺牲了运动的准确性,却获得了对于物体结构的认知。
无需任何微调,研究员们的 AMD 模型便可以应用在图片分割和视频运动物体等分割任务上。对于图像分割,研究员们只需迁移图形网络分支即可。在一个显著性检测(saliency detection)的数据集 DUTS 上测试时,图6展示了分割效果。由此可见,研究员们的预训练模型不仅可以检测和分割“可移动的物体”,还可以泛化到分割一些静态物体上,例如:雕塑、盘子、长椅、树木等等。

图6:显著性检测在 DUTS 上的测试效果
对于分割视频中的运动物体,则需要迁移 AMD 模型的全部两个分支。针对一个测试视频,为了利用运动信息,研究员们使用了测试阶段优化的技巧(test time adaptation)。具体而言,研究员们同样使用视图合成这个自监督任务对测试视频进行优化,并将 AMD 模型在三个数据测试集上进行了测试(模型从未见过这些数据集的训练集)。研究结果显示,AMD 模型在其中两个数据集上都大幅度超过了已有的方法。图7展示了具体的性能和可视化的结果。

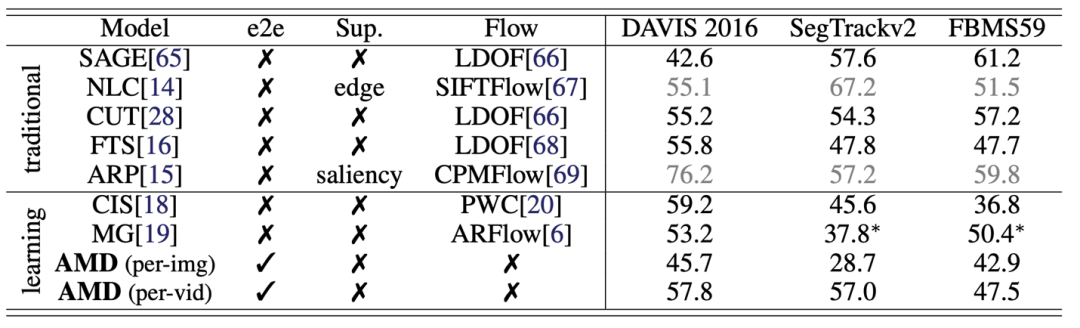
图7:视频中的运动物体分割,上图为可视化的对比,下表为数值上的对比。
本篇论文的研究试图提出和设计一种零标签的自监督学习模型。该模型不需要任何微调就可以使用在一些应用场景中。这项研究工作解耦了视频中的外形和运动表征,使其能够分割和检测物体。研究员们也希望这项研究工作可以启发更多零标签学习的相关任务。
参考文献
1. Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnifi- cation: Learning view synthesis using multiplane images. arXiv preprint arXiv:1805.09817, 2018.
2. Clément Godard, Oisin Mac Aodha, Michael Firman, and Gabriel J Brostow. Digging into self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3828–3838, 2019.
3. Zhirong Wu, Yuanjun Xiong, Stella X Yu, and Dahua Lin. Unsupervised feature learning via non-parametric instance discrimination. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3733–3742, 2018.
4. Deqing Sun, Xiaodong Yang, Ming-Yu Liu, and Jan Kautz. Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 8934–8943, 2018.
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号


