从知识图谱到文本:结合局部和全局图信息生成更高质量的文本

论文标题:
Modeling Global and Local Node Contexts for Text Generation from Knowledge Graphs
论文作者:
Leonardo F. R. Ribeiro, Yue Zhang, Claire Gardent, Iryna Gurevych
论文链接:
https://arxiv.org/abs/2001.11003
从知识图谱中生成文本是一个相当有前景的研究方向,它可以通过结合知识生成更加通顺、有意义的文本。
然而,过去的方法大都只用局部知识或全局知识,没能充分利用二者的优势。本文提出将局部知识和全局知识相结合,从而显著提高文本生成的效果。
从知识图谱到文本生成
文本生成有多种途径,比如从一段文本到另一段文本(翻译、摘要),从一个表格到一段文本,从一个图片到一段文本。
但随着知识图谱在近年来的兴起,从知识图谱生成文本已然成为一个相当有发展前景的方向。
比如下图,给定一个局部知识图谱(a),如果我们能据此直接生成文本(b),那么现实中的很多应用就可以得到解决。
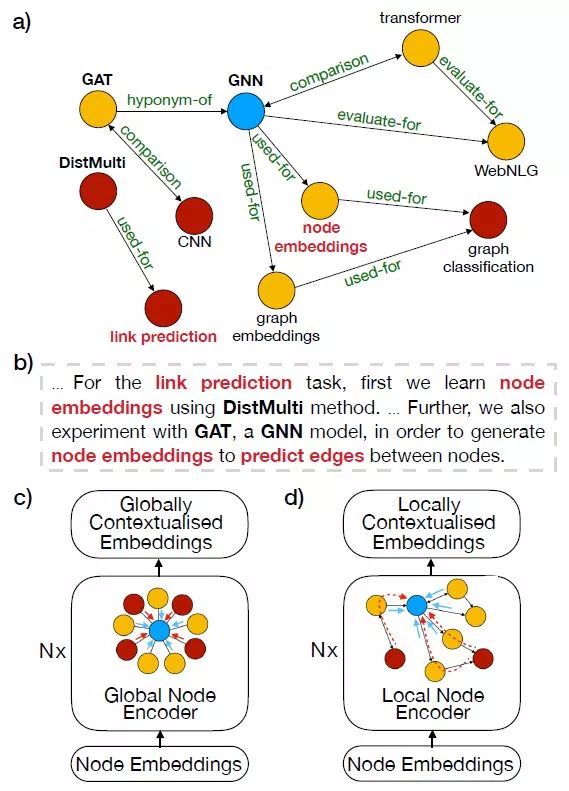
过去的知识图谱文本生成方法大都使用了图卷积网络GCN,它们要么是用全局的结点(c)——假定每个结点都和其他结点相连,要么是用局部的结点(d)——只有一部分结点相连。前者忽略了图的结构,而后者缺乏全局信息。
为此,本文提出将全局结点和局部结点结合起来,既可以捕捉局部图结构信息,又可以建模图整体的知识。
使用这种方法,本文在数据集AGENDA和WebNLG上的结果显著超越之前的最好结果,表明了该方法的有效性。
总的来说,本文的贡献如下:
提出四种模型将局部图知识和全局图知识结合起来;
在两个典型图到文本的数据集上实现当前最佳结果;
对照实验表明该方法可以处理更大的知识图谱和更长的文本。
图谱到文本模型
图卷积网络(GCN)
建模图结构的主流方法是使用图卷积网络(GCN)。设






这里,





这里
全局图编码
在全局图编码器中,每个结点都和其他所有结点相连。我们可以定义聚集函数为所有其他结点特征的加权平均:

然后再使用多头注意力机制,将多个聚集向量拼接起来,就得到了聚集向量:

最后,同Transformer,我们可以定义结合函数为下述操作:

注意到,在全局图编码中,我们没有用到关系集合
局部图编码
同样,我们可以定义局部图编码器中的聚集函数为所有其他邻接结点的加权平均:

我们也用多头机制得到聚集向量

图表示
知识图谱中的结点是实体,因此,一个结点(实体)可能包含多个字符。为此,我们把三元组



结合局部知识和全局知识
本文提出两种方法、共四种模型去结合局部知识和全局知识。
这两种方法是并行编码和级联编码。并行编码是分别编码局部和全局知识,然后再把二者拼接起来;级联编码是先进行全局编码,然后将得到的全局编码特征向量作为局部编码的输入,再得到最后的结果。
同时,这两种方法都有层级和非层级之分。非层级即各自独立进行,层级即以层为单位进行。这四种模型示意图如下所示:

按照上图顺序,这四个模型分别称为PGE,CGE,PGE-LW和CGE-LW。
实验
本文在两个图谱到文本的数据集上实验:AGENDA和WebNLG。数据集介绍和实验设置详见原文。下表是AGENDA上的实验结果:
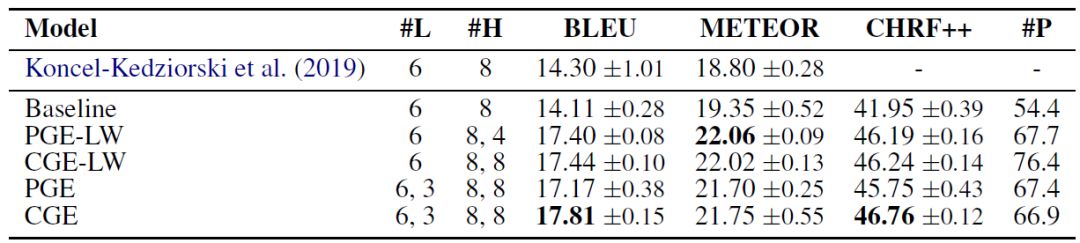
可以看到,模型CGE取得了平均最好的结果。并且所提出的四个模型都显著好于极限模型。
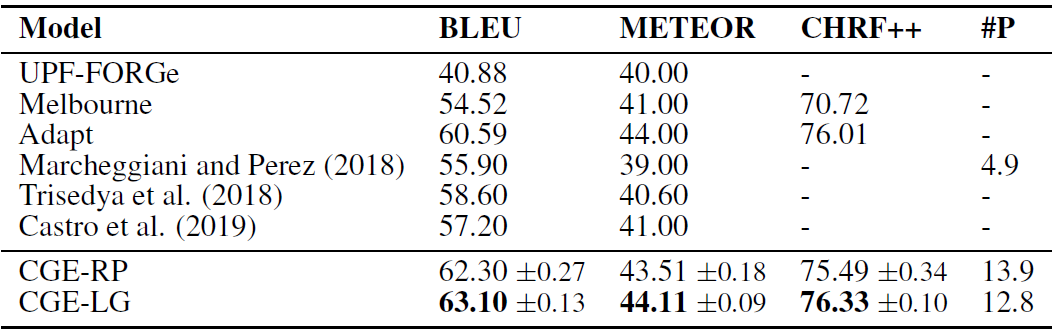
下表是在数据集WebNLG上的实验结果。CGE比之前的最好模型在BLEU值上高5-6个点,在METEOR上高2-3个点,表明其生成文本的拟合度是显著更好的。
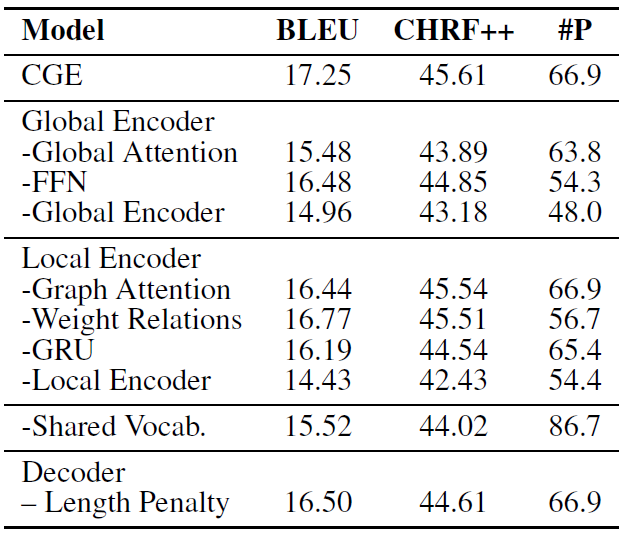
下表是对照实验的结果。无论是去掉全局编码器还是局部编码器,模型的结果都会受到影响,这说明二者的确建模了图谱的不同角度的知识,二者的结合会有更好的效果产生。
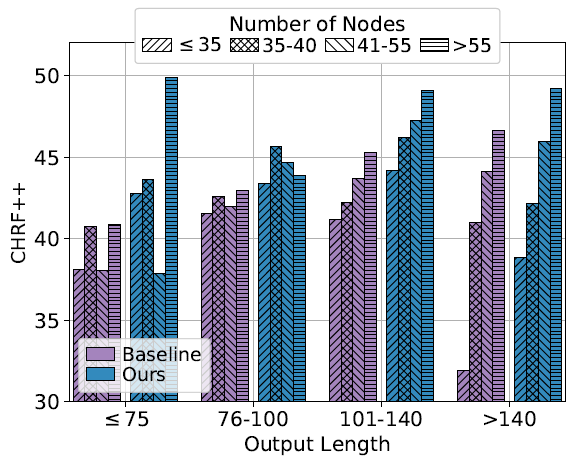
下图是输入结点数量、生成句子长度和效果之间的关系。总的来说,当生成长度一定时,输入结点越多,效果越好,当结点数量较少的时候,基线模型和本文模型都表现得不算好。
值得注意的是,当生成的长度更长,而结点数量很少的时候,本文模型能显著优于基线模型,这表明本文模型能够在图较小的时候充分利用结点和结点之间的知识,从而生成长文本。
小结
本文提出了一种结合图网络中全局知识和局部知识的网络结构,充分利用二者的优势更好地捕捉图谱信息。两个数据集上的实验结果显著优于之前的最佳结果,实现了当前的最好表现。
并且,通过对照实验发现,局部编码和全局编码对模型的效果都有不可忽略的影响,有助于生成更好的长文本序列。
如何进一步通过知识图谱更好地生成文本,不但是学术界未来关注的问题,也对工业界的发展有着重要推动作用。
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。





