银行业中的数据挖掘:贷款审批案例

本文为 AI 研习社编译的技术博客,原标题为 Data mining for Banking: Loan approval use case,作者 Youssef Fenjiro。
翻译 | 老周 校对 | 程炜 整理 | 凡江
本文相关概念
predictors 在统计学中,变量通常叫 predictors,机器学习中成为特征 feature。
本文中变量:统计学将变量叫做 predictors 而机器学习倾向于将其叫做 feature (特征)。
银行数据挖掘:贷款审批用例
银行的基本商业模式是作为金融中介——通过筹集融资和贷款(抵押贷款,房地产,消费者和公司贷款)。后者是 2 个主要贷款审批和欺诈组成的主要信用风险来源。在这篇文章中,我们将通过使用数据挖掘模型来关注贷款审批话题。
基于信用评分向零售和企业客户授予信用是关键风险评估工具,其允许通过“信誉评分”来最佳的管理、理解和量化潜在的债务人的信用风险,相对和“评判评分”相比,“基于信用评分”是更稳健和一致的评估技术。
零售投资组合中的信用评分反映了贷款申请时客户的违约风险,它有助于根据4个主要输入数据决定是接受还是拒绝信用申请:
客户信息:年龄,性别,婚姻状况,工作,收入/工资,住房(租金,自有,免费),地理(城市/农村),住宅状况,现有客户(Y / N),客户年数,总债务,账户余额。
信用信息:总金额,用途,月付金额,利率,......
信用记录:付款记录和拖欠(付款延迟),当前债务金额,拖欠付款的月数,信用记录长度,自上次信用以来的时间,使用中的信用类型。
银行账户行为:平均每月储蓄金额,最高和最低余额水平,信用额度,支付趋势,余额趋势,未付款数量,超过信用额度的次数,更改家庭住址的次数
特征选择和模型
数据挖掘通过显示哪些特征(因素)对特定结果影响最大来增加理解:关联矩阵有助于消除相关变量,特征选择方法(特别是多元相关)如逐步回归用于过滤不相关的预测变量; 它在每一轮中添加最佳特征(或删除最差特征),并在每次迭代中使用交叉验证评估模型误差,以最终保持最佳预测器子集(“特征选择”主题将在单独的文章中处理)。
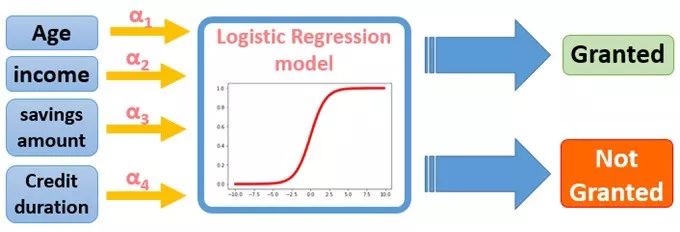
逻辑回归和决策树都是用于构建行为记分卡的流行分类技术(监督学习),它们是分析数据集的统计方法,分析独立变量的“预测者”(或解释者)和因变量的“响应”(或结果变量)之间的关系。在我们的例子中,我们试图根据上面给出的输入变量的值来估计给予贷款的概率。为简化起见,我们将变量数量限制在4个预测变量“年龄,收入,平均每月储蓄金额,信用期限”之后。
Logistic回归
在逻辑回归中,目标y是二元的( 授予 p = 1 /不授予 p = 0) 和 授予信贷的概率p。目标是找到下面的公式的系数αi 来预测P的logit变换。
Logit(p)= log(p / [p-1])=α0+α1.年龄+α2 . 收入+α3 . 储蓄金额+α4 . 信用期限
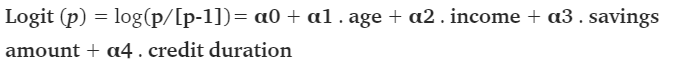
为了找到系数αi,我们用标记的历史数据训练分类模型,其中 已经知道“授予”/“未授予” 的决定,通过使用交叉熵作为损失函数来比较预测^ y
vs标签y:
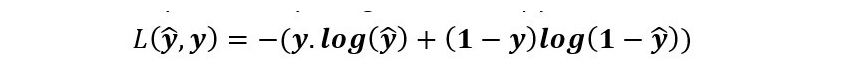
αi 的值是使用其一阶导数和梯度下降等优化算法最小化 L(α0,...,α4)的值:
决策树
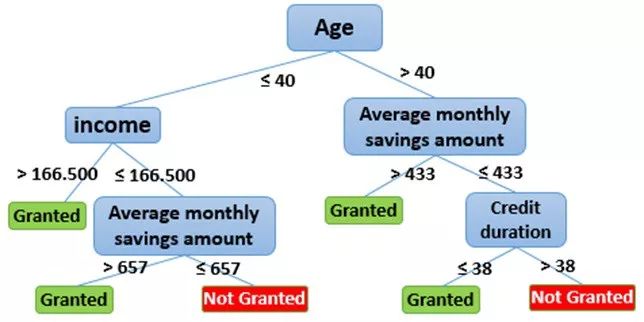
在决策树(如CRT,QUAID,QUEST,C5.0)中,我们构建分类模型,学习从数据特征推断出的决策规则以进行预测,生成具有与属性(输入变量)对应的决策节点的树结构。
步骤1:使用分割准则(如信息增益、增益比、基尼系数等)选择得分最高的属性,生成与目标变量相关的最纯粹节点(在我们的例子中,最佳区分“授予”和“未授予”的属性)。
步骤2:使用结果子集创建根分裂节点,然后通过重用分裂标准来选择下一个最佳属性以生成关于目标变量的最纯子节点,从而对每个子集重复步骤1。
步骤3:重复步骤2直到达到停止标准,例如:节点的纯度>预先指定的限制或节点的深度>预先指定的限制或简单地所有记录的预测值都相同(不再有规则可以是生成)
步骤4:应用修剪以避免过度拟合,通过使用标准来移除树的部分,这些部分提供很少的能力来分类并确定最佳树大小。为此,我们创建不同的数据集“训练集”和“验证集”,以评估修剪的效果并使用统计测试(如CHAID的卡方)来估计修剪或扩展给定节点是否产生改进。
我们有两种类型的修剪:
在对训练集进行完全分类之前,预修剪会提前停止生长树。
之后修剪允许树生长,然后将其修剪回来。
结论
Logistic回归是一种流行的建模记分卡,其得分在0到1之间,与只有一组有限的得分值(每个叶节点=特定得分)的决策树相反,因此,它可能在区分债务人违约风险方面不够精细。
此外,我们可以使用其他模型,如判别分析,神经网络和支持向量机Logistic回归是一种流行的“建模记分”分类模型,其得分在0到1之间,与只有一组有限的得分值(每个叶节点=特定得分)的决策树相反,因此,它可能在区分债务人违约风险方面不够精细。
此外,我们可以使用其他模型,如判别分析,神经网络和支持向量机(SVM); 或者我们可以通过使用集成学习算法方法(如bagging )来组合它们以获得更高的稳定性和提升以获得更高的准确度(集成学习算法将在单独的文章中解决)。
原文链接:https://medium.com/@fenjiro/data-mining-for-banking-loan-approval-use-case-e7c2bc3ece3
点击文末【阅读原文】即可观看更多精彩内容:
为什么你需要改进训练数据,如何改进?
如何成为一名数据科学家?Yann LeCun 的建议也许能给你答案
数据工程师必看:分析数据时常见的 7 类统计陷阱
身为数据科学家的你,岂能错过这些顶级的 Github 代码仓库 & Reddit 讨论串
等你来译:
立志成为数据科学家?掌握以下基础
如何将你的神经网络速度提高 10 倍
医学图像文本注释的实例
7分钟了解Tensorflow.js
想知道关于数据挖掘更多知识?
欢迎点击“阅读原文”
或者移步 AI 研习社社区~





