CVPR2019满分文章 | 强化跨模态匹配和自监督模仿学习(文末源码)


首先,祝贺我党在3月成功举行了“两会”,希望我党越来越强大。在接下来将会有好几场关于IEEE会议,也会着重指向接下来人工智能的发展风向标,有兴趣的同学可以持续关注。
今天,“计算机视觉战队”给大家带来的是CVPR2019会议上几乎满分paper,那我们就开始一起学习吧!
简 介
深度学习发展迅速,很多技术已经落实到具体产品,给我们生活带来了很多方便,未来会越来越多的技术实现,实现人类第四次人工智能革命。

今天说的就是一个导航技术——视觉-语言导航(Vision-language navigation,VLN),其任务就是指在真实的三维环境中让具有实体的智能体进行导航并完成自然语言指令。
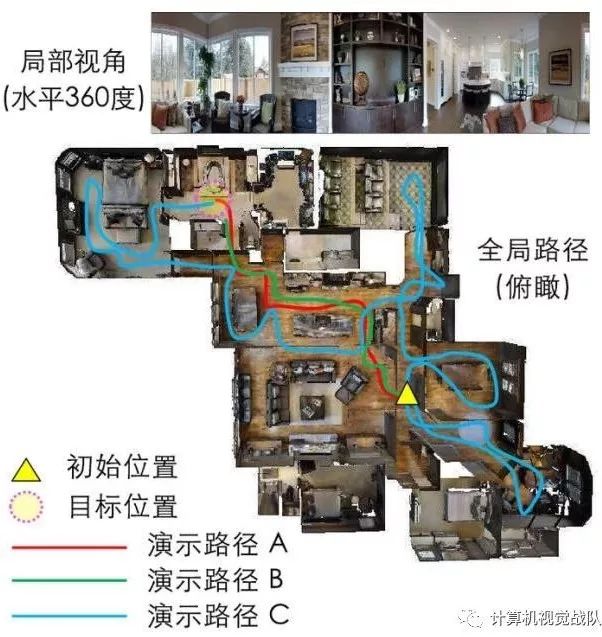
今天讲的这个技术,主要解决了三个挑战性问题:1)跨模态参照;2)糟糕的反馈;3)泛化问题。
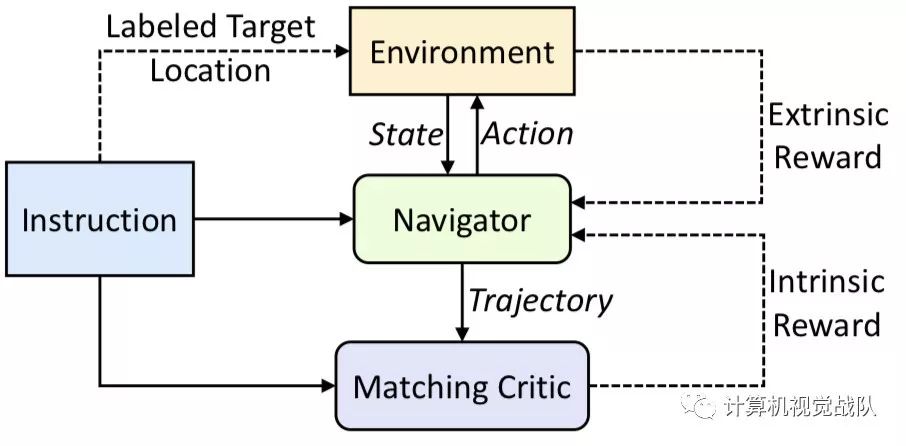
首先,提出了一种新的强化跨模态匹配(RCM)方法,它可以通过强化学习的方式同时促进局部和全局的跨模态参照,具体就是使用了一个匹配指标,它成为了鼓励模型增强外部指令和运动轨迹之间匹配的固有反馈,模型也用了一个推理导航器,它用来在局部视觉场景中执行跨模态参照。
在一个VLN benchmark数据集上进行的评估结果表明,提出的RCM模型大幅超越已有模型,SPL分数提高了10%,成为了新的SOTA。
之后,为了提高学习到的策略的泛化性,进一步提出了一个自监督模仿学习(SIL)方法,通过模仿自己以往的良好决策的方式探索未曾见过的环境。
在此,作者们表明了SIL可以逼近出更好、更高效的策略,这极大程度减小了智能体在见过和未见过的环境中的成功率表现的差别(从 30.7% 降低到 11.7%)。
Model
导航πθ是一个基于策略的代理,把输入X映射在一系列行为指令。在每一个步骤中,导航器从环境接收一个状态st(视觉场景),并需要在本地可视场景中接收文本指令。因此,设计了一个跨模态推理导航,它可以在序列学习轨迹历史、文本指令的重点和局部显著性,从而形成一个跨模态推理路径,以鼓励两种模态在步骤t处的局部动力学。
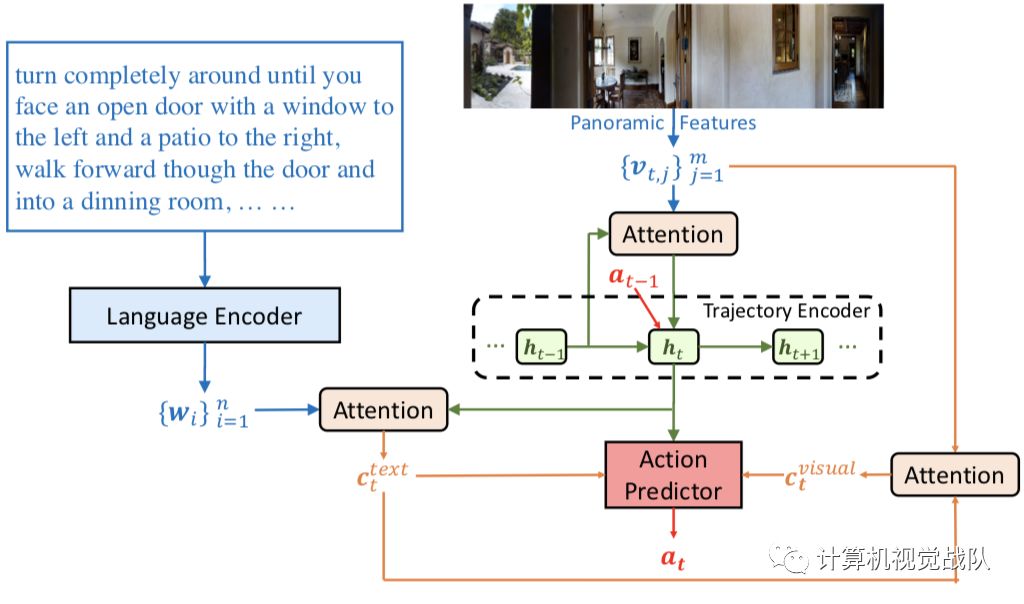
上图显示了在时间步骤t展开版本的导航器。为导航器配备全景,将m个不同的视角分为图像块,所以全景特征从视觉状态St提取的可以表示为{vt,j}j=1, vt,j表示图像块在视角j的预训练CNN特征。
History Context
一旦导航器运行一步,视觉场景就会相应地发生变化。轨迹τ1:t的历史到步骤t由一个基于注意力机制的轨迹编码器LSTM编码为历史文本:
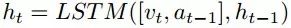
请注意,后面采用的是都是点积注意力,将其表示为如下,(以上面的视觉特性为例):
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems, pages 5998–6008, 2017.
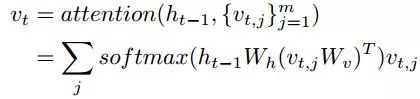
Visually Conditioned Textual Context
记忆过去可以使人们认识到当前的状态,从而理解下一步应该关注的单词或子指令。因此,进一步学习了以历史上下文为条件的文本。让语言编码器LSTM将语言指令x编码成一组文本特征{wi}ni=1。然后,在每个时间步骤,文本被计算为:
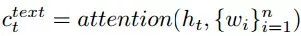
Textually Conditioned Visual Context
要知道在哪里需要动态理解语言指令,因此基于文本上下文计算视觉上下文,如下:
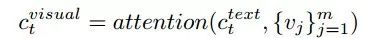
Action Prediction
最后行为预测器考虑历史上下文ht、文本上下文ct和视觉上下文cvisual,并在此基础上决定下一步的方向。它使用双线性点积计算每个可导航方向的概率Pk,如下所示:
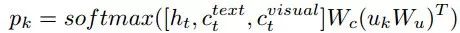
Cross-Modal Matching Critic
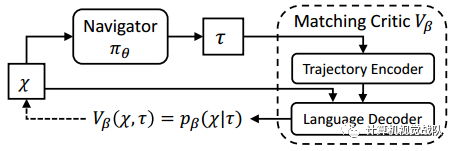
除了来自环境的外部奖励信号之外,还导出了匹配评论vβ提供的内在奖励,以鼓励语言指令x与导航器πθ的轨迹之间的全局匹配:
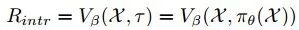
因此,采用一种基于注意的序列到序列语言模型作为匹配评论vβ,用轨迹编码器对轨迹τ进行编码,并给出用语言译码器生成指令x中每个字的概率分布。因此内在的回馈:
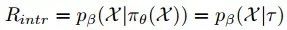
Learning
Self-Supervised Imitation Learning
最后一部分介绍了通用视觉语言导航任务的RCM方法,该方法的标准设置是在可视化环境中训练Agent,在未见环境中进行测试。在本节中,我们将讨论一个不同的设置,其中允许代理在没有地面真相演示的情况下探索不可见的环境。这是有实际好处的,因为它有利于终身学习和适应新环境。
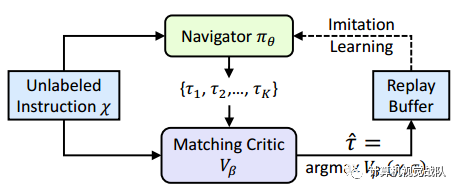
为此,提出了一种自我监督的模仿学习(SIL)方法来模仿Agent自身过去的好决策。如上,给定一个自然语言指令x,没有成对的演示和GT目标位置,导航器生成一组可能的轨迹,存储最佳轨迹,其通过评论vβ匹配到一个replay buffer中确定的,公式如下:
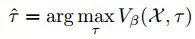
匹配的评论之前介绍的循环重建奖励来评估轨迹。然后,在replay buffer中利用好的轨迹,Agent确实在自我监督下优化了以下目标。目标位置未知,因此不受环境的监督。
实验及结果
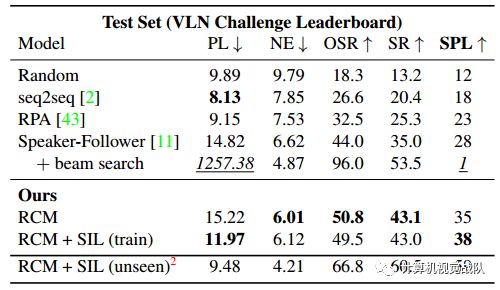
在R2R测试集上的结果
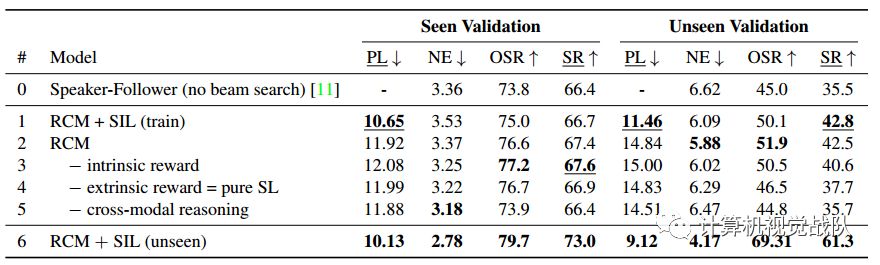
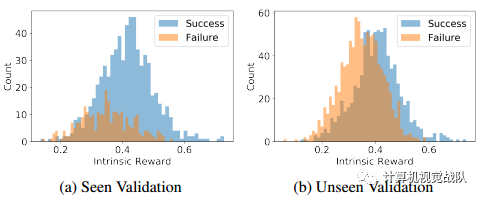
已见和未见验证集的研究结果
可见和未见验证集上的可视化

上图:左:出了门,向左转向楼梯,一路走上楼梯,在楼梯顶上停下来;右:右转下楼梯,左转,一直走到洗衣房,在那儿等着。
特别是,上面的两个例子,两者都具有很高的内在回报。在(A)中,Agent成功地到达了目标目的地,对自然语言教学有了全面的理解;而在(B)中,内在回报也很高,这表明了主体的大部分行为都是好的,但也值得注意的是,在结束时,Agent没有认出洗衣房,这说明了在导航任务中,更加精确的视觉基础训练的重要性。
如果想加入我们“计算机视觉战队”,请扫二维码加入学习群。计算机视觉战队主要涉及机器学习、深度学习等领域,由来自于各校的硕博研究生组成的团队,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。





