哈工大SCIR取得国家电网调控AI创新大赛赛道2(Text2SQL)冠军
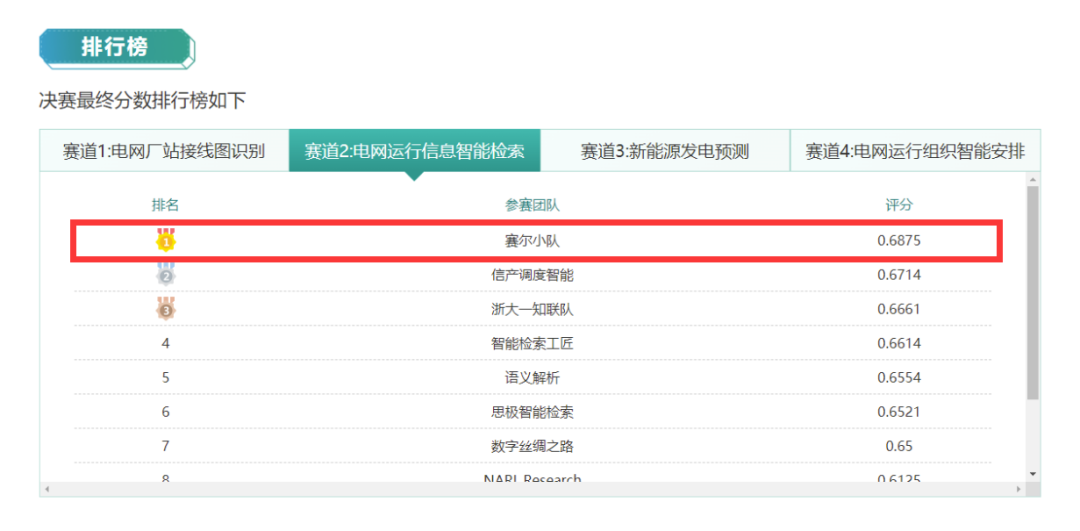
近日,来自哈工大社会计算与信息检索研究中心(HIT-SCIR)的“赛尔小队”以68.75的成绩夺得国家电网调控人工智能创新大赛-电网运行信息智能检索赛道(Text2SQL)冠军。团队成员包括窦隆绪、潘名扬、王丁子睿,指导教师为车万翔教授。
比赛介绍
为更好服务国家“双碳”战略目标,助力以新能源为主体的新型电力系统构建,应用AI赋能电网调控运行,国家电网有限公司于2021年8月至10月主办“国家电网调控人工智能创新大赛”,汇聚全社会产、学、研创新力量,共同推动调控领域人工智能技术攻关,探索智能调控技术解决方案,强化调控领域人工智能应用创新。国家电网调控人工智能创新大赛评测举办以来吸引了众多知名高校和研究机构参加,其中包括清华大学、浙江大学、南京大学、中国科学技术大学、哈尔滨工业大学、中国科学院大学、西安交通大学、天津大学等高校,以及众多所属电力系统的研究机构。
赛题介绍
电网调控系统经多年运行汇集了海量的电网运行数据,存储于数据库或文件系统中,呈现出规模大、种类多、范围广等特点,对于这类数据的获取和分析通常需要通过机器编程语言与数据库(或文件系统)进行交互操作,给数据分析带来了较高的门槛。数据挖掘深度不够、数据增值变现能力弱等问题也逐渐显现。亟需通过人工智能技术手段,实现人机交互方式变革,提高数据分析挖掘效率,激活数据价值,促进数据价值变现。
针对电网调控系统数据以结构化、半结构化形式存储特点以及海量数据分析繁琐低效的问题,要求参赛者利用语义解析技术训练AI智能体,理解调控系统常见问题,解析数据库的表、属性、外键等复杂关系,最终生成SQL语句并在数据库中执行获得问题答案,为用户提供自动、高效、精准的信息检索服务。
Text2SQL 任务介绍
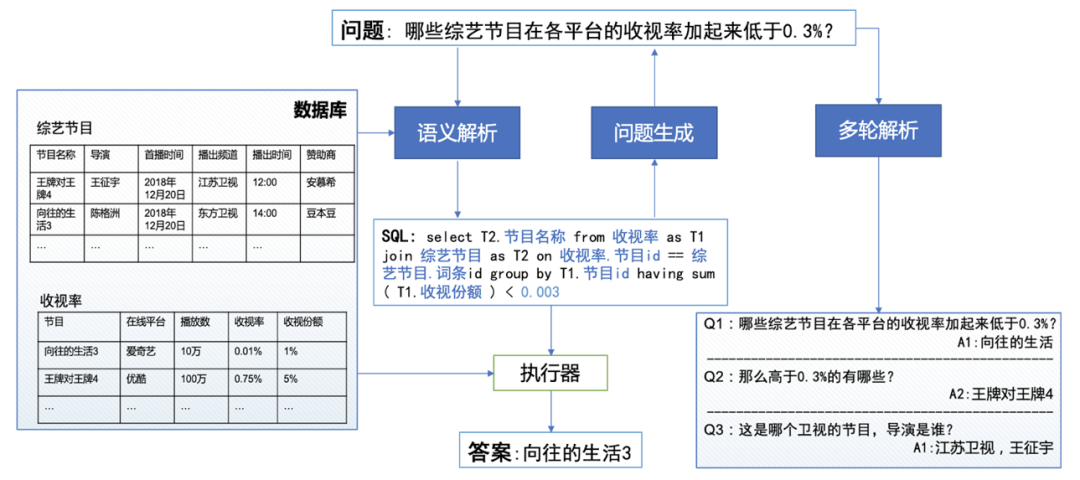
在现实生活中,有许许多多的数据库,存储着各行各业的信息,比如学校的选课信息、成绩信息,公司的账务信息、人员流动。SQL是一种数据库查询语言,具有极大的灵活性和强大的功能,然而对于普通人来说,SQL学习门槛比较高。即使对于计算机从业者来说,想要针对不同的数据库和应用场景,编写大量的并保证正确率的SQL语句,也比较麻烦。如果我们能够有一个工具,自动地把我们的描述转化为SQL查询语句,再交给计算机去执行,就能方便地对数据库进行查询,那就大大提高了我们的生活和工作效率。
Text2SQL就是为了便捷访问数据库存在的一种技术,具体是指在给定关系型数据库(或表格)的前提下,根据用户的提问生成相应的SQL查询语句。上图给出了一个具体的实例,问题为:哪些综艺节目在各平台的收视率加起来低于0.3%?可以看到该问题对应的SQL语句是比较复杂的,需要同时对2个表格进行查询。
具体介绍可以参考我们之前的“赛尔笔记 | 一文了解Text-to-SQL”:https://mp.weixin.qq.com/s/ucFtWopoErtUCYDTLv2kFg,点击文末“阅读原文”即可查看。
夺冠系统
相比于传统的Text2SQL任务,此次比赛的输入数据表格太多,无法被现有模型一次编码成功,根据我们在训练集上的统计,每个问题最多涉及5个表格的内容。于是,我们将整个方案分为3个步骤:
(a)表格检索:根据用户提问从数据库中检索相关的表格。这一部分,我们在前期基于BERT构建了一个分类模型,通过训练集导出的检索数据进行了训练,但发现由于数据量不够而且分布太稀疏,导致训练结果并不理想,召回率只有70%左右。于是我们通过进一步观察,发现了比较明显的规律,决定使用基于规则与统计相结合的方法,构建表格检索模型,最终的recall@5(前5个表格中包含所需表格)达到了94%左右。
(b)语义解析:模型输入为表格与用户的问题,输出为SQL语句。这部分我们使用了预训练语言模型mBART作为模型结构,将整个Text2SQL看做了一种特殊的翻译任务,直接使用Seq2Seq的方法进行了模型训练。具体做法为,我们将序列化后的数据库直接与问题拼接,作为输入。而对于SQL语句,我们做了一些规范化处理,例如去掉表格代号例如T1、T2,于是我们将这样规范后的SQL作为输出。语义解析模型能够在测试集上达到79%的准确率。
(c)自动数据合成:考虑到深度学习模型对于数据量的依赖程度,我们基于mBART反向训练了翻译模型(根据SQL生成问题),进一步扩充了训练语料。最终我们在原有2000条训练集的基础上,合成了高质量的36000条数据,使得最终模型进一步提高7%。
创新性
我们主要的创新点为使用大规模预训练语言模型作为基础的模型架构,直接将Text2SQL任务看作了一种翻译任务,这样做有以下几个好处:一是可以有效利用目前大规模预训练模型的能力,因为翻译任务和预训练阶段的语言模型生成任务的目标更为接近,更能有效挖掘模型潜力;二是整体流程简单,只需要构造标准的输入输出,即可完成训练,借助Fairseq框架的优越工程实现,相比于PyTorch的实现方法,我们的方案整体训练时间和效率都很高,仅12个小时便能完成模型训练和预测的工作;三是利用数据增强技术,在不借助额外人力资源的情况下,获得了大规模高质量的合成数据,并借助数据验证,保证了合成数据的有效性。
本期责任编辑:冯骁骋
理解语言,认知社会
以中文技术,助民族复兴





