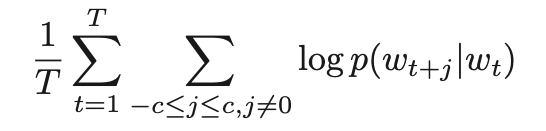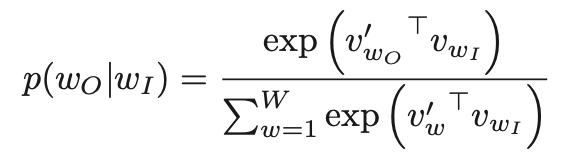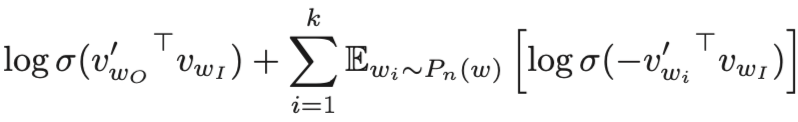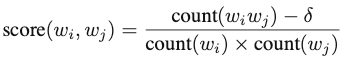关于作者: 张正,坐标巴黎,上班NLP,下班词嵌入。
都已经 2020 年了,还在介绍 word2vec?
对。词嵌入(word embeddings)向前可以追溯到上世纪 50 年代(虽然那时还不叫这个名字,但语义如何被表征的假说已经提出了),向后更是随着一个个芝麻街成员的强势加入,恨不得天天都是该领域的新 SOTA。所以不如找个中间的里程碑 word2vec 先挖一坑,毕竟想那么多,都没做来得实际。
当然,网上关于 word2vec 的优秀讲解已经非常多了,这里只希望努力讲出些之前没被注意到但实际又可能值得关注的点;也尽力不局限于当年,试着以 2020 年的角度去回看。
介绍分为三个部分,分别对应 Tomas Mikolov(托老师)2013 年经典的托三篇:
1. word2vec(一):NLP 蛋糕的一大块儿: 围绕 Efficient Estimation of Word Representations in Vector Space 。会谈到:word2vec 与自监督学习;CBOW 与 Skip-gram 的真正区别是什么。
2. word2vec(二):面试!考点!都在这里: 围绕 Distributed Representations of Words and Phrases and their Compositionality 。会谈到:真正让 word2vec 被广泛应用的延伸与改进。
3. word2vec(三):当我谈词嵌入时我谈些什么: 围绕 Linguistic Regularities in Continuous Space Word Representations 。会谈到:词嵌入的评价(evaluation),尤其是词类比(word analogy)任务。
那么,我们正式开始。
NLP蛋糕的一大块儿
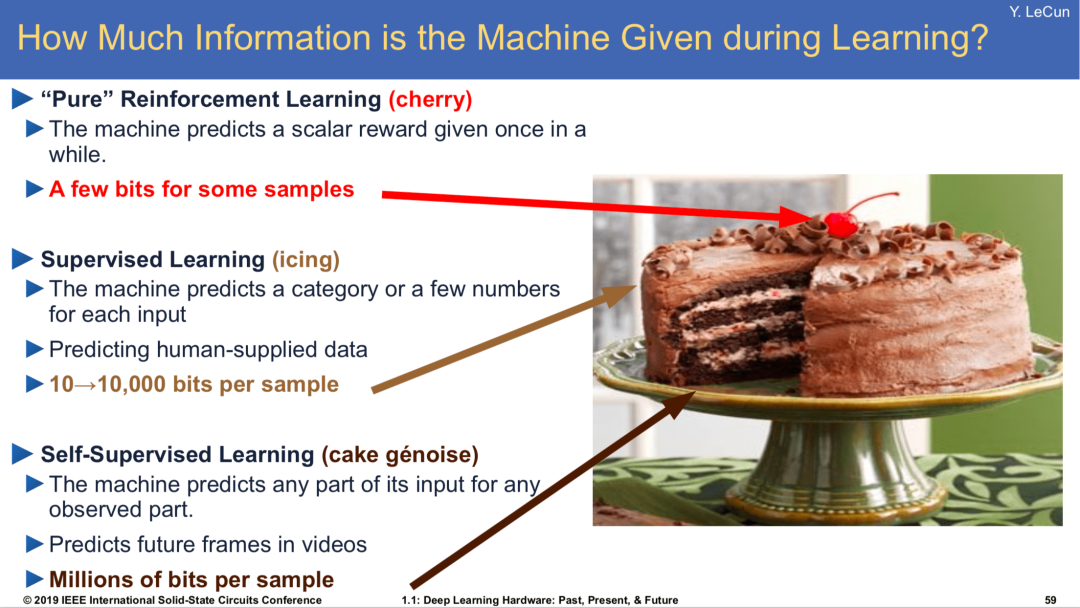
为了进一步合理化从 word2vec 谈起这个选择,我搬出了杨老师(没错,就是 Yann Le Cun 的“杨”)蛋糕 2.0 版。“众所周知”,杨老师在 NIPS 2016 端出了他的人工智能大蛋糕,并在 2019 年升级配方,有了我们现在的 2.0 版。
简单介绍一下这款蛋糕。杨老师说:“如果智能是一个蛋糕,那么蛋糕的大部分是无监督学习,蛋糕的糖衣是有监督学习,而蛋糕上的樱桃是强化学习。”
这一说法强调了无监督学习的重要性,但“无监督”本身是一个很玄乎的词,真的是字面意义上的一点监督都没有吗?为了明确这一点,蛋糕 2.0 版对“无监督”作了替换:
可以看到,“无监督”被替换成了“自监督”。杨老师也亲自在一个神秘的网站上作了一番解释:
“自监督”显然比“无监督”更准确:不是没有监督,而是“系统基于输入的一部分去学着预测另一部分”。相比于有监督学习通常需要人工标注,自监督学习显得更加“自给自足”。
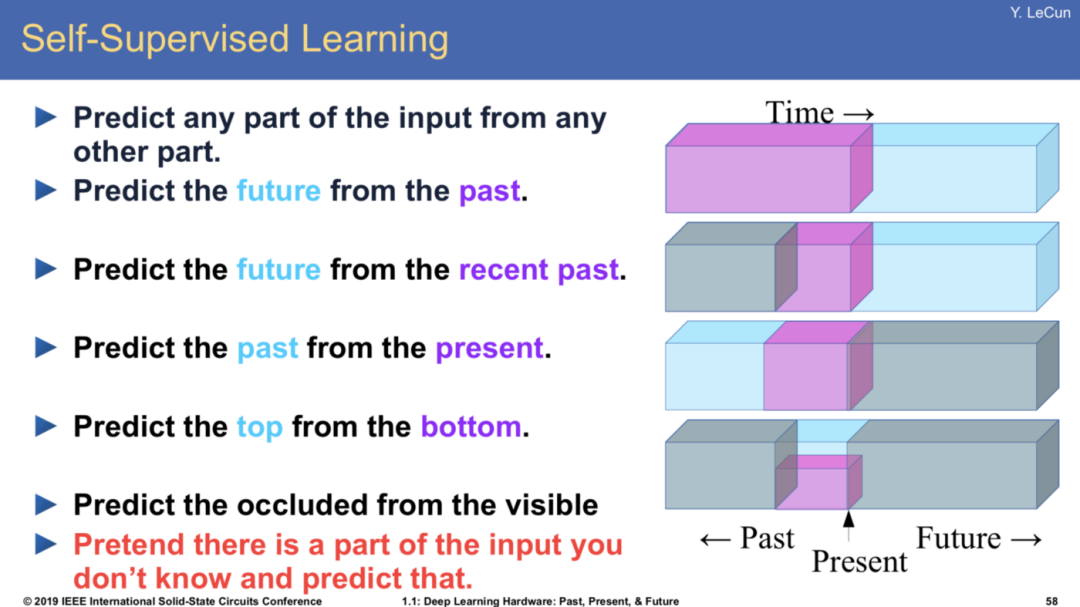
这可能也是自然语言处理(NLP)相较于其他领域(如机器视觉 CV)在本次人工智能浪潮里的独特之处:这一次,NLP 一开始就把技能点到了自监督学习的科技树上。 而 word2vec 无疑是此科技树上一早期重要技能。(终于又绕回到 word2vec 了。)
1.2 假装读过论文 之 word2vec的诞生
如果你去面试 NLP 相关职位,被问到 word2vec 一定不应该感到意外。解释 word2vec 的好博客、好视频真的很多。但是最传统(最硬核?)的方法还是读论文。以下我们通过 Abstract 梳理相关论文,顺带提一些或“众所周知”、或奇怪的知识点。
论文标题: Efficient Estimation of Word Representations in Vector Space
论文链接: https://arxiv.org/abs/1301.3781
“我们提出两种新的用于基于非常大的数据集来计算词的连续向量表征的模型架构。(我们)通过词相似度任务来衡量这些(向量)表征的质量,并将其结果和基于不同神经网络类型并获得之前最好结果的模型做比较。
我们发现(我们的模型)在准确度上(相较于其他)有了大的提升并且是以更小的计算量为代价。即它从一个 16 亿词的数据集上训练出高质量的词向量只花了不到一天的时间。此外,我们还证明了这些(词)向量在我们(自己的)用来衡量词在句法和语义相似度的测试集上获得了史上最佳结果。”
作者托老师(没错,就是 Tomas Mikolov 的“托”)在 2013 年非常高产,该文章是关于 word2vec 的第一篇,但不是其关于词嵌入研究的第一篇。
在此之前还有 Linguistic Regularities in Continuous Space Word Representations , 著名的“国王-男人+女人约等于女王”就出自这里(后来根据此类比任务延伸出的关于 bias 研究非常多,出发点是好的,但不少文章其实是无病呻吟,后来统一被另一文章彻底打脸,我们在 word2vec(三)中会具体聊到)。
回到这篇文章,托老师之所以研究新的词嵌入训练模型是因为他发现此前没有方法可以成功地在大文本数据集上训练出维度在 50 到 100 之间的词向量 。因此,他出手了:他要提出一种新的模型,不仅在传统词相似度任务上效果好,还在他自己提出的词类比任务上效果好。
新模型 word2vec 受到之前 NNLM 的启发和影响(Neural Network Language Model,神经网络语言模型)但是更简单,省掉了 NNLM 中非线性的隐含层。
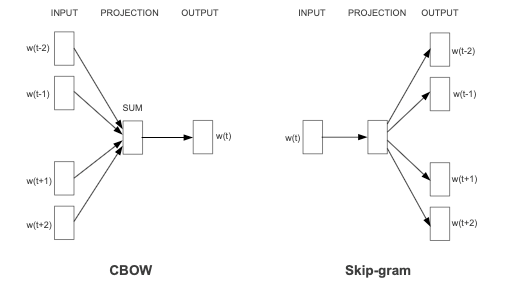
相信上图大家已经见过无数次,此刻内心必然毫无波澜。CBOW 和 skip-gram 就是如此平淡无奇:一个用上下文来预测当前词,一个反过来用当前词来预测上下文。那么,下面这个结构应当叫 CBOW 还是 skip-gram,抑或是别的什么?
先说结论,叫 skip-gram(证据文末讲,目前不重要)。即使它用上下文来预测当前词,它还是叫 skip-gram。由此可见,方向并不是 CBOW 和 skip-gram 的核心区别。 那么核心区别是什么?是 CBOW 全称 Continuous Bag-of-Words 中的 “bag” 或结构图中的 “SUM”。
CBOW 名字中包含“词袋”二字,意思是说对于上下文这些词,无论顺序、不分前后、一视同仁(当然之后有一些文章讨论顺序、前后等的影响),把它们的词向量全部拿来平均后用于当前词的预测。
相对于 CBOW 的多对一,Skip-gram 更加专一:一个输入词预测一个输出词。此“多对一”和“一对一”的区别,也正是 “CBOW 比 skip-gram 训练快,但 skip-gram 对生僻词训练效果更好”的原因。
文章后面的篇幅主要是实验对比分析,虽然词嵌入质量的评价是一个很值得讨论的大问题,但目前你只需要知道作者说 word2vec 在他们提出的词类比任务上效果很好就 ok 了。
1.3 假装读过代码 之 托老师的口是心非
最后我来解释下之前的结论,因为一定有人觉得用上下文来预测当前词,就算一对一,也不能叫 skip-gram。其实托老师已经给了我们答案:虽然他在论文中只字未提,但在 word2vec 源代码中,就是用上下文来预测中心词的。
甚至早在 2013 年就有人提问并得到了托老师的回复:
▲ 托老师亲笔
托老师的大概意思是:只看一组中心词和上下文,方向的改变是导致了训练词对的不同,但是如果你以一个句子为整体分析,最终获得的训练词对是一样的。而且如果一句一句的更新权重,那对训练本身也是没影响的。改变顺序只是为了更有效地利用缓存,训练得更快。
我承认,这个奇怪的知识点一般没什么用,尤其当你只是包的搬运工的时候。但是,如果你要在已有包的基础上做魔改,一定要注意这些作者“口是心非”(或者文是码非?)的细节,不要想当然。
你可能又会说,word2vec 源代码太老了,我用 gensim。难道我会告诉你,我就是一开始在 gensim 时遇到这个问题,以为 gensim 写错了,然后一路看到 word2vec 源代码,发现 gensim 没错,只是完全遵循了源代码的算法吗。
面试!考点!都在这里
“截至发稿前”,Google Scholar 上 Efficient Estimation of Word Representations in Vector Space 被引用 14957 次,而 Distributed Representations of Words and Phrases and their Compositionality 被引用 18797 次,对此我想感叹三件事:
1. 在研究上,我们经常有一种“洁癖”,即原创、革新比改进要高一等。但真正让 word2vec 被广泛应用的是它的几项重要延伸与改进。上面两篇文章的关系就像是 iPhone 4 和 iPhone 4s,引用就像是用脚投票,谁好用选谁。
2. 在研究上,我们还有另一种“洁癖”,即论文要看出处(尤其当你自己引用的时候),顶会自然要高人一等。第二篇文章有 NIPS 加成,难道这才是核心原因?
3. 还好这两篇文章是相同一作(毕竟这个年头,模型缩写一样都要争好久)。
说完废话,回到论文本身,按照惯例,先尬翻 Abstract。然后谈所有相关考点。
论文标题: Distributed Representations of Words and Phrases and their Compositionality
论文链接: https://arxiv.org/abs/1310.4546
2.1 Abstract
“最近介绍的 continuous Skip-gram 模型是一种用来学习高质量的分布式向量表征的有效方法,(这些表征)可捕获大量精确的句法和语义词关系。在本文中,我们提出了几种扩展,可以同时提高向量的质量和训练速度。
通过对频繁出现的单词进行二次采样 ,我们可以显着提高速度,并且还可以学习更多常规单词的表征。我们还介绍了负采样 ,作为 hierarchical softmax 的一种简单替代。
单词表证的固有局限性是它们对词序的无视以及无法表示习惯用语。例如,‘加拿大’和‘航空’的含义不能轻易地组合以获得‘加拿大航空’(的含义)。受此示例的启发,我们提出了一种用于在文本中查找短语的简单方法,并表明学习数百万个短语的高质量向量表征是可行的。”
知乎上详细讲解推导 word2vec 的硬核文章非常多,建议与本文“搭配服用”,本文的作用是把其中重要的点提出来讲讲。
2.2 “word2vec约等于SGNS”
Word2vec 约等于 SGNS (skip-gram with negative-sampling) 或许是一个有争议的说法,但从应用的角度来说问题不大,如果你要使用 word2vec,这应当是第一个想到的默认配置。
顺带提一句,文章 Distributed Representations of Words and Phrases and their Compositionality 中所有的讨论、实验都是基于 skip-gram 模型之上的。
2.3 考点!考点!考点!
如果你准备 NLP 面试,skip-gram 模型的目标函数真的是哪怕死记硬背也得记下来!程序员 onsite 白板算法不意外,对于算法岗,白板这个目标函数也是不意外的。
看着上面的公式,正好脑补一个 skip-gram 的训练过程,问下自己这些字母符号都是什么含义:假设训练文本有 T 个词,第一个求和就像一个指针从第一个词一直指到最后一个词,每个被指到的词都是就是当前词(或称中心词);
再看第二个求和符合,c 是一个固定的参数,代表中心指针向前或向后能取到多少个词,换句话说,c 划定了上下文的范围。那么把前两个求和符合连在一起,就有了一个浮窗(window)从第一个词一直滑到最后一个词,浮窗正中间自然是当前词,前后各 c 个词就是其对应的上下文;
回想一下上一篇文章提到的 skip-gram 是怎样训练的,通过中心词来预测它的上下文中的词,那么很显然求和符号后面就是这个预测概率。整个目标函数就是为了最大化 log 预测概率的平均值。
标配版的 skip-gram 用 softmax 函数来计算该预测概率:
▲ 思考题:这些字母符号都代表什么?(建议带着问题读论文,达成“假装读过论文”成就)
2.4 此词典非彼词典
W 是整个词典的大小。简单解释下 word2vec(也是整个词嵌入)中词典的意思:词嵌入训练的目的是为了给词分配向量,到底是给哪些词分配呢?
肯定不会是所有的词,因为你的训练文本里可能根本没见到某些词(如何计算没见过的词的词向量是个有趣的问题,这个坑我很快会在 FastText 的文章里填一部分)。
还有些词即使见到,它们出现的次数也不多,或者有些词你根本不关心。词典的目的就是用来规定到底关心哪些词,最终要算出哪些词的词向量。
说到这里突然忍不住题外话一段(这里是假装读过代码环节)。你在用 Gensim 等训练 word2vec 时,会发现其实程序跑了两遍,第一遍非常迅速,因为它啥都没训练(dry run),这一遍的目的就是为了建立词典,通常词典的建立受一些参数影响,如词典大小的上限,词频下限等。
如果你对自己的词典有更加明确的要求,其实可以跳过第一遍训练,并替换自己的词典。
2.5 Negative sampling
为什么要专门讲 W?因为标配版的 skip-gram 在实际应用中并不实用,问题就出在字母 W。我们已经知道了 W 是整个词典的大小,带入 softmax 公式中会发现每一次计算都要把整个词典过一遍,计算量非常大。因此才有了 negative sampling,用以减少计算量的同时期望达到近似效果。
是的,这个公式也是考点。注意一点它替代的是第一个公式中的 log 预测概率,不单是预测概率,还有 log。
如果 negative sampling 是 skip-gram 至尊版的话,就像所有汽车、或者显卡一样,标配版和至尊版之间还有各种高配版、精英版等等(如 Hierarchical Softmax 或 Noise Contrastive Estimation),这里不展开讲,知乎有很多精彩的硬核文章。
简单来说,negative sampling 是简化版的 Noise Contrastive Estimation,NCE 核心想法是一个好的模型能在噪声中分辨出正确的数据。
因此可以看到上方公式有两部分组成:第一个部分代表“正确的数据”,即通过中心词预测正确上下文词的概率;第二部分是“噪声”,即通过中心词预测 k 个噪声词的概率,这个概率当然越小越好。因此可以看到一个负号。
那么对于 negative sampling,核心问题自然是如何定义噪声,也就是上方公式的 P(分布)是如何定义的。作者的答案是通过试验,发现噪声分布基于词频统计,再用指数函数 3/4 稍微调整一下效果就很好。并没有理论上的解释。
此处感性的解释是:我给你一个训练文本,指着其中一个词,很显然我们知道正确的上下文应当是什么(附近的词),那么错误的噪声呢?既然是噪声,意思就是也不能太明显不是,要有干扰的,也经常出现的。
一个词在整篇文本中出现的频率越高,它出现在训练词周围的概率自然也相对较高(此处我们不考虑太多搭配、顺序,简单地将训练文本想成一个词袋),那它就是很好的干扰项,即噪声。
2.6 把短语一视同仁
Word2vec 的论文前前后后读过 5 遍以上,每次都能有些新的理解或发现。之前对于短语的提取和训练部分,我一直把它当作一个文本预处理的小 trick,直到最近一次读时才对这部分有了些新的思考(其实本应该更早发现短语在这篇论文中的重要性,毕竟标题就有“短语”,abstract 更是单独用了一段来讲)。
之前做学术研究时,“词嵌入训练”对我来说就像它的名字一样,我基本只关注“词”级别,文本来了简单预处理后就喂给模型训练了,因为大部分常用的直接评价词嵌入质量(intrinsic evaluation)的数据集都是基于词(word)的。而到了实际工业应用中,突然发现有太多短语、词组等需要关注。
获得短语的词嵌入并不难,其实就是修改训练前的词典部分(“此词典非彼词典”中已经提过)把短语添加进去。如果你完全清楚要关注的短语有哪些,直接全部加到词典就行了。因此文章实际讨论的问题是在不知道文本中有哪些短语的情况下,如何在文本中找出来。
者给出的解决方案非常简单,就是基于词频的统计,找出那些在一起经常出现而在其他上下文中不常出现的词组。
该方法在文本上过第一次时可以找到两个词(word)组成的词组,在此基础上过第二遍就能找到三个词组成的词组,以此类推。
2.7 A+B=?
“国王相对于男人相当于女王相对于女人”的例子大家应该都不陌生(陌生的话可以出门左拐看我关于 word2vec 的另一篇文章),有了词组嵌入的加持(倒不一定必须有词组),作者提出了一个类似的想法:“中国+货币 约等于 人民币”、“中国+航空公司 约等于 中国南方航空”等等。
作者通过也列举一些符合这种观察的例子,他给出的解释是:词向量可以被看作是其上下文分布的表征;a 与 b 相加得到向量可以看作是一个 feature,只有与 a 和 b 在相同上下文经常出现的词才会接近该 feature。我个人总觉得作者是受了短语识别思路的影响。
我个人对该现象持保留意见,不过它至少可以说明,好的词嵌入空间,不仅关乎两个词之间的“距离”(词相似度)、也关乎词在整个空间的相对位置(“a+b=c+d” 和 “a+b=e”)。
如果 word2vec 模型架构师食材的话,上面提到的种种改进就是佐料。对于 word2vec 的成功,为什么佐料比食材还重要?因为一个简洁有效的模型,背后反而是更多的细节做支撑的。在应用时我们或许感觉不到,因为这些细节已经有了足够好的默认设置。
但是仔细去探究这些默认设置、了解公式中每一个字母的含义后,会发现处处都有选择,最终这些好选择被匹配到一起并隐藏起来后才让一个模型真正实用、好用起来。
对于研究者,反而可以深究一下这些选择是不是最好的、为什么?比如噪声的分布,连托老师也只是说实验所得,那会不会有更好的噪声分布?上下文的选择会不会有更好的方法?词向量的维度多少最好?等等。
word2vec 的相关研究已经很多了,模型本身也老了,但是这种探求方法对于其他模型也是适用的。如果拿不出新食材、那就在佐料上下下功夫。
当我谈词嵌入时我谈些什么
3.1 论文 论文标题: Linguistic Regularities in Continuous Space Word Representations
论文链接: https://www.aclweb.org/anthology/N13-1090/
论文标题: Fair is Better than Sensational: Man is to Doctor as Woman is to Doctor
论文链接: https://arxiv.org/abs/1905.09866
2.2 Abstract
“连续空间语言模型最近在各种任务中都表现出色。在本文中,我们研究了由输入层权重隐式学习的词向量空间表征。我们发现这些表征出奇地擅长捕获语言中的句法和语义规律,并且每种关系(规律)都能被特定于关系的向量偏移量来表示。
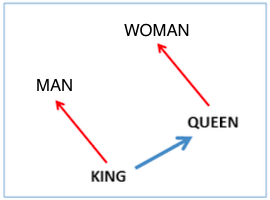
这允许基于单词(向量)之间的偏移量进行面向(词)向量的推理。例如,会自动学习男/女(词向量之间的)关系,并由 “King-Man + Woman” 的词向量计算会产生一个非常接近 “Queen” 的词向量。
我们证明了词向量通过句法类比问题(随本文提供)捕获了句法规律,并且能够正确回答近 40% 的问题。我们通过使用向量偏移量的方法回答 SemEval-2012 Task 2 问题,证明了词向量可以捕获语义规则。值得注意的是,这种方法优于以前最好的系统。”
这个 abstract 说了一件事情,就是词在词嵌入空间中的相对位置关系(词向量差)是可以在一定程度上对应句法(syntactic)、语义(semantic)关系的。
2.3 这篇文章和word2vec的关系
从时间上看,这篇文章发表在 word2vec 之前,因此托老师并没有在这里用到 word2vec 模型。那为什么要把它归到 word2vec 系列里?因为这篇文章的核心并不是词嵌入模型,而是如何评价词嵌入。
它观察词嵌入间的关系,将其联系到句法、语义层面,也为从 word2vec 开始一度被广泛使用的词类比(word analogy)任务做了铺垫。
此外,当我们谈词嵌入时往往重点都在模型,而评价(evaluation)大多时候只是一个证明我的模型比你的好的手段或标准。但其实不少时候,评价本身是有缺陷的,那么多所谓成功的工作都依托于评价之上,如果评价突然有一天被证明有缺陷呢?
以下,我们会通过词类比任务,具体谈谈上段话的含义。
2.4 如何精确找到第四个词?
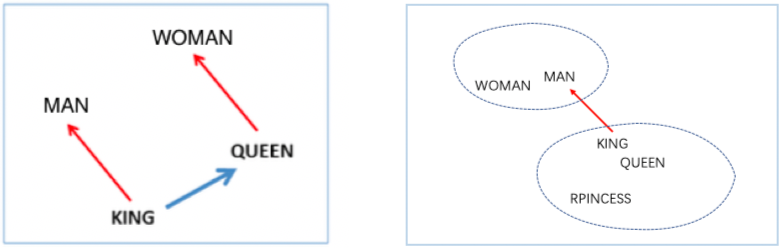
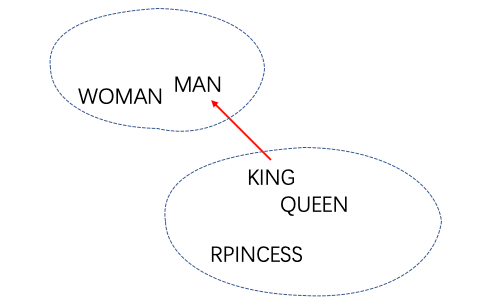
文章中的配图清晰地表明了第四个词的计算方法和这样计算的原因:
先说原因,如左图所示,这三对有性别联系的词组(man,woman),(uncle,aunt),(king,queen),他们的词向量差(vector offsets,蓝线)是非常相似的。右图中代表单复数关系的红线也非常相似。
因此,作者认为词嵌入空间(或词嵌入表征的相对位置)已经蕴含了这种句法或语义信息。那么当要计算 “king is to man as queen is to ?”时,相当于有两组相同关系的词对(king,queen)和(man,?),那么?= queen-king + man(此处都是向量/坐标)就不难理解了。
2.5 第四个词的近似
事实上,想要精确找到第四个词几乎是不可能的,算出来的坐标位置大概率是没有词的。因此作者提出用离该点 cosine similarity 最近的词。到此为止,这几乎就是词类比任务方法的全部了。
2.6 第四个词的限制
在托老师正式提出 word2vec 模型的文章中,他一方面完善了词类比任务的数据,另一方面也明确了第四个词的限制:
we search in the vector space for the word closest to X measured by cosine distance, and use it as the answer to the question(we discard the input question words during this search).
2.7 限制的影响
这不过是个小细节,代码加一行判断的事,它的影响能有多大?答案是,非常大!
试想,如果没有这个约束条件,“king is to man as queen is to ?”算出来的是 man,这就很尴尬了:它会打破大家对词嵌入空间有多么神奇的想象,具体来说,是对脑海中的这张图:
queen-king+man 计算后发现离得最近的点是 man,离得第二近的才是 woman。如果是这样,它还有那么神奇吗?
词嵌入空间有没有可能只是意思相近的词离得近(上图虚线内),queen-king 的结果很小,+man 之后指向位置就在 MAN 附近,因为限制条件,恰好选到离 MAN 比较近的词,即 WOMAN。
换句话说,词嵌入可以保证很好的词和词之间的相似关系,但是涉及到 3 个词、4 个词、更多涉及空间分布(句法、语义关系)时,没有那么“神奇”。
2.8 那么,真实情况是?
真实情况是,很大一部分词类比任务的“神奇“结果多亏了上面提到的限制条件。
有趣的是,认真研究这一限制条件的文章最早出现在 2019 年,其正式发表在 Computationla Linguistics 其实是最近几个月的事情。
论文标题: Fair is Better than Sensational: Man is to Doctor as Woman is to Doctor
论文链接: https://arxiv.org/abs/1905.09866
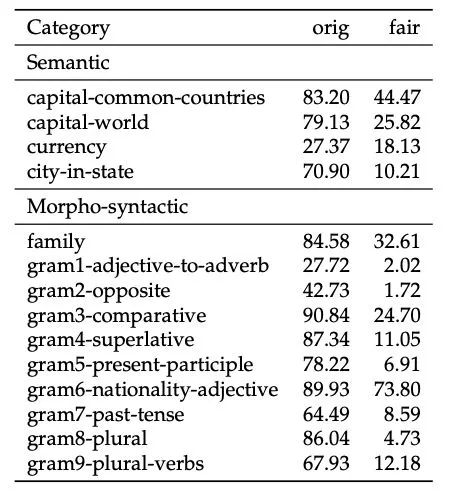
这篇文章第一版里有个 table 非常有趣(不知道为什么第二版没有了):
作者对比了有限制条件(原版,orig)和取消限制条件(fair)的词类比任务结果,可以看到貌似真正神奇的是限制条件,而不是词嵌入的 offset。
2.9 当我们谈词嵌入时我们谈些什么?
上面提到的文章非常有趣,强烈建议每一位对词嵌入感兴趣的人认真读一读。文章的重点其实是通过对这一限制条件的研究,批判现在很多关于 bias 的文章其实是站不住脚的,一些文章研究的例子其实是精心挑选的,有点为了研究而研究的意思。
当然,出于政治正确,作者不可能说他针对的是所有关于词嵌入 bias 的研究,而是其中一部分,提出这些也是为了更好、更公正的关于 bias 的研究。作者的意思我都明白,但我觉得其实是针对每一位做词嵌入研究的人的,并且这是一件好事情。
我个人觉得是被“针对”到了。因为曾经花过很多时间研究 word2vec 模型,努力改进,以求在词类比和其它任务上获得一点点改进,然后终于可以在论文 abstract 部分“理直气壮”地写上我们的模型超越了 SOTA。
我们有时也会分析带来改进的原因、甚至举出一些具体的例子,说“看吧,以前的模型这里是错的,我的新模型这里是对的”,但是很多时候对结果改进的分析本身是一种假设。如果到头来,评价体系本身是有缺陷的,那是不是很多在此评价体系上带来改进的相关研究的价值也要大打折扣?
不要迷信结果(我甚至还没来得及提 statistical significance),我们需要更多关于评价体系本身的研究和反思。
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读 ,也可以是学习心得 或技术干货 。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品 ,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱: hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」 也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」 订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」 ,小助手将把你带入 PaperWeekly 的交流群里。