让机器“答问如流”:从视觉到语言|VALSE2018之四
编者按:
《书李世南所画秋景》
--苏轼
“野水参差落涨痕,疏林欹倒出霜根。
扁舟一棹归何处?家在江南黄叶村。”
宋代诗人张舜民在《跋百之诗画》中,曾经写道:“画是无形诗,诗是无形画“。这句诗展现了古代语言与视觉之间的融合,而在如今的人工智能领域,这句诗亦可用来表现,自然语言理解与计算机视觉两个领域的交融。
因此,当我们来读苏轼的《书李世南所画秋景》,第一句的“野水参差落涨痕,疏林欹倒出霜根”,是从秋景中提取信息来生成自然语言描述的过程,即Image Captioning,而第二句的“扁舟一棹归何处?家在江南黄叶村”,则是从视觉内容结合“黄叶村”这一背景信息来生成问答的过程,即融合了external knowledge的Visual Questioning Answering。
在从视觉到语言这一问题上,人类通过对周围世界不间断的感知和学习,能达到如诗中融会贯通的效果。然而相比而言,机器却只能达到人类三四岁小朋友的水平,其间还有很大的差距需要我们科研人员来填补。
今天,来自澳大利亚阿德莱德大学的沈春华教授,将为大家介绍,从视觉到语言,如何利用深度学习来填补机器与人之间的落差。
文末提供文中提到参考文献、代码及数据库的下载链接。

本次报告给大家分享一下过去差不多两年的时间里我们做的Natural Language Processing,NLP和Computer vision,CV的交叉的工作,主要是Image Captioning和Visual Question Answering。

我下面介绍的工作主要是之前组里两个非常优秀的博士后做的:王鹏,现在是西北工业大学的教授;以及吴琦,现在是我们阿德莱德大学的讲师。

所谓的Vision and Language,是一个相对比较新的领域,上图左边是一些传统计算机视觉的任务。比如给你一张图片可以做Image Classification,Object Detection,Segmentation等等。基本上都是给你一张图片,用算法输出单个或者多个标签。而纯自然语言处理领域的任务,则需要对自然语言进行相关的处理以及理解,常见的任务有机器翻译,语言生成等等。而这里很有意思的一点是,如果给一个三四岁小孩看一张照片,他/她会用一个简单的自然语言的句子去描述这张照片,也就是说我们人类天生的会将视觉与语言系统组合起来使用从研究的角度来讲,计算机视觉试图解决的任务也是越做越复杂. 基于这样的观察, 我们希望做一个系统或者算法,能够给一张图片生成一个或者几个自然语言句子的描述,这个就是所谓的image captioning,video captioning。
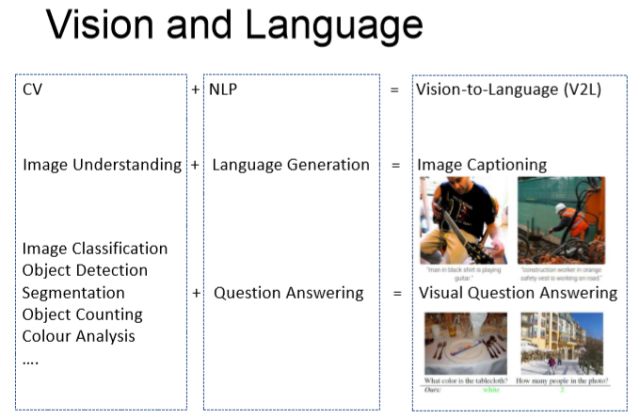

再往前走一步,就是里面有一个人机问答,或者是Visual Question Answering ,给你一张图片,我问跟这个图片相关的问题,我希望有一个算法或者系统能够正确回答这个问题,这就是Visual Question Answering。Vision和Language目前2个比较主流的问题,一个是Captioning,一个就是Visual Question Answering。

这需要两方面的技术: 一是图像理解image understanding,给你一个图片,你得有一个算法能够理解这个图片是什么。
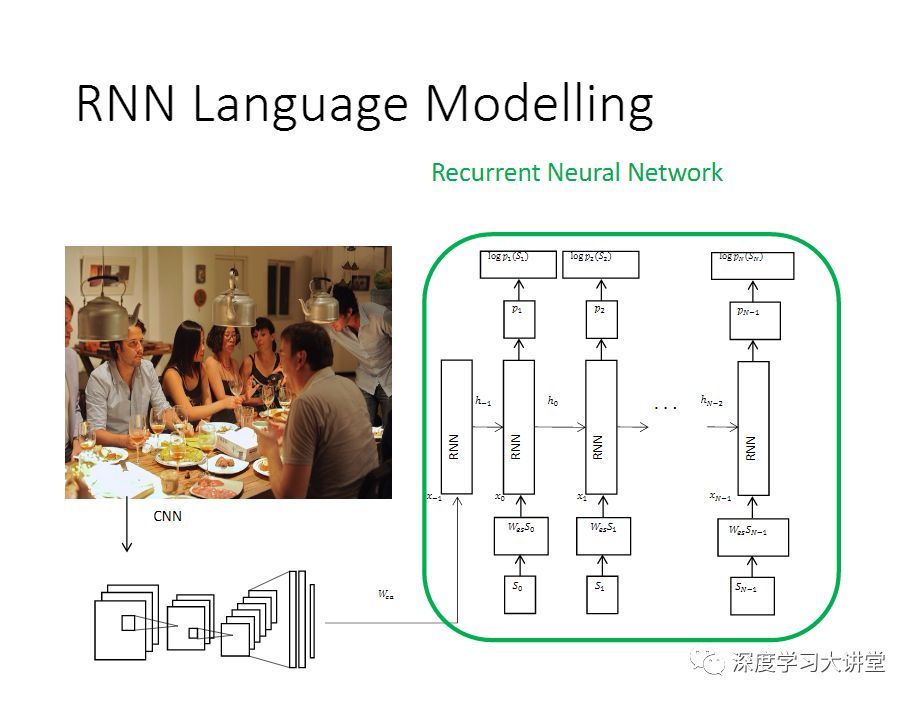
同时还得理解自然语言,得有一个Language Modelling,能够生成合乎语法规则的英文句子的描述。计算机视觉再往前做,就不再满足预测单个或者多个的标签。
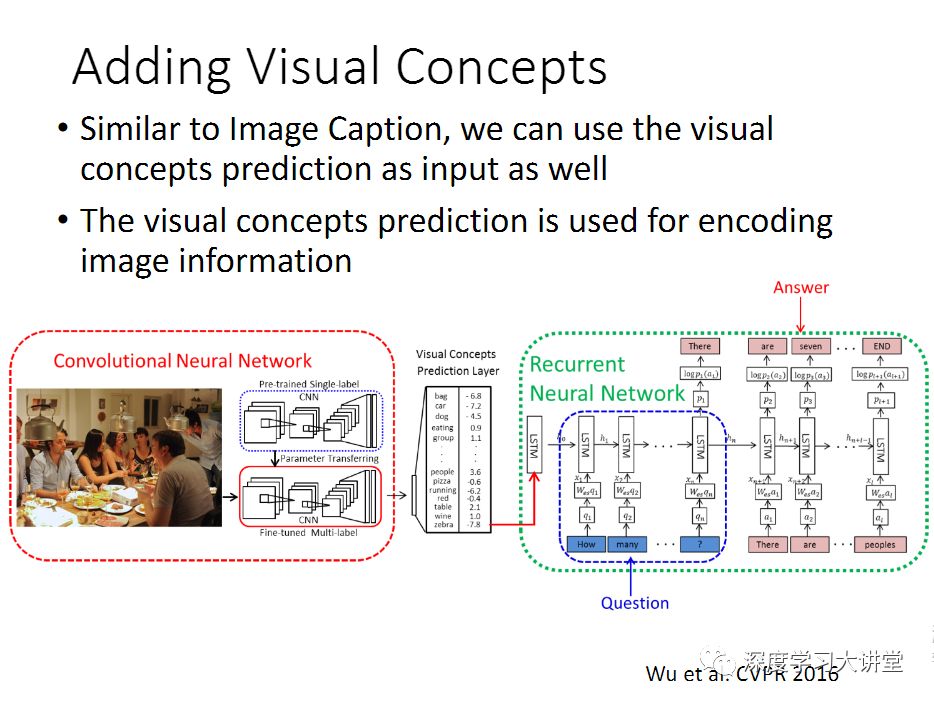
这里给大家看一下几个image captioning的例子,这是我们2016年做的工作,发表在CVPR上。下面大概提一下怎么做的,最传统的做法,里面嵌入了两方面的内容:一个是Image processing,需要一个卷积神经网络,然后来提卷积或者全连接层的图像特征;另外一个是用一个递归神经网络,来得到语言模型,从而生成自然语言的描述,这就是做Image captioning。
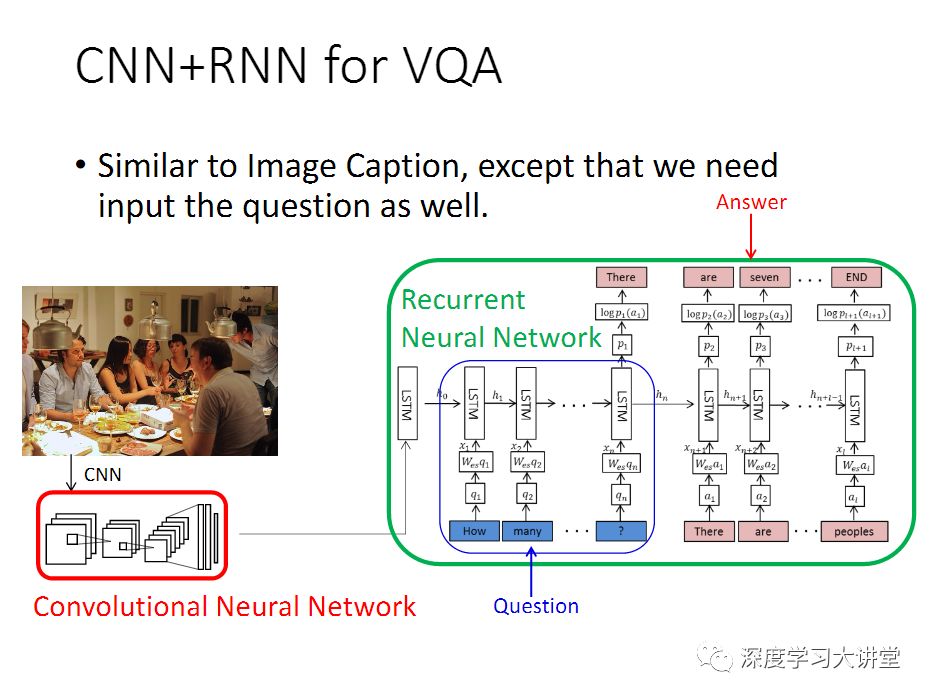
如果做VQA的话,跟image captioning差不多,唯一的差别是你的输入会多一个自然语言的输入,所以输入会有两部分,一部分是输入这个图片,同时需要输入这个自然语言的问题,输出就是RNN去生成回答,这还是一个编码和解码(encoder-decoder)的过程。
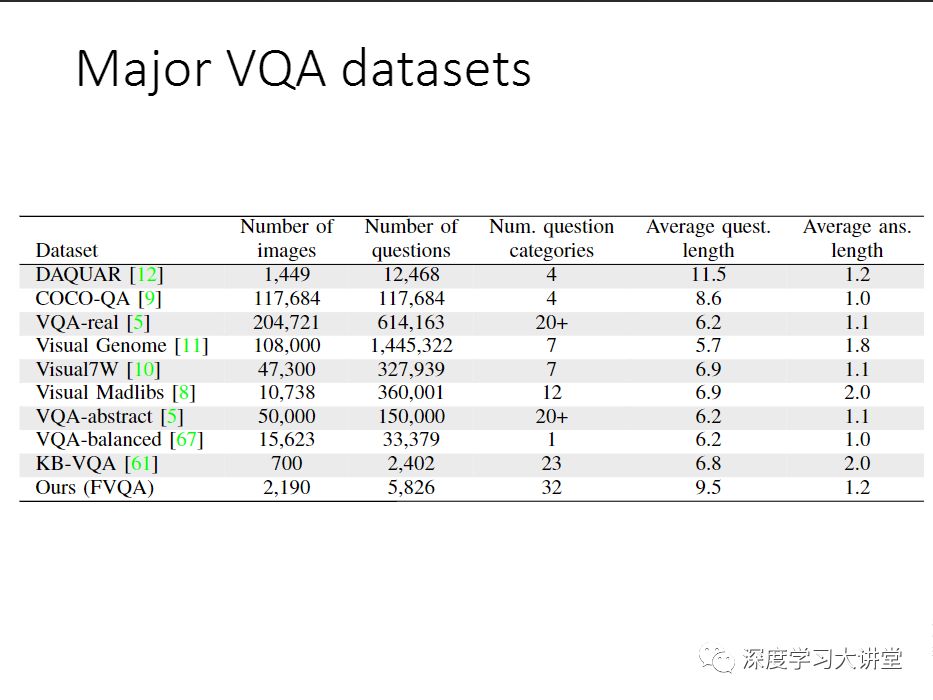
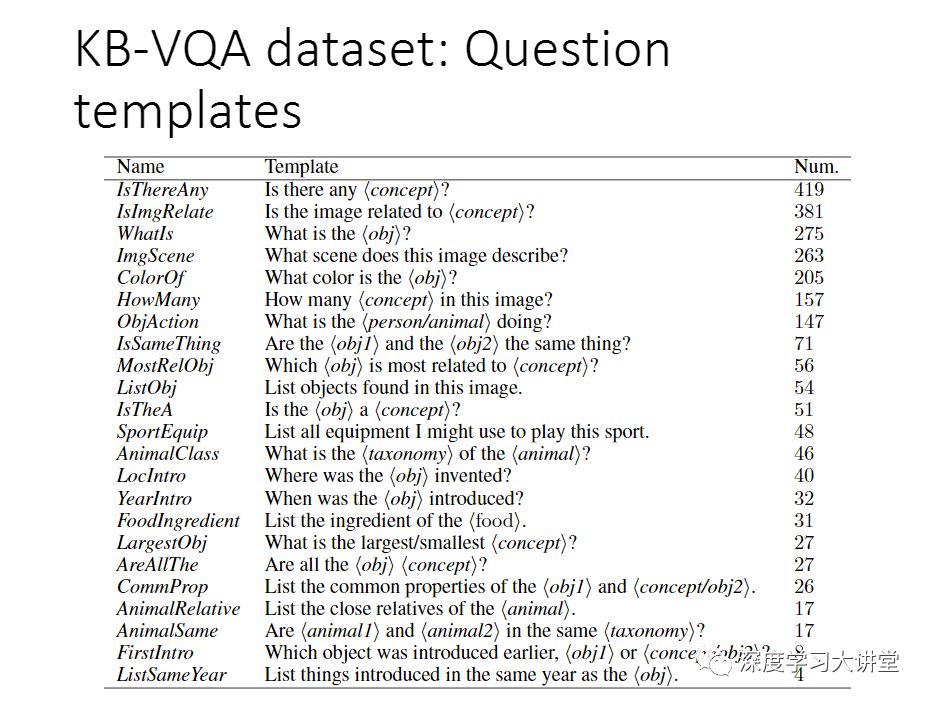
我刚刚提到了我们做了新的数据集,为什么要做这个数据集呢?这里列出来一些主流的VQA数据集。下面我会具体讲一下我们做了什么事情,这个数据集已经发布了。
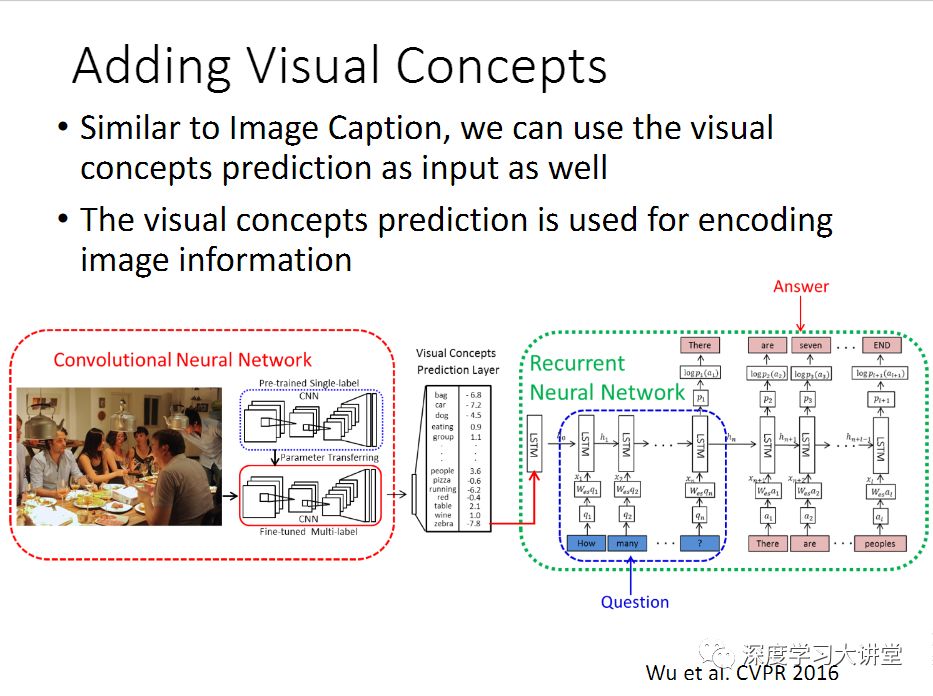
我们最早两年前开始做VQA的时候,当时有一个很简单的想法。我们观察到之前做的大部分的工作,都是给你一个图片,用一个神经网络来提特征,提完特征之后这个图片就扔掉了。那么这里面有一个我们觉得不是很合理的地方。首先一点,几乎所有人都是用ImageNet数据集,训练模型,这是一个分类模型的数据集。但是这里我们的任务是做captioning或者VQA,不是做分类。 所以我们当时做了一个事情,去提一系列表示图片内容的标签或属性。给一张图片,可以先用一个预处理的算法---我们用的是一个深度学习的多标签预测网络---来提取跟图片相关的标签或属性。然后可以把这个作为LSTM的输入,来做captioning,或者Question Answering,得到更好的结果。
提到VQA,其实如果要真正彻底解决VQA,一定要解决QA,在自然语言处理(NLP)里面,所有的研究问题,最终都可以转成QA的问题。如果把QA解决了, 其实也就是解决了自然语言处理,大家知道NLP远远没有解决,还有很多研究的问题。那么Question Answering问题,和其他传统的计算机视觉问题相比是一个非常大的挑战。 要正确回答这个问题,你可能要依赖很多的知识(knowledge), 这个知识不一定在图像里面。

这个例子是我2016年我们CVPR的另外一个工作。把图像属性提出来后,我们可以用Internal textual representation自动生成一个句子来描述这个图片。但是如果问一个问题,Why do they have umbrellas? 为什么他们会打伞?这个问题答案本身不在这个图像里,只理解这个图像是不能回答这个问题的。正确答案是shade,遮阳。这里需要External knowledge,需要一些常识:“遮阳伞,在沙滩上就是为了遮挡太阳的”。怎样找到相关的External knowledge来正确的回答这个问题,这个是需要解决的研究问题。

这里再给几个更直接的例子。第一个图片,如果给你这样一个图片,问一个问题,How many dogs are in this image?用一般的传统的算法很容易能够回答出来,这里有一条狗,如果你问How many cats are in this image?,这个回答也是很容易就得到。但是如果我问一个How many mammals are in this image?,这里面有猫有狗还有鸟,有多少个哺乳动物? 你得了解:狗和猫是哺乳动物,但是鸟不是。这样一个常识(common knowledge)不在图像里。算法怎么才能找到这个相关知识来正确的回答它?这是要解决的一个研究问题。
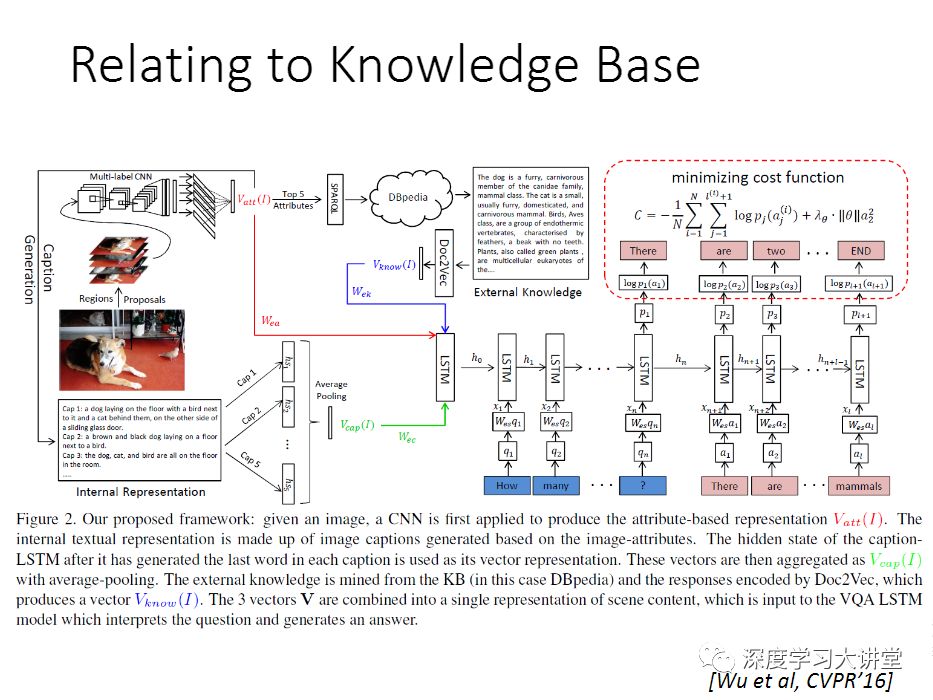
在CVPR 2016的论文里,我们做了一个工作,怎么样把相关的知识找出来,主要使用的External knowledge是维基百科。维基百科拥有几十万的英文文章. 基本是思想是给你一张图片,可以根据图像相关的属性得到标签,然后再用SPARQL(SPARQL是一个数据库搜索的语言),去搜DBpedia,DBpedia是Google做的基于维基百科的结构化数据库。得到之后,我们再去找到相关的维基百科里面的英文文章,得到相关的描述。最后要让文本参与计算,我们用了Doc2vec,把它转换成一个向量,然后再输入给LSTM,然后再做神经网络的训练。用这样的方法把相关知识利用起来。这可能是当时第一个把External knowledge利用起来,应用在VQA领域的工作. 这个工作只是往前走了一小步,还远远不够。

局限性
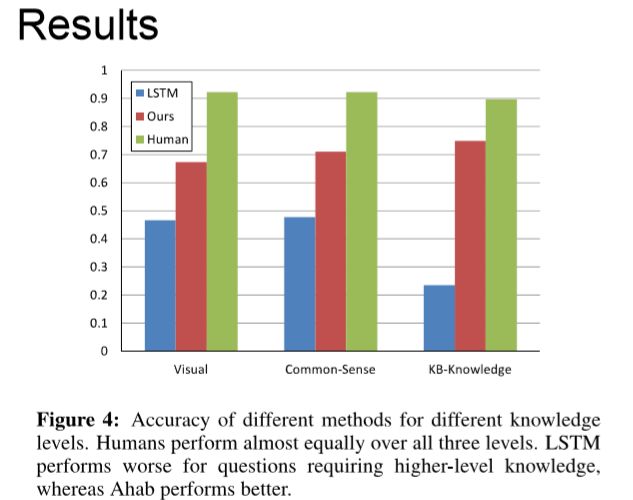
首先一点,其实我刚才也提到了,现在做VQA, 或者captioning,通常都是只用了CNN的特征,CNN的特征大部分情况下是直接用的ImageNet训练好的模型. 有工作做了对比,不对CNN特征做 End to end training的话效果反而会好一些。但是不管做 End to end training也好,不做也好,都是只用了CNN的特征。但是VQA这个问题本身是给你一张图片,有可能问你这里边有多少个目标,多少个物体,多少个狗,或者这个猫的颜色或者这个猫在干什么。用户可能问的问题是五花八门的。你如果要正确回答他提出的任意的问题,需要解决多个计算机的任务。有可能是问你统计有多少目标,你要数数。有可能是问你里面的动作是什么,那就是动作识别。第二个问题是之前的这些方法---其实这也是Deep Learning受到批判的一方面---现在都是训练一个编码和解码的模型,这是个黑盒,反正就是输入数据,输出数据. 我们不知道为什么会生成这样的回答,没有解释。所做 End to end training模型就是一个 图片加上文本,然后到答案的highly nonlinear的mapping的过程。mapping函数就是你的递归神经网络. 但是在很多应用上,我们希望知道,为什么会得出这样的答案,希望知道背后的原因。这个其实是跟研究深度学习可解释性是息息相关的。我们的目标是,有没有可能在VQA这个问题上,把这两个局限性给部分的解决了。
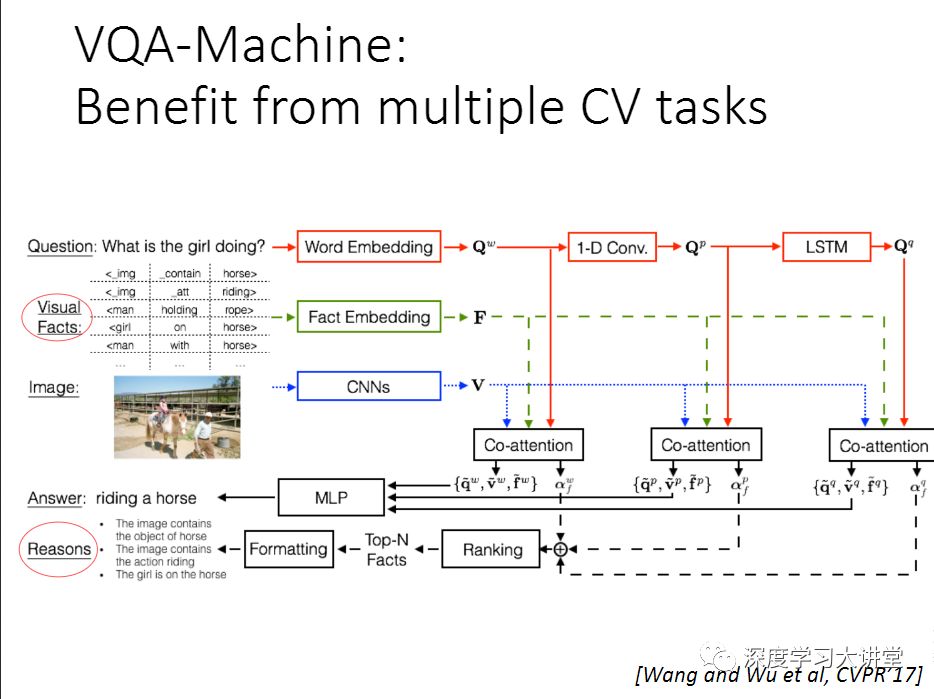
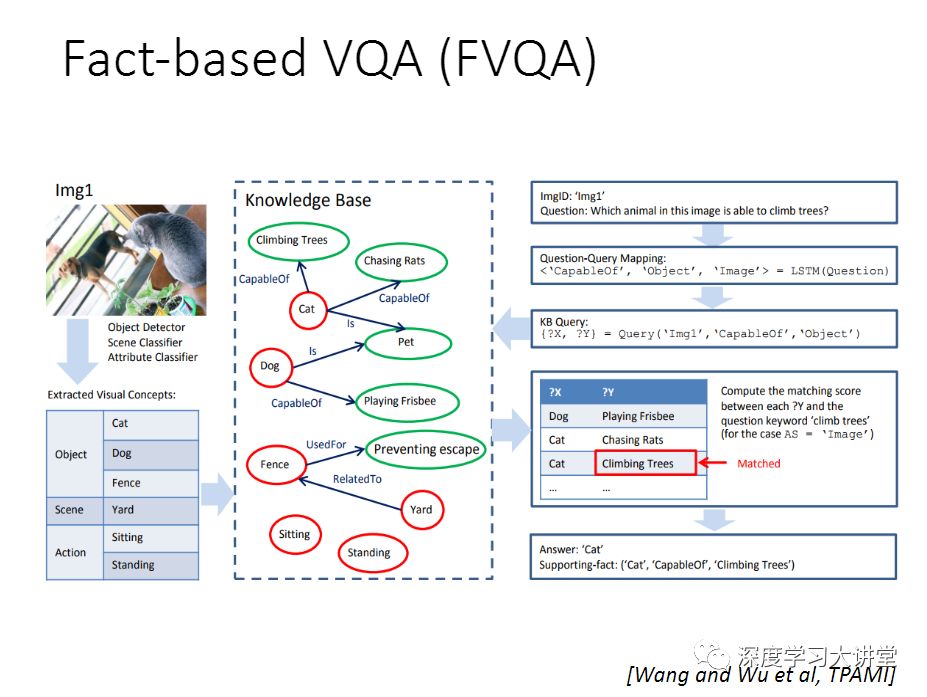
去年的CVPR我们做了一个工作,希望在这两个局限性上往前走一步,所以我们做了一个VQA-machine,基本的思想很简单。在CV这个领域里,其实有很多off the shelf的方法,可以做语义分割,可以做目标检测等等。其实我们可以做这样一个事情,给你一张图片,把现有的算法跑一遍. 然后我们希望有一个算法能够有一个机制很好的利用这些结果,以便正确回答问题。我们把这些计算机视觉算法的输出结果叫做Visual facts,以triplets的方式呈现。
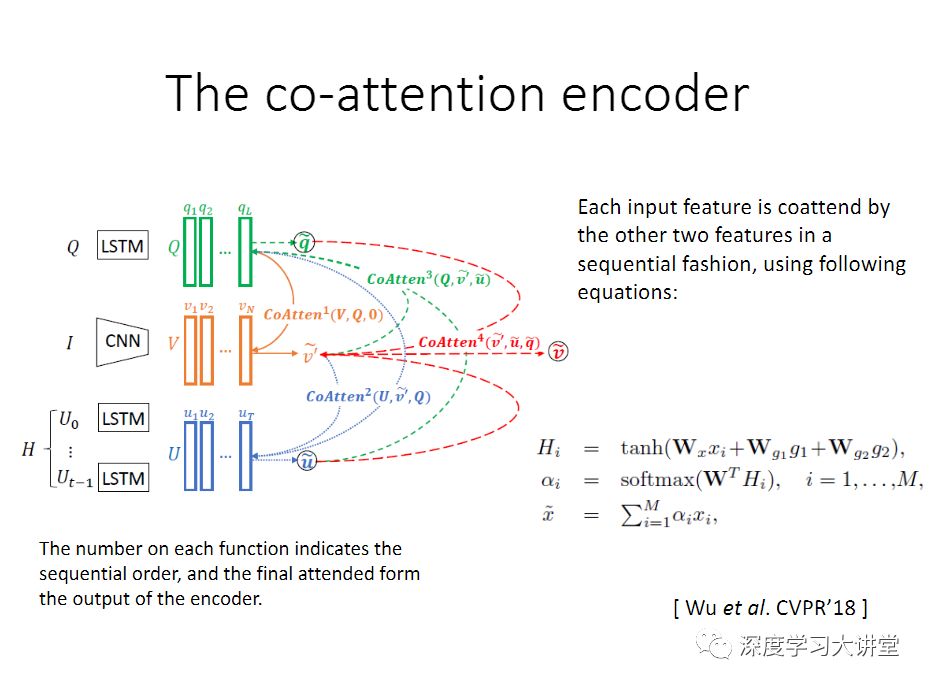
如果要正确的利用这样的结果,这里有几个研究问题要解决,其中一个是,首先这些off the shelf的算法的结果不一定百分之百是正确的,有可能是错的。怎么样把错的结果给过滤掉?第二个问题是因为我们产生这些结果的时候,我们并不知道用户要问的问题是什么. 我们需要在给出一个问题的时候,去挑选那些相关的facts,把那些不相关的仍掉,这里面得有一个机制,去掉错的或者噪声,来选择正确的facts来回答我的问题。在去年的CVPR论文里,我们提出一个Co-attention Model来做这个事情。

下面讲一下facts representation。用一些已经有的算法去跑,得到一些所谓的事实,因为这个结果不一定完全是正确的。我们做了这样五种可能的关系。这些事实用triplet来表示它.以这个_img,_scene,img_scn作为例子。给你这样一张图片,要你去看看图片中有什么动物,这样一个事件,这种可以用场景识别的方法来得到。 场景识别有很多比较好的算法。
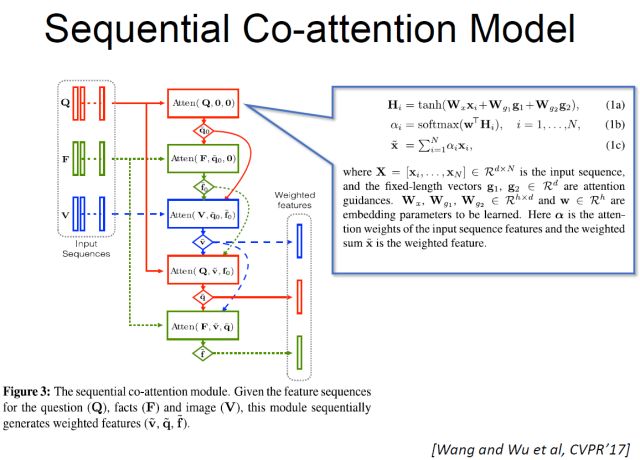
得到这些facts之后,我们需要有一个机制(我们提出了Co-attention model)来回答我的问题。这个Co-attention model有个三个输入。如果说没有中间的Fact(F),这种做法就是你有一个图像,你有一个问题,就是标准的编码-解码的模型。在我们这里有三个输入,Facts是一系列的triplet。我们用这样一个Co-attention的模型对应每个fact来学一个权重,0表示这个F是没用的,1表示这个F是应该利用起来回答我这个问题。
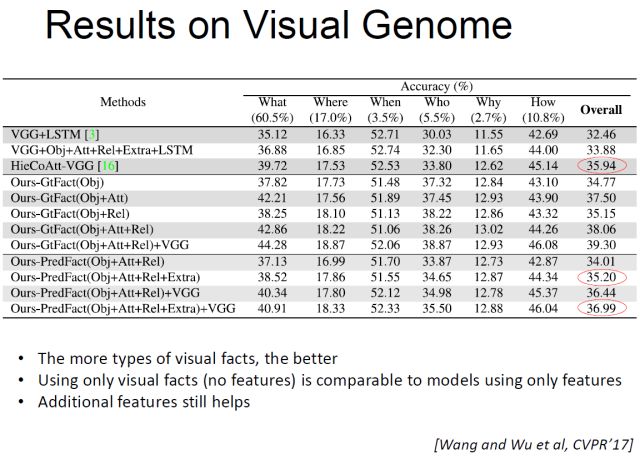
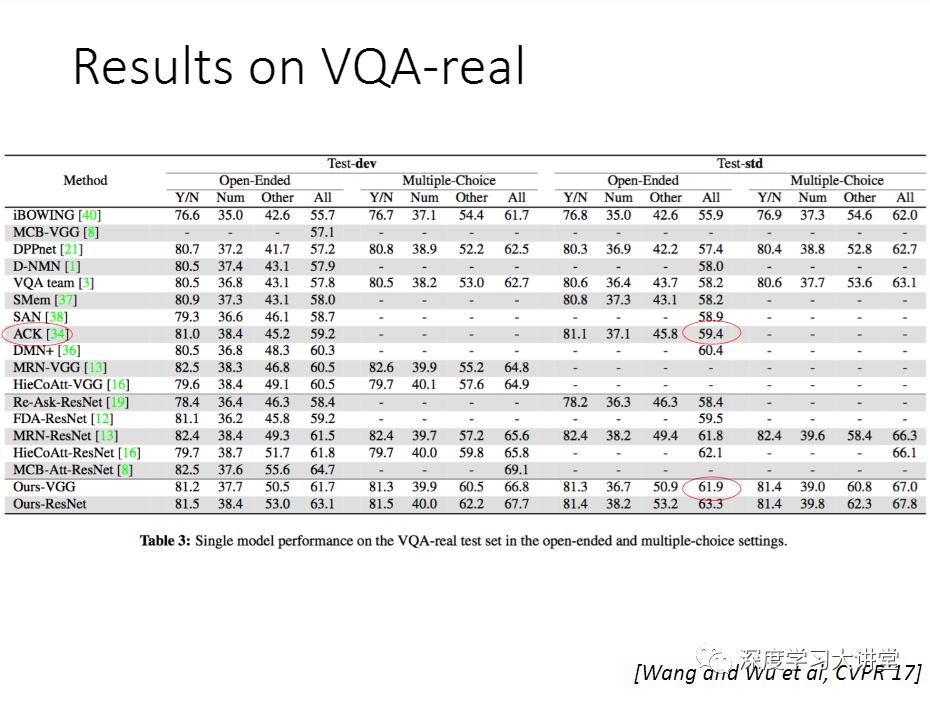
这些是我们实验结果的展示。

刚才说了,我们想解决的局限,原来的编码和解码这种模型,其实它是一个黑匣子,不知道它为什么会产生这样一个回答。在这里,因为我们有Co-attention model,每一个F上面都有一个权重,0到1之间的数字,我们可以排序一下,分数越高,表示你的LSTM生成回答的时候,它用到F.1就是完全用到. 这个分数就表示重要程度。举个例子给你这样的图片,问一个问题“Who is leading the horse?”,回答用到的facts有“The man is holding the rope”,“ The man is with the horse”,“ The girl is on the horse”.最后产生答案man,这个答案是从R1,R2,R3推导出来,可以给出一些解释。

这里还有几个例子。 中间这个例子比较有意思,给你这样一个图片,How is the weather outside?看不到外面在下雨,正确的回答是raining,正在下雨。因为可以看到有人在打伞,所以猜在下雨. 用到的第一个Fact是The woman is with the umbrella,有人在打伞。其他的facts有This image contains the attribute of rain。This image contains the object of umbrella。

CNN+RNN
这些工作做完之后,我们在利用External knowledge上面,其实已经往前走了几步了,为了更好的做VQA这个问题,其实它还是有一些局限性的。第一个是可扩展性,它不够好,因为所有的知识都是从Questions and answers这样的问题和回答里面学出来的。 knowledge可以是非常大的。如果说要有一个编码解码这样的模型,一个递归神经网络,把所有的人类所知道的这些知识全部包含进去,全部学出来的话,可能是非常难的问题。
还有就是推导过程,目前我们只能rank一下它用到的Facts的重要性,它其实没有一个相关性,怎么显性的推理过程是没有的。第一个可扩展性非常重要,我们有没有可能把我们知道的那些knowledge base全部用上,来回答你的这个问题,把它用到这个VQA上面。其实这个在NLP里面有很多相关的工作,不过做视觉的很少关注到,这个肯定是有可能的,也需要把knowledge base这些技术跟视觉技术结合起来。

第二个,我们希望做一些推理的工作。去年我们做了一个工作,在我刚才介绍的这些工作基础上又做了一些改进。我们叫做Ahab。这是一个传说当中的人物,这个方法本身跟之前的编码解码这样的模型是完全不一样的,我们不再做question到answer的mapping,我们为了把knowledge base利用起来,做了从图片加问题,到一个knowledge base query的mapping。
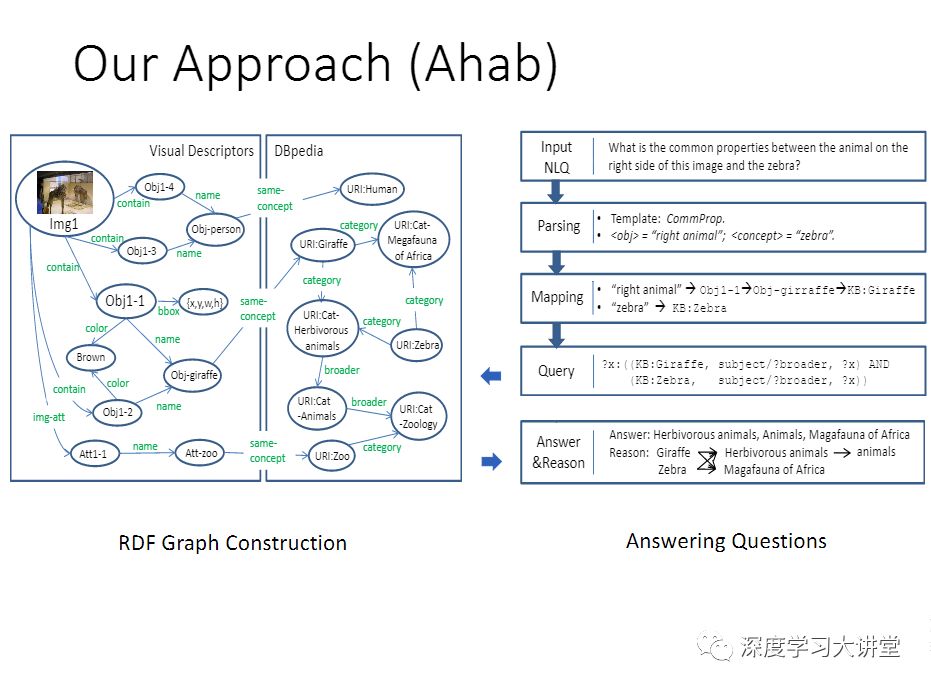
第一步,给你一个图片,我们去产生concept,这个其实是图片理解的过程,得到了图像信息之后,我们可以跟DBpedia对应起来。第二个模块其实是要理解输入的问题,因为你有个自然语言,NLP描述了一个问题,我们对这个问题做删选,然后做一个映射,得到这个映射之后,就得到了Query,去搜索这个knowledge base。



这里面有几个例子,为了去生成这个query,我们只能回答有限类型的问题。例如,像第一个,Is the image ...“这里面有没有”。

刚才说到的VQA,因为回答的问题有限,所以在这个基础上又更进了一步,我们希望把生成query,改用学习的方法得到,这样的话可以不局限于只能回答有限的问题。

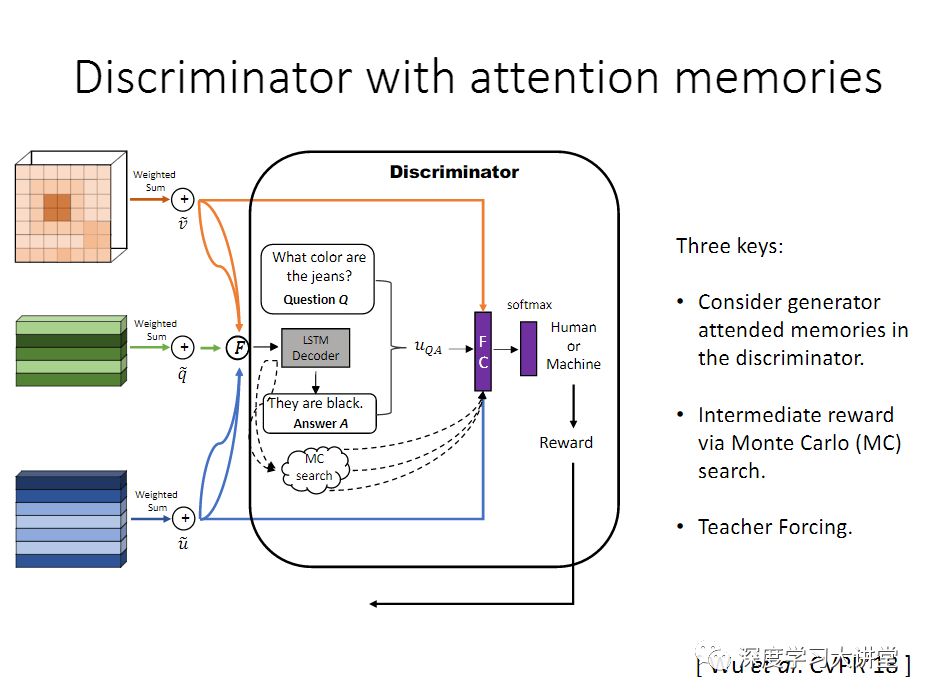
最后提一下今年做的工作,是今年CVPR的一个oral paper,这个工作的背景是我们把GAN用到VQA上。让这个算法生成更像人说的这些自然语言,这里给大家看几个例子,这个人说的话,大概会比较长,会有更多的信息在里面,如果用机器来生成非常简短。
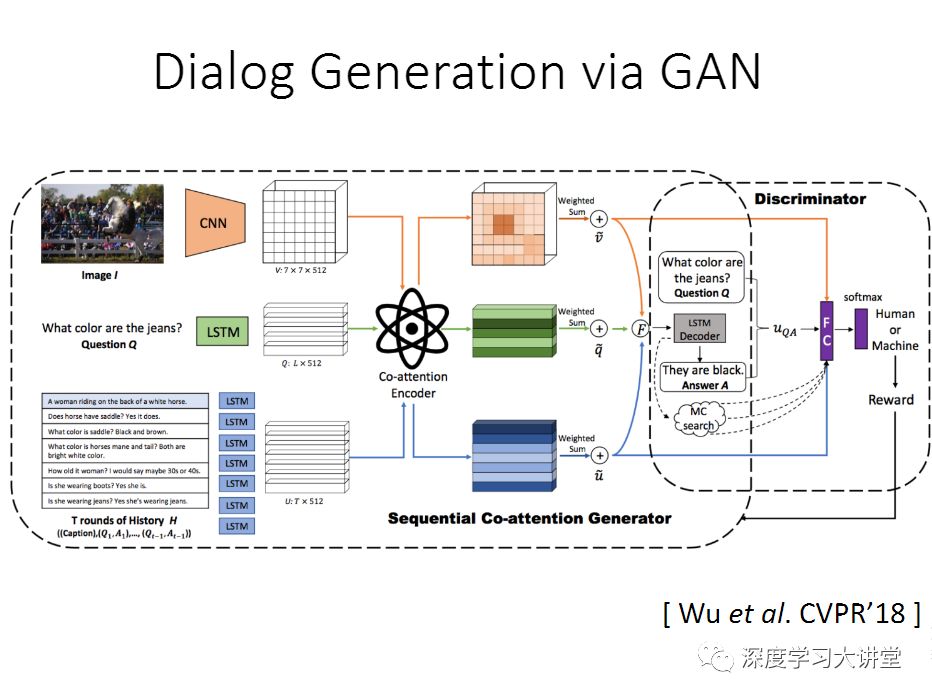
这个是我们提的框架,这里面加了鉴别器,这个鉴别器的任务就是来区分这是人说的话还是机器产生的,然后得到这个分数之后,再来指导这个generator,让它生成更像人说的话,这里面也会用到一个Co-attention model。在训练的时候,我们会固定一个训练好的判别器模型,把它当作一个reward function. 然后使用policy gradient,这样在训练生成器的时候,我们可以不提供ground truth,只通过sampling的方式,然后将sampling好的结果送入判别器,再通过reward计算policy gradient,来调节生成器,期望得到更好的sampling。

文中提到参考文献下载链接:
https://pan.baidu.com/s/1hH9Z-WOXfIEpjQY_jIPYlw 密码: niw2
代码及数据集开放链接为:
DAQUAR数据集:
https://www.mpi-inf.mpg.de/departments/computer-vision-and-multimodal-computing/research/vision-and-language/visual-turing-challenge/
COCO-QA数据集:
http://www.cs.toronto.edu/~mren/imageqa/data/cocoqa/
VQA数据集:
http://www.visualqa.org/download.html
Visual Genome数据集:
https://visualgenome.org/api/v0/api_home.html
FVQA 数据集:
https://www.dropbox.com/s/iyz6l7jhbt6jb7q/new_dataset_release.zip?dl=0
CO-attention code:
https://www.dropbox.com/s/siofu0gj6ocoirw/HieCoAttenVQA_v2_clean.zip?dl=0
Attributes captioning/VQA code:
https://www.dropbox.com/s/ur15xi828k2j4a9/ACK_Code.zip?dl=0

主编:袁基睿 编辑:程一
整理:周文、杨茹茵、高科、高黎明
--end--
该文章属于“深度学习大讲堂”原创,如需要转载,请联系 Emily_0167。
作者信息:
作者简介:

沈春华博士, 现任澳大利亚阿德莱德大学计算机科学学院教授(Full Professor),以及澳大利亚机器学习研究院(Australian Institute for Machine Learning)科研主任。 他曾在南京大学(本科及硕士),澳大利亚国立大学(硕士)学习,并在阿德莱德大学获得计算机视觉方向的博士学位。 2012年被澳大利亚研究理事会(Australian Research Council)授予Future Fellowship。目前主要从事统计机器学习以及计算机视觉领域的研究工作。
往期精彩回顾



欢迎关注我们!
深度学习大讲堂是由中科视拓运营的高质量原创内容平台,邀请学术界、工业界一线专家撰稿,致力于推送人工智能与深度学习最新技术、产品和活动信息!
中科视拓(SeetaTech)将秉持“开源开放共发展”的合作思路,为企业客户提供人脸识别、计算机视觉与机器学习领域“企业研究院式”的技术、人才和知识服务,帮助企业在人工智能时代获得可自主迭代和自我学习的人工智能研发和创新能力。
中科视拓目前正在招聘: 人脸识别算法研究员,深度学习算法工程师,GPU研发工程师, C++研发工程师,Python研发工程师,嵌入式视觉研发工程师,运营经理。有兴趣可以发邮件至:hr@seetatech.com,想了解更多可以访问,www.seetatech.com


中科视拓

深度学习大讲堂
点击阅读原文打开中科视拓官方网站




