数据科学、机器学习IDE概览
编者按:semanti.ca整理的数据科学、机器学习IDE概览,涵盖R、Python、Scala、Julia.

IDE提供的丰富特性对软件开发极为有用,大大提高了程序员的生活质量。这一点同样适用于数据科学家。然而,因为数据科学家除了可以选择传统的IDE,还可以选择Jupyter notebook这样在浏览器中运行的新工具。因此,数据科学家——特别是刚入门数据科学的新手——可能会困惑该使用哪个开发环境。
本文我们将根据数据科学家最常使用的四种编程语言(R、Python、Scala、Julia),推荐相应的IDE。
我们将根据semanti.ca的数据科学家和机器学习工程师的使用情况,排序每种语言推荐的IDE。
Python
PyCharm
PyCharm是JetBrains出品的跨平台的Python IDE。
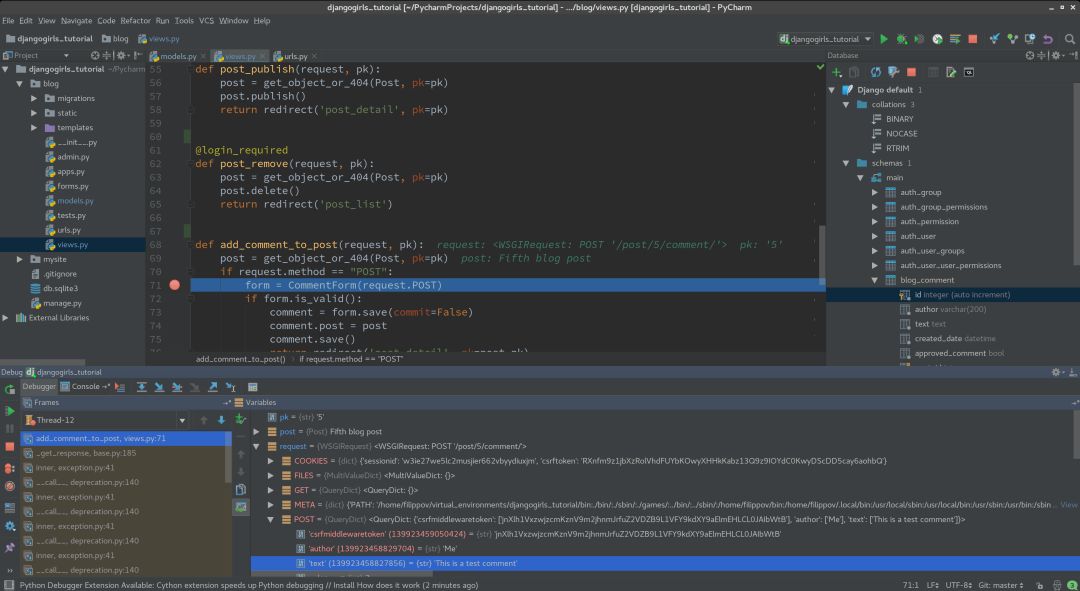
PyCharm为Python提供了一流的支持,包括代码补全、错误检测、在线代码修正。智能搜索可以跳转至任意类、文件、符号,甚至是IDE行动或工具窗口。一次点击即可切换声明、超方法、测试、用法、实现,等等。
PyCharm包括很多工具,集成的调试器和测试运行器,性能调试工具,内置终端,集成主要版本控制系统(包括Git、SVN、Mercurial),远程开发(远程解释器),集成ssh终端,集成Docker和Vagrant。
PyCharm集成了Jupyter Notebook,具备一个交互Python控制台,并支持Anaconda以及多种科学计算包,包括Matplotlib和NumPy。
PyCharm的暗色主题效果不错,对许多semanti.ca的数据科学家和开发者而言,这是一项巨大的优势。
https://www.jetbrains.com/pycharm/
Spyder
Spyder是主要为科学家、工程师、数据分析师设计的强大科学环境。这一全面的开发工具提供了高级的编辑、分析、调试、性能调试功能,以及数据探索、交互执行、深度检查、可视化功能。Spyder可以通过插件和API进一步扩展功能。
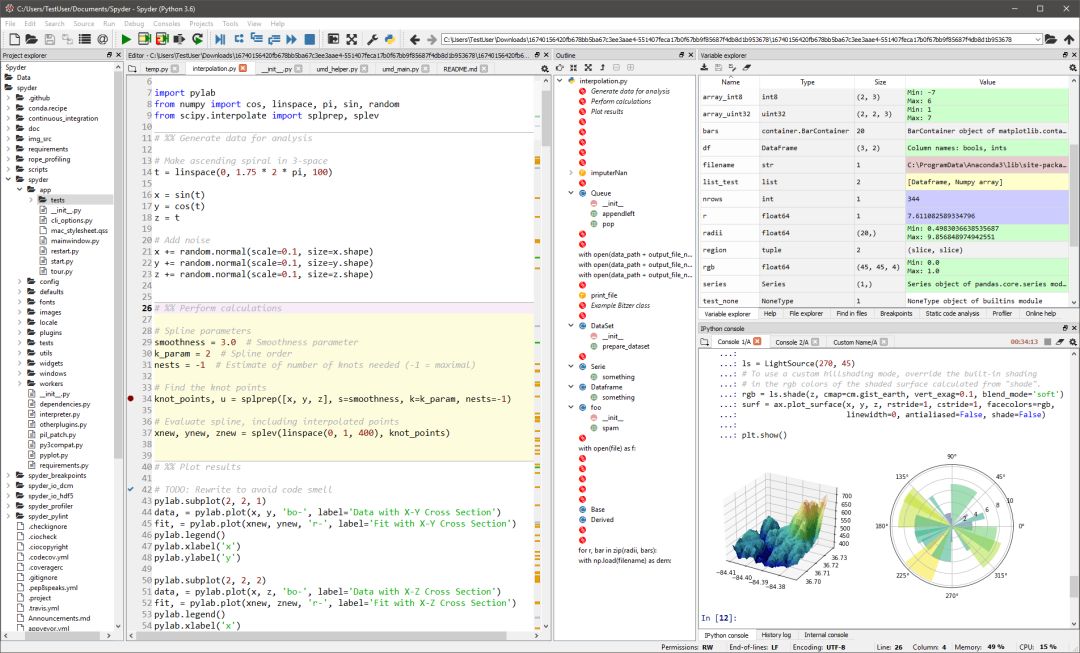
Spyder的多语言编辑器具有函数/类浏览器,代码分析工具,自动代码补全,横向/纵向分割,跳转到定义等功能。
Spider自身也是用Python编写的。
https://www.spyder-ide.org/
R
RStudio
RStudio是R下特性最丰富的IDE。它既有供桌面使用的开源版本和商业版本(Windows、Mac、Linux),又可以在浏览器中使用(基于运行RStudio Server或RStudio Server Pro的Linux服务器)。
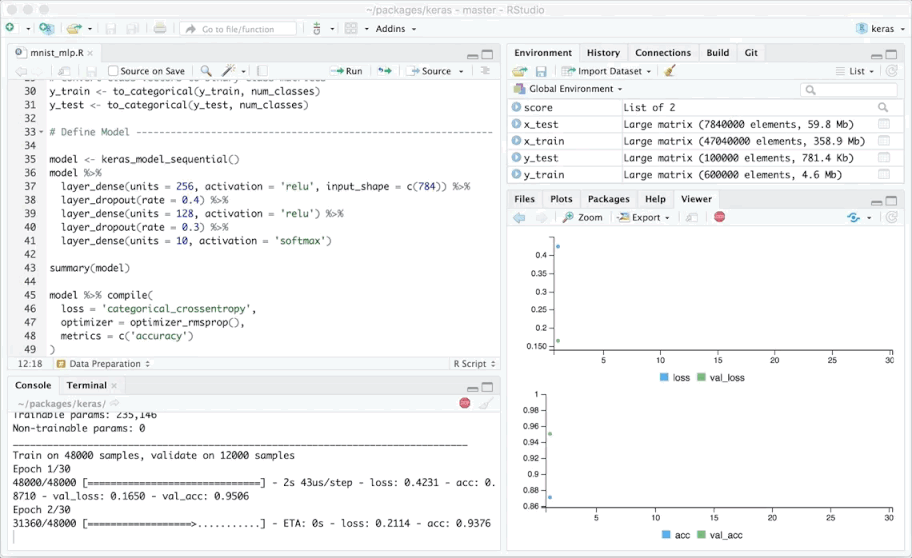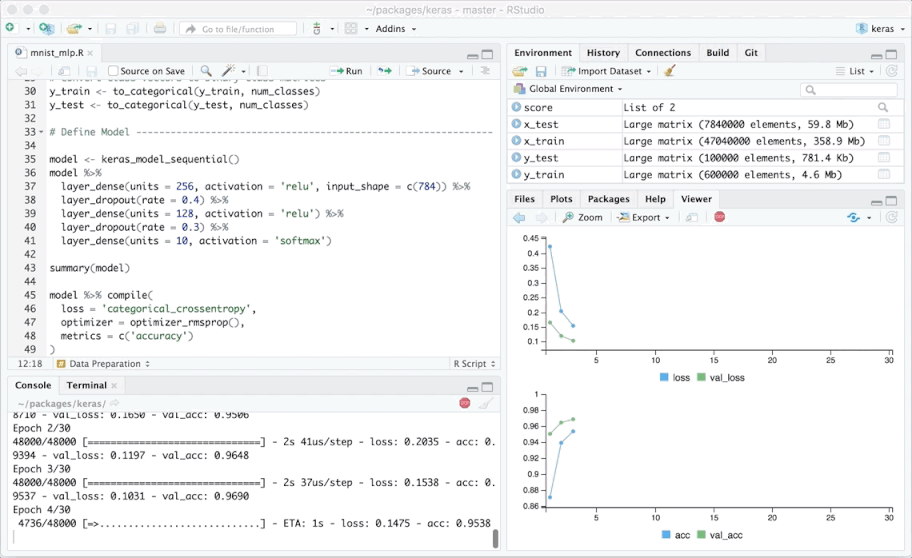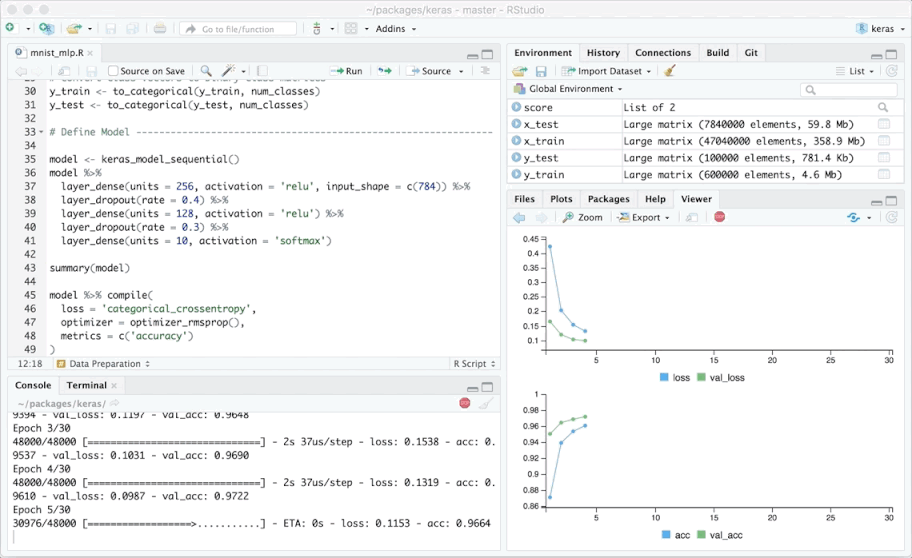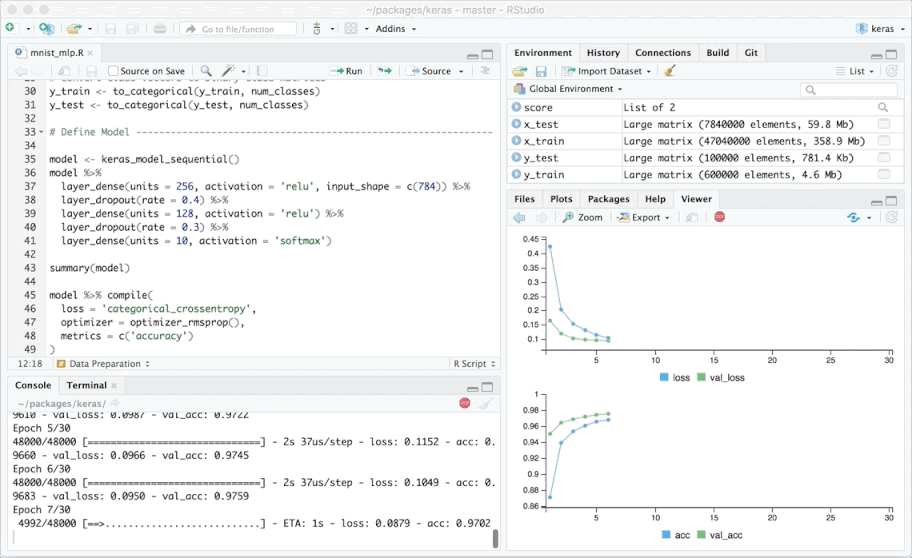
RStudio提供代码高亮、代码补全、智能缩进等功能。在源代码编辑器中可以直接执行R代码。开发者可以迅速地跳转到函数定义,阅读帮助和文档,方便地基于项目管理多个工作目录。集成的数据查看器可供查看表格数据,在调试模式下结合逐步执行可以实时检查数据是如何更新的。
RStudio集成了Git和SVN支持,同时支持编写HTML、PDF、Word文档、幻灯片、交互式图形(基于Shiny和ggvis)。
https://www.rstudio.com/
Eclipse的StatET插件
Eclipse是最流行的Java IDE之一。通过安装插件,它可以支持其他编程语言。StatET是一个基于Eclipse的R IDE。它提供了编写R代码和构建R软件包的一组工具,包括集成的R控制台、对象浏览器、包管理起、调试器、数据查看器、R帮助系统,并支持本地和远程安装的多个R版本。可选的Sweave和Wikitext(Markdown和Textile)附加组件提供了带有R代码段的LaTeX/Wikitext文档的源代码编辑器和构建工具。
代码编辑器提供了语法高亮,折叠Roxygen注释、函数定义、其他代码块,自动修正行缩进,输入和粘贴的自动缩进等功能。
内建的调试器可以很方便地管理断点和条件断点。调试器提供了一个清晰的调用栈,可以直接访问选定的变量、源代码和指令指针,当然也支持逐步执行源代码。
StatET还包括一个数据查看器,可供查看向量、矩阵、dataframe,可以快速显示很大的表格。
http://www.walware.de/goto/statet
R Tools for Visual Studio
Visual Studio是.NET、C++最常使用的IDE。R Tools for Visual Studio(RTVS)是一个基于MIT许可发布的自由、开源的Visual Studio扩展。
在Visual Studio下,数据科学家能够以便利的结构组织和管理相关文件,并使用R代码、R文档、R Markdown、SQL请求、保存的过程等的模板。同时提供了包管理器和SQL Server集成。
RTVS可以绑定本地和远程的工作区,这让开发者可以在本地基于较小的数据集编写R代码,然后很方便地在更强大的云计算机中的更大的数据集上运行代码。
和任何现代的IDE一样,RTVS包括语法高亮、代码格式化、签名帮助、跳转到定义、查找所有引用、代码片段功能。
开发者可以通过R Markdown文档分享数据结果,markdown的代码段可以使用集成的R代码。
RTVS为R提供了完整的REPL体验,可以在交互窗口中直接运行源文件的代码。
绘图是R的一个重要部分。为了方便用R绘图,RTVS支持多个独立的绘图窗口,每个具有独立的历史,并支持在窗口间移动图形。图形可以保存为图像或PDF文件,或者复制到剪贴板。
变量探索器可供检查全局作用域和指定包的作用域中的变量,还能查看可排序的表格,并导出至CSV。
https://github.com/Microsoft/RTVS
Jupyter Notebook的R核心
和许多数据科学家设想的不同,Jupyter并不局限于使用Python:notebook应用是语言无关的,这意味着它可以使用其他编程语言。
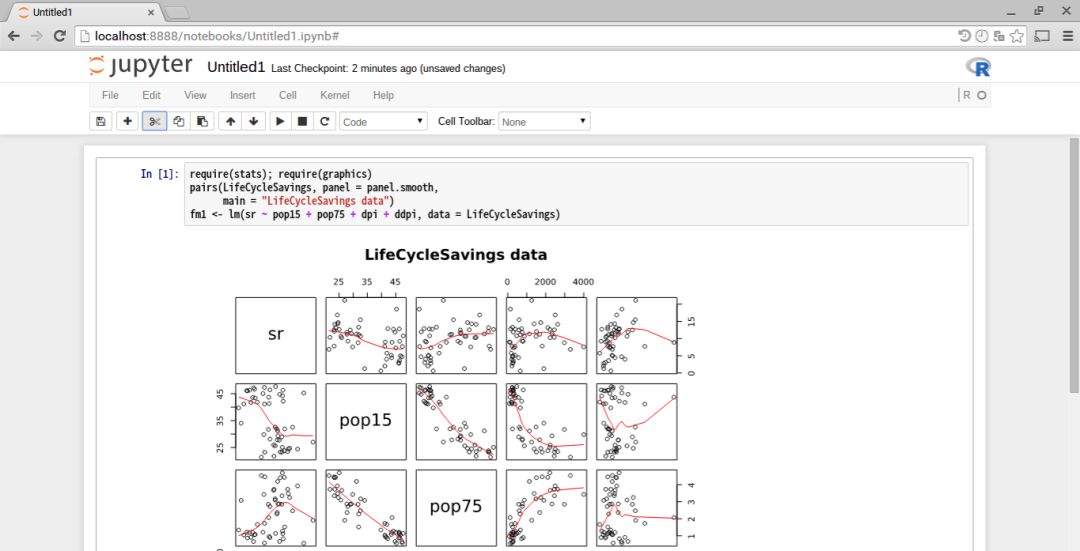
加载IRKernel并启用后,就可以在notebook环境下使用R了。
https://irkernel.github.io/
R-Brain
R-Brain提供了一个数据科学云平台(也可自行部署在内部服务器上)。R-Brain基于Jupyter,提供了IDE、控制台、notebook、markdown的集成环境(支持R和Python)。它也集成了代码补全、调试、打包、发布功能。
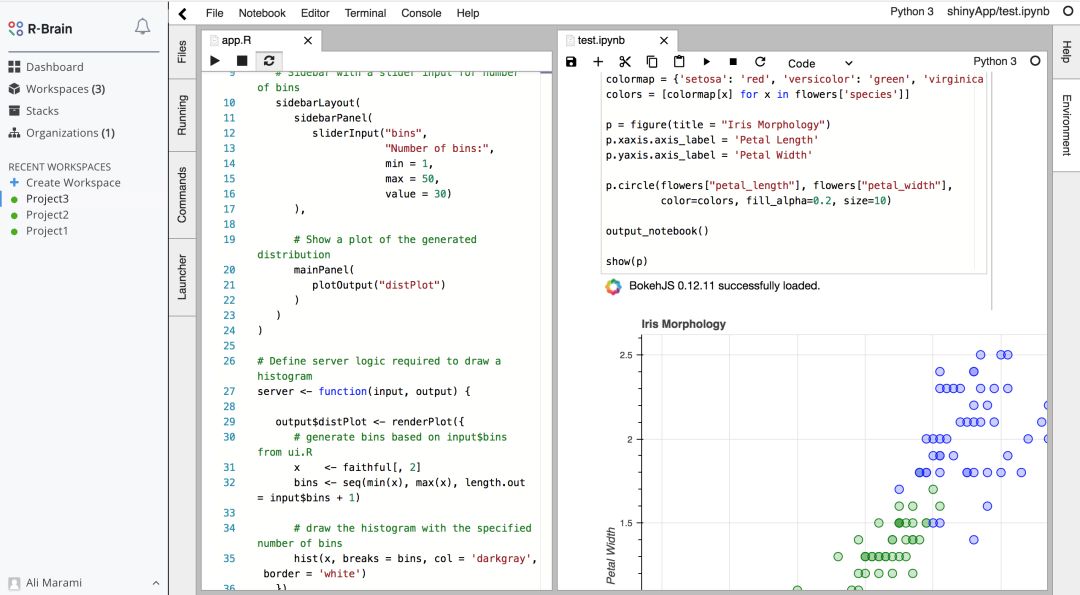
R-Brain以灵活的用户界面提供了经典的Jupyter notebook的标准功能(交互式notebook、终端、文本编辑器、文件浏览器、丰富的输出形式,等等)。它使用了Docker容器技术,所以这一解决方案可以方便地部署在云上或内部服务器上。
数据科学家可以开发、打包、分享、发布分析工作区,数据集,用R、Python、SQL编写的应用。R-Brain同样提供了便利的交互浏览数据库纲要、查看表格内容、导出数据的功能。
https://r-brain.io
Scala
Scala IDE for Eclipse
Scala IDE for Eclipse为开发纯Scala应用及Scala-Java混合应用提供了高级编辑、调试支持,可以在Scala和Java引用之间跳转。
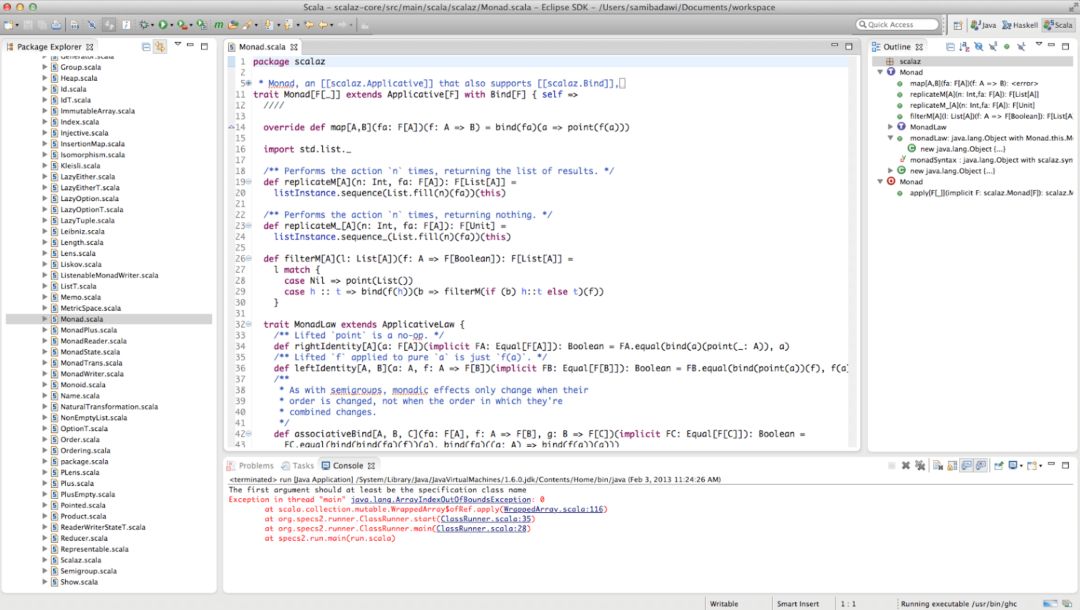
和任何现代IDE一样,它具备代码补全、代码语义高亮、跳转到定义功能。它可以实时捕捉编译错误(在你输入代码的同时)。
Scala调试器可供在闭包间跳转,并提供了为Scala定制的调试信息。
Scala向导简化了类、对象、特质(trait)、包的创建过程。重构功能可以让你修改标识符名,组织引入,提取部分代码为新方法,等等。
Scala IDE的特性还包括代码格式化,智能缩进器,标记文件内的任意标识符,完整的语法高亮支持(包括注释、控制结构、嵌入的XML),代码折叠。
http://scala-ide.org/
IntelliJ IDEA的Scala插件
IntelliJ IDEA是另一个JetBrains出品的知名IDE。Scala插件使IntelliJ IDE可以支持Scala、SBT、Scala.js、Hocon、Play框架。
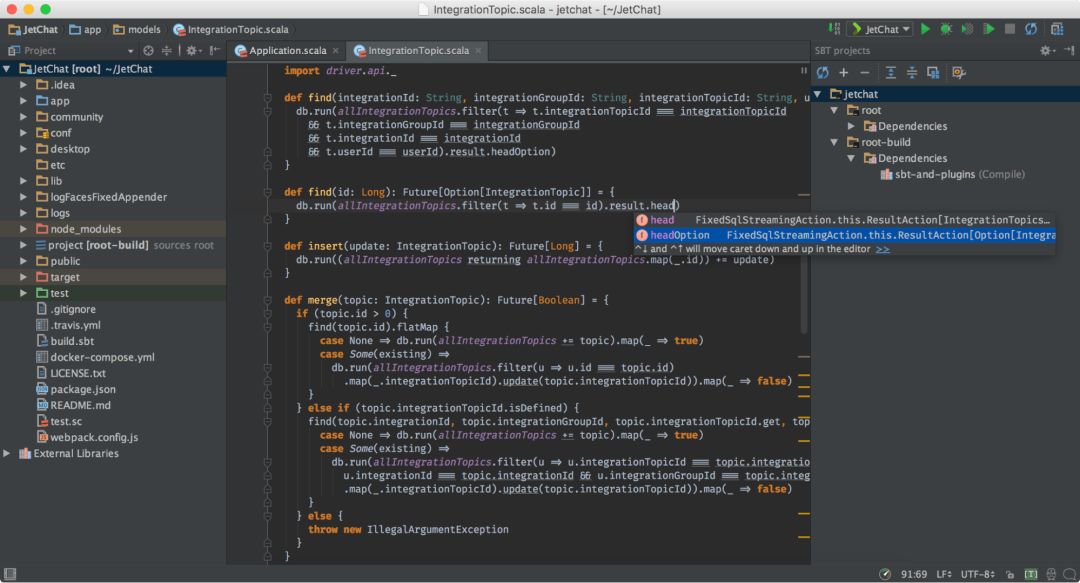
Scala插件支持以下特性:代码辅助(高亮、补全、格式化、重构),浏览,查找,类型和隐式转换信息。该插件同样支持SBT等构建工具,ScalaTest、Specs2、uTest等测试框架。还有Scala调试器、工作表、Ammonite脚本。
https://plugins.jetbrains.com/plugin/1347-scala
Jupyter Notebooks
Scala或Apache Toree核心相当容易安装,都具有增加Maven/SBT依赖和JAR的功能。和Python、R一样,notebook中的单元可以分别运行,这让数据科学家可以训练一次模型后多次使用。
单元支持可以markdown(含LaTeX公式支持),这让数据科学家可以使用notebook作为和客户、同事分享的报告。
和其他语言一样,使用Jupyter Notebook的不足在于核心容易出错或功能有限,非常有限的调试功能,甚至没有调试功能。数据科学家需要仔细地组织他们的单元,否则可能导致很多困惑。
Scale核心:http://almond-sh.github.io/almond/stable/docs/intro
Apache Toree: https://github.com/apache/incubator-toree
Julia
Juno
Juno使用Julia这一结合了易用和性能的语言构建。Juno的目标是移除编程的沮丧和猜测,将乐趣带回编程。Juno的混合风格结合了notebook的探索能力和IDE的高效。
Juno基于GitHub出品的Atom编辑器,继承了Atom强大的编辑功能和美观的用户界面。
Juno同时包含Julia和Atom包,以提供Julia特定的增强,例如语法高亮,绘图面板,集成Julia调试器Gallium,运行代码的控制台,等等。
它的定制性很强,具备面向高级用户的特性,例如多光标、模糊文件搜索、vim键绑定。
http://junolab.org/
Jupyter Notebooks
IJulia提供了Julia语言后端,可以让你在Jupyter Notebook中使用Julia语言。IJulia允许定制Julia运行环境,安装额外的Julia核心。IJulia还有一个贴心的功能,当你输入IPython魔法命令时,IJulia会提示效果相似的Julia代码。例如,输入%load filename会提示你使用IJulia.load("filename")。
https://github.com/JuliaLang/IJulia.jl
Visual Studio Code的Julia扩展
Visual Studio Code的Julia扩展提供了语法高亮、代码片段、LaTex片段、Julia特定命令、集成REPL、代码补全、悬浮提示、代码检查、代码导航等功能,以及用于运行测试、构建、性能评测、构建文档的Visual Studio Code任务。
https://marketplace.visualstudio.com/items?itemName=julialang.language-julia
原文地址:https://semanti.ca/blog/?recommended-ide-for-data-scientists-and-machine-learning-engineers

星标论智,每天获取最新资讯