WSDM 2019教程—李航、何向南等,深度学习匹配在搜索和推荐中的应用
【导读】匹配是搜索和推荐中的关键问题,在很多任务中都有着广泛的应用,比如很多自然语言处理任务(信息检索,自动问答,机器翻译,对话系统)都可以抽象成文本匹配问题。过去传统的匹配问题只要集中在人工定义特征之上的关系学习,模型的效果很依赖特征的设计。而深度学习的引入,能够从大量数据中自动学习特征表示,并且能够更好的拟合复杂的交互关系。在WSDM 2019上来自中国人民大学的徐君研究员,中科大的何向南教授,以及今日头条副总裁李航博士共同带来深度学习匹配搜索和推荐深度学习匹配在搜索和推荐中这两个任务中的应用。

【深度学习匹配在搜索和推荐中的应用PPT下载】
请关注专知公众号(点击上方蓝色专知关注)
后台回复“深度学习搜索推荐” 就可以获取《PPT》的下载链接~
教程介绍
匹配是搜索和推荐中的关键问题。近年来,深度学习已经成功地应用到多种任务中,基于神经网络的匹配模型在实践中得到了广泛的应用,包括用于搜索的深度语义匹配模型和用于推荐的神经协同过滤模型。在本教程中,讲者将全面介绍基于深度学习的搜索和推荐匹配的最新进展。本教程的独特之处在于它提供了关于搜索和推荐的统一视图。通过将这两个任务统一在匹配的观点下,并对现有的技术进行比较回顾,会使听众对这一领域产生更深层次的理解和更多的见解。
相关链接:
1、深度文本匹配综述,庞亮,兰艳艳,徐君,郭嘉丰,万圣贤,程学旗
http://cjc.ict.ac.cn/online/onlinepaper/pl-201745181647.pdf
2、MatchZoo:中科院计算所开源深度文本匹配开源工具
https://github.com/NTMC-Community/MatchZoo
主讲人介绍
徐君,中国人民大学信息学院教授
http://info.ruc.edu.cn/academic_professor.php?teacher_id=169
徐君分别于2001年和2006年获得南开大学学士学位和博士学位。毕业后先后就职于微软亚洲研究院、华为诺亚方舟实验室和中科院计算所,任副研究员和研究员,2018年9月加入中国人民大学,任教授。徐君的研究兴趣包括信息检索、机器学习和大数据分析,在SIGIR、WWW、ACL、CIKM、WSDM、AAAI等国际学术会议和JMLR、TKDE、TOIS、TIST等期刊发表论文五十余篇,获专利授权10项;所提出的排序学习算法收录于多本国际知名信息检索教科书和计算机手册,在多所国际知名大学的课程中被讲授,应用于开源系统Lemur以及微软、华为的搜索产品;获SIGIR '17和SIGIR '18 Test of time award提名、CIKM '17 Best Full PaperRunner-up、AIRS '10和ICMLC '05最佳论文奖。徐君是期刊JASIST编委成员,担任SIGIR、AAAI、WWW和ACML等国际会议的高级程序委员会委员(Senior PC)。
何向南,中国科学技术大学教授,博导
http://www.comp.nus.edu.sg/
何向南博士曾是新加坡国立大学媒体搜索实验室的博士后研究员,主要研究方向有推荐系统、信息检索、多媒体和自然语言处理。他在SIGIR, WWW, MM, CIKM, IJCAI和AAAI等顶级会议以及包括TKDE和TOIS在内的顶级期刊上发表了超过20篇出版物。他的推荐系统工作已经获得ACMSIGIR 2016年度最佳论文奖。
李航,今日头条人工智能实验室主任
北京大学、南京大学客座教授,IEEE 会士,同时也是ACM 杰出科学家,CCF高级会员。他的研究方向包括信息检索,自然语言处理,统计机器学习,及数据挖掘。
深度学习匹配在搜索和推荐中的应用


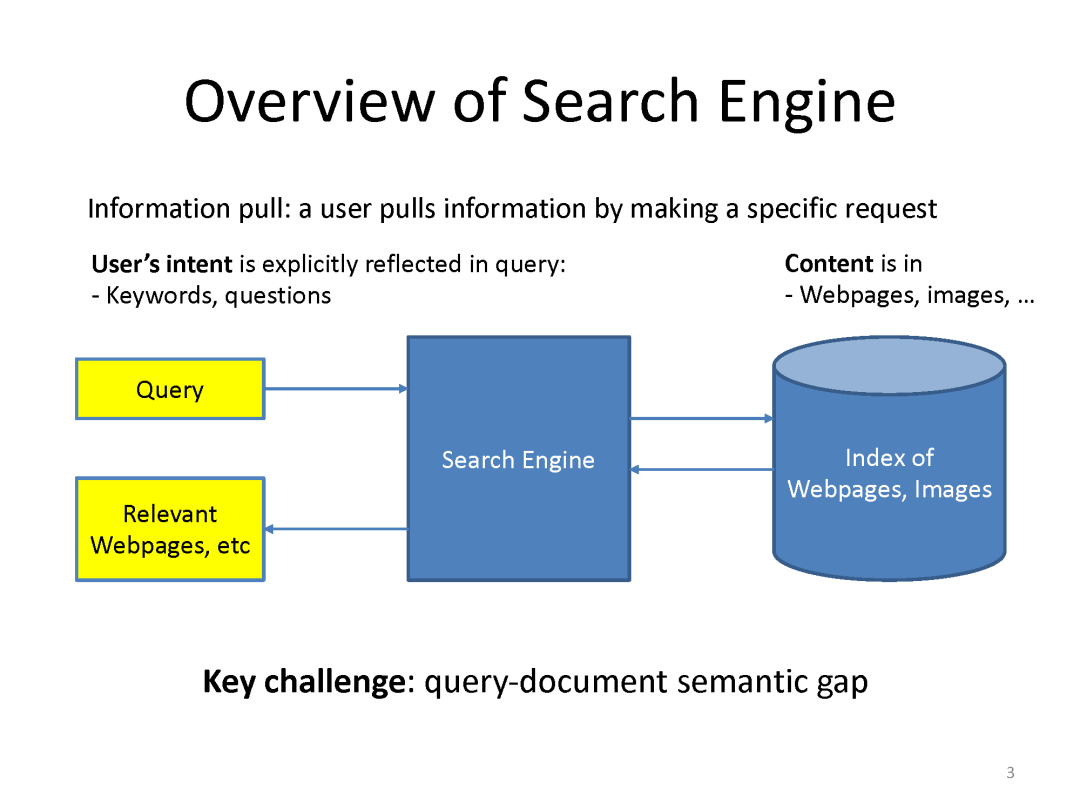

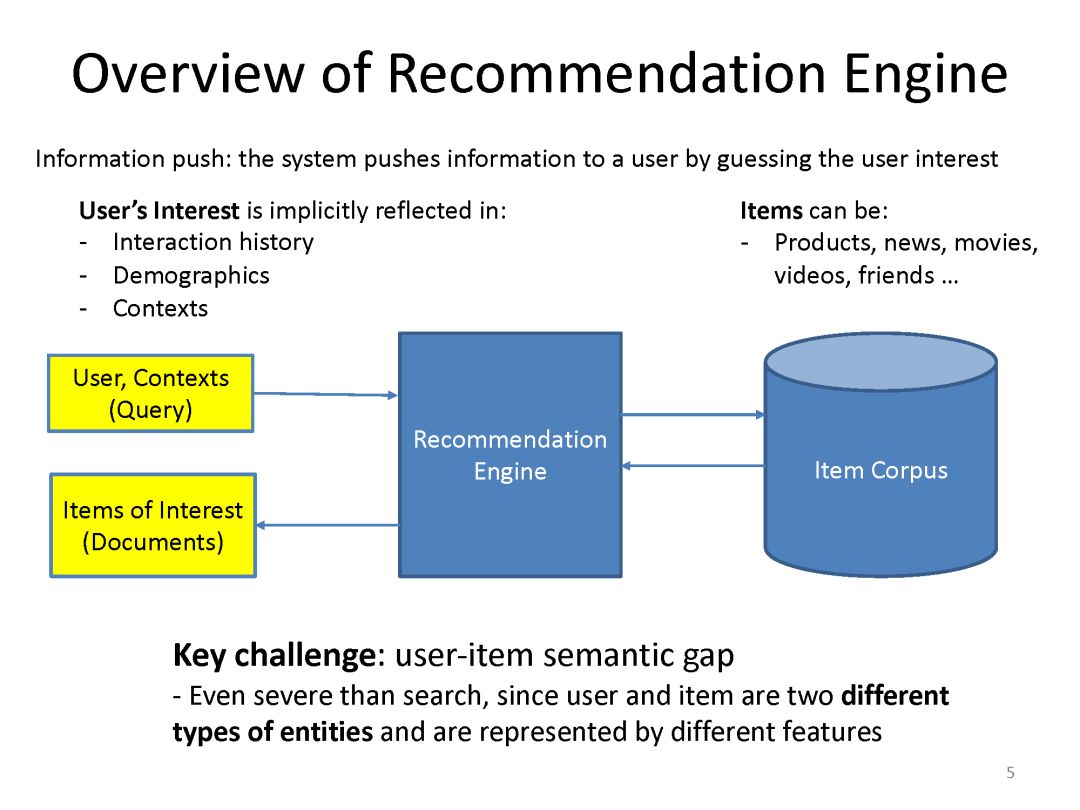
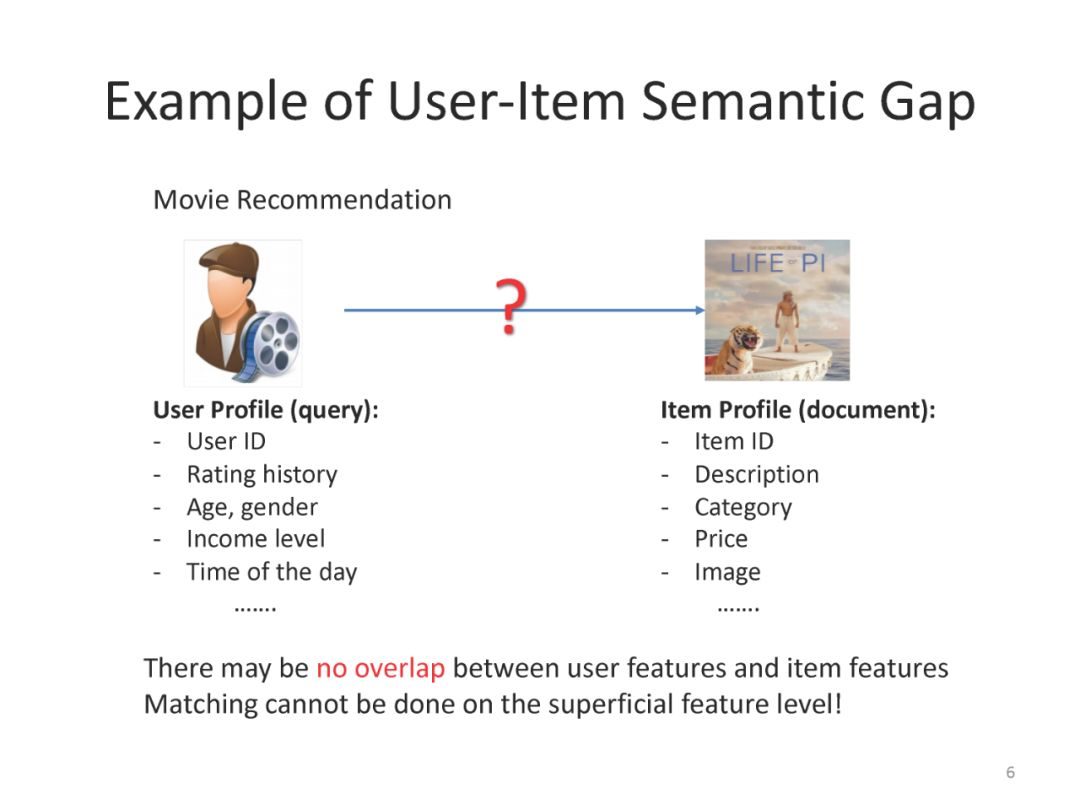

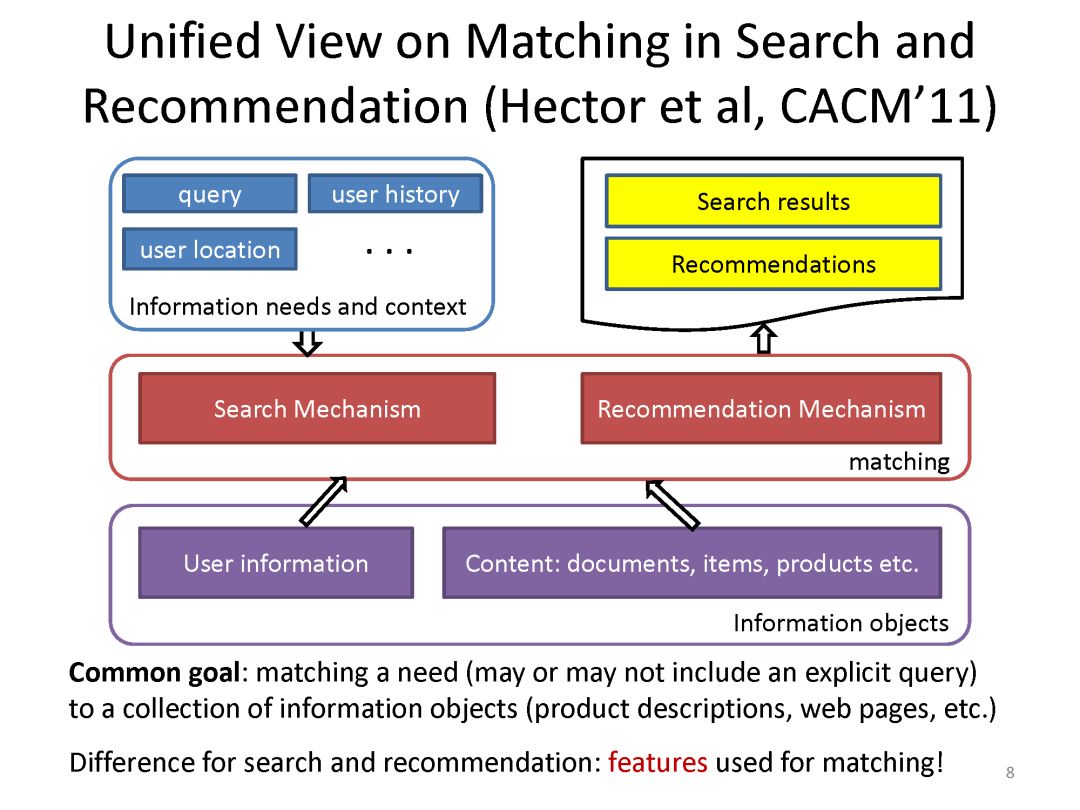

下面是最近一系列使用deep matching 进行推荐方面的工作
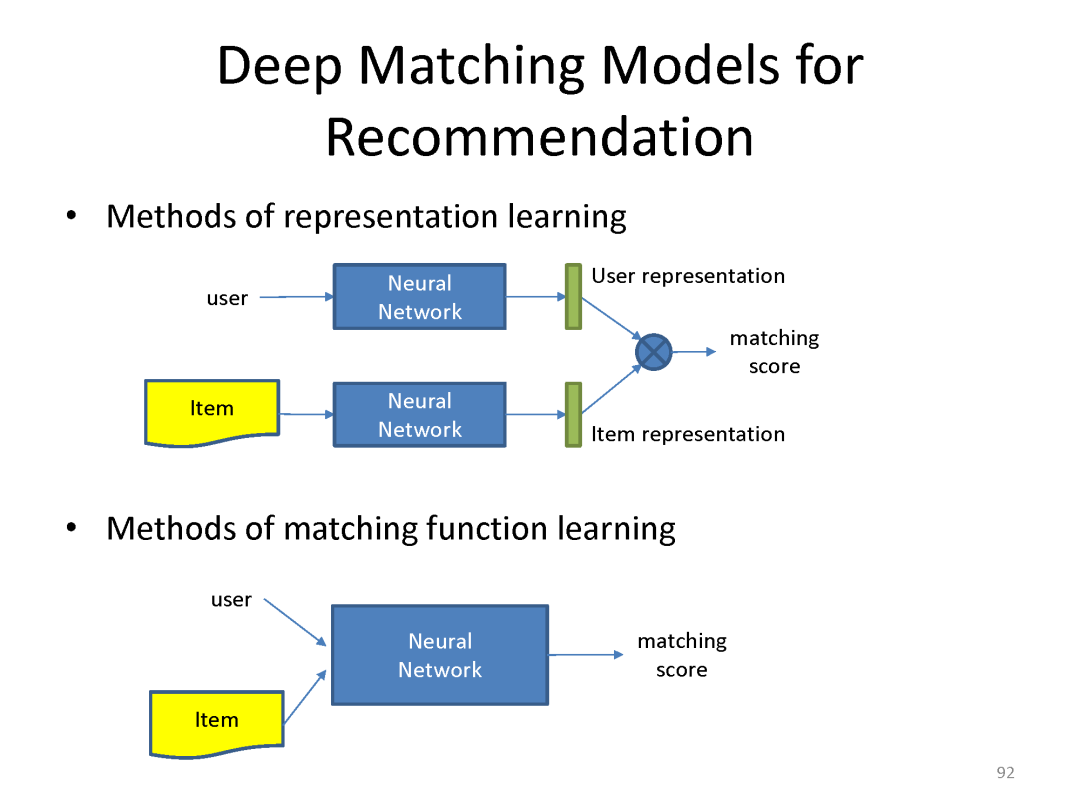

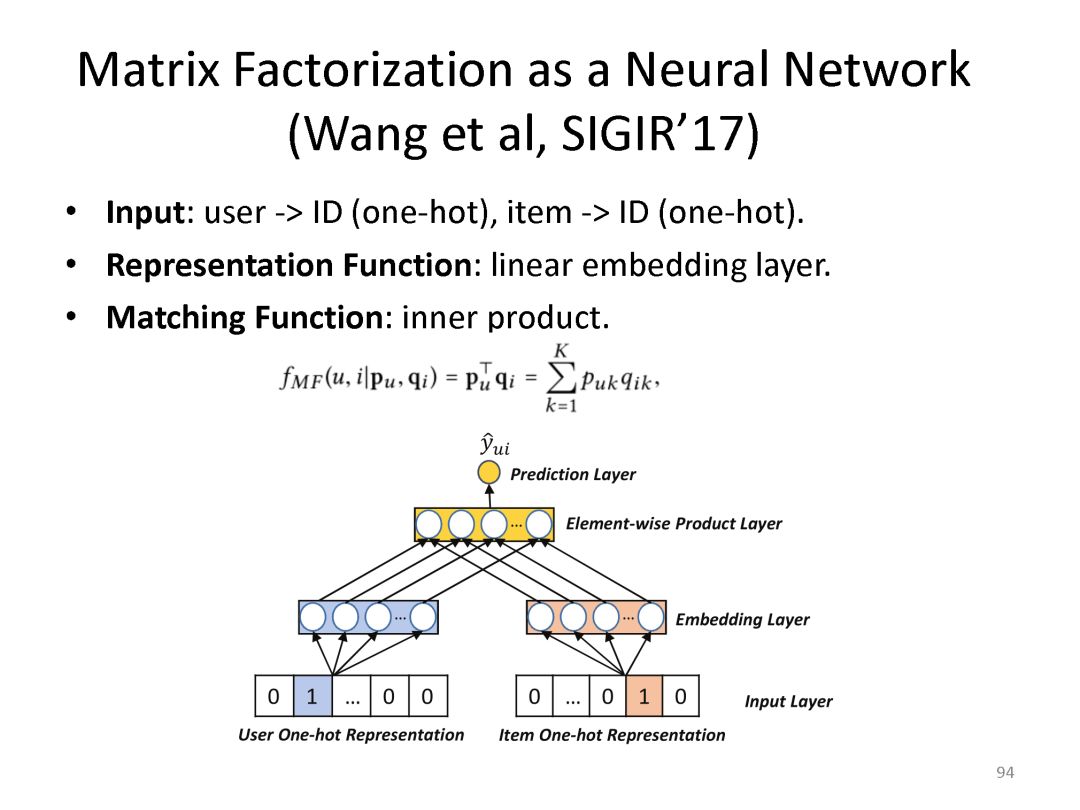
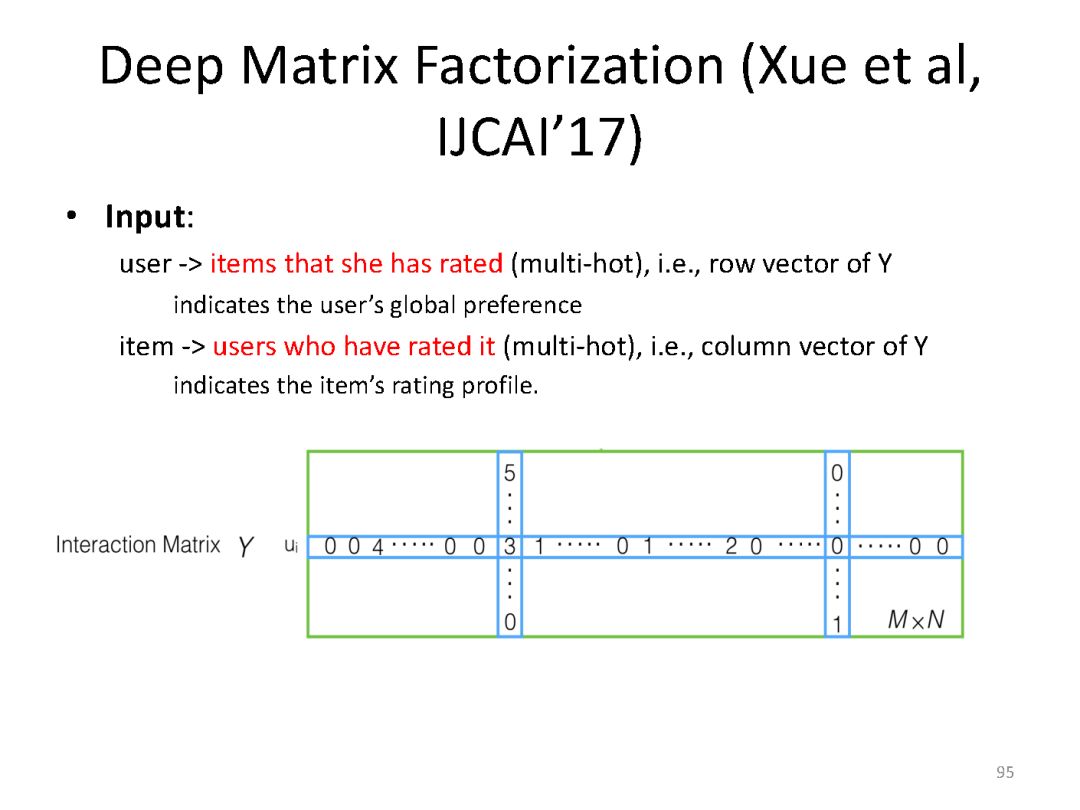
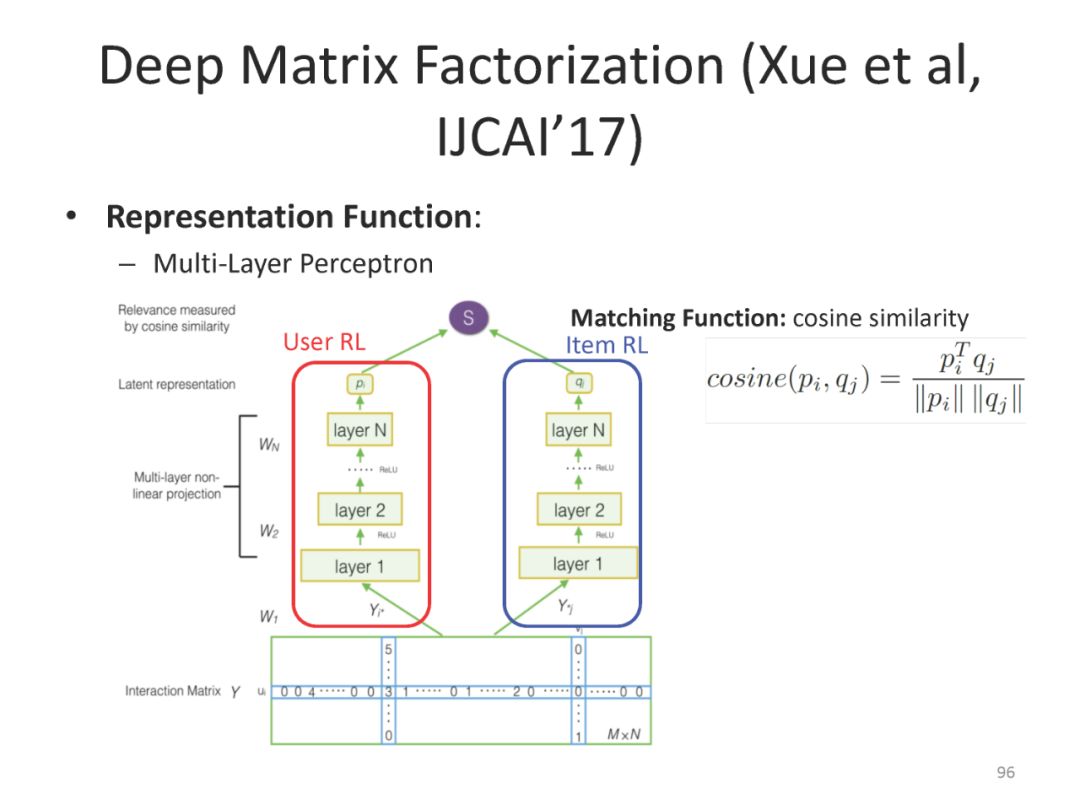
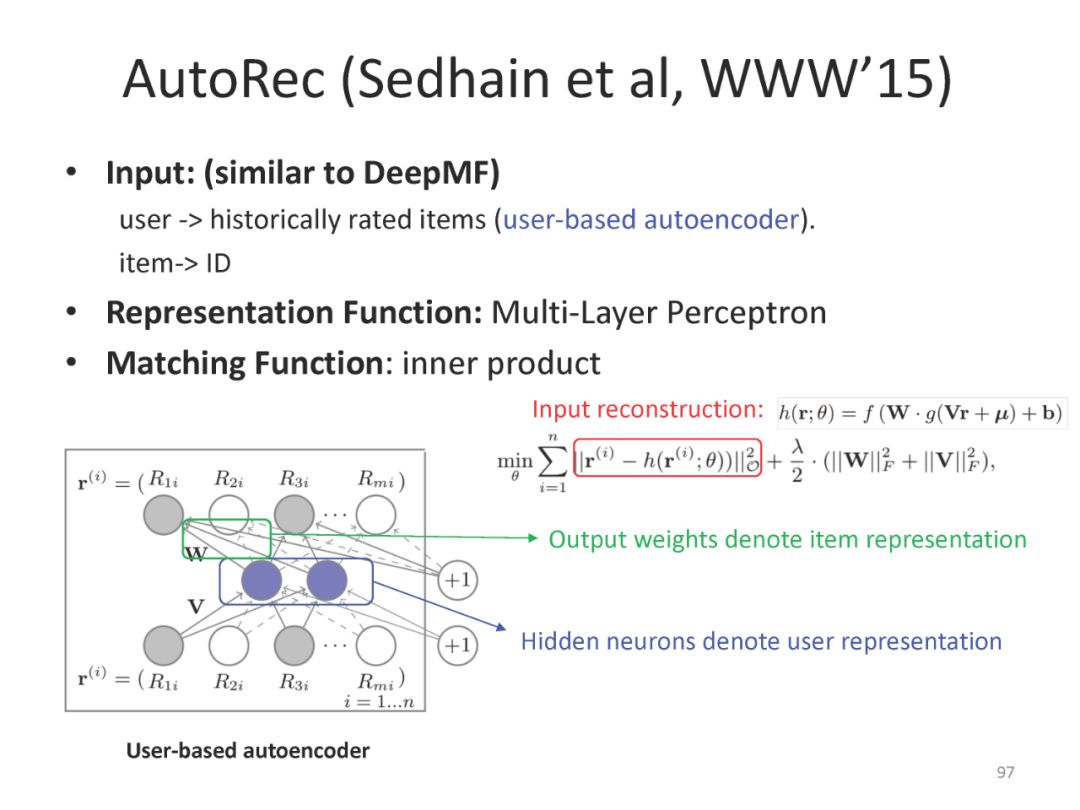
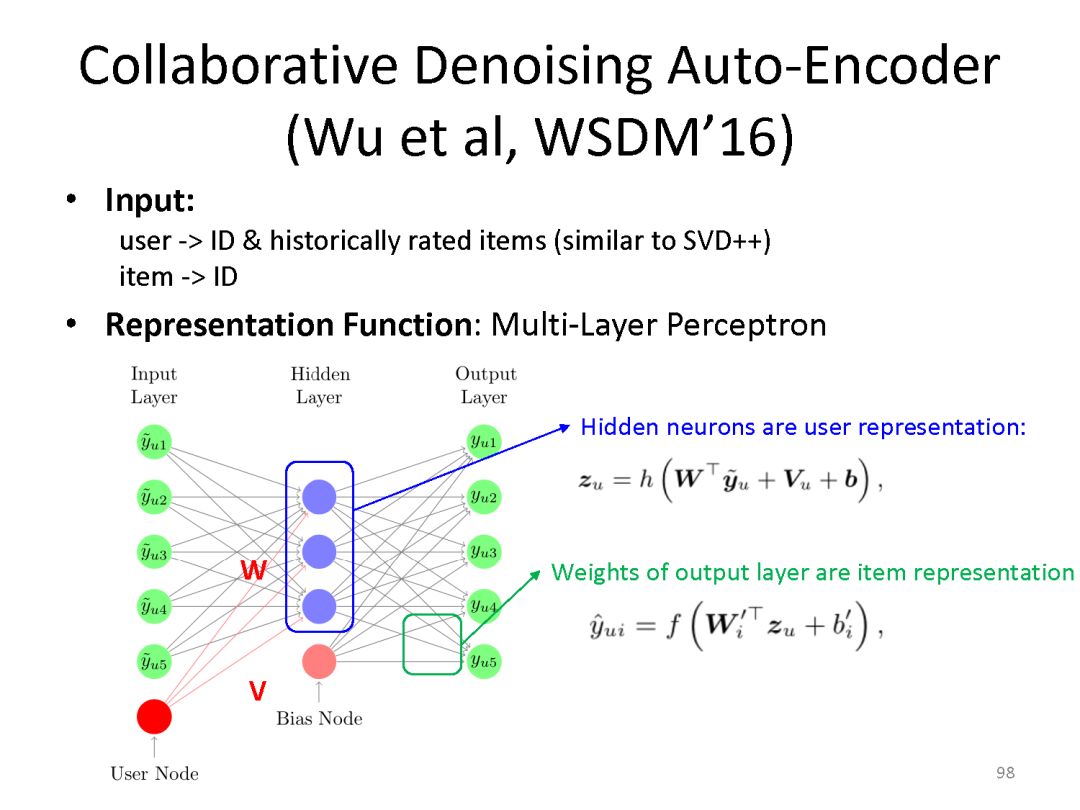
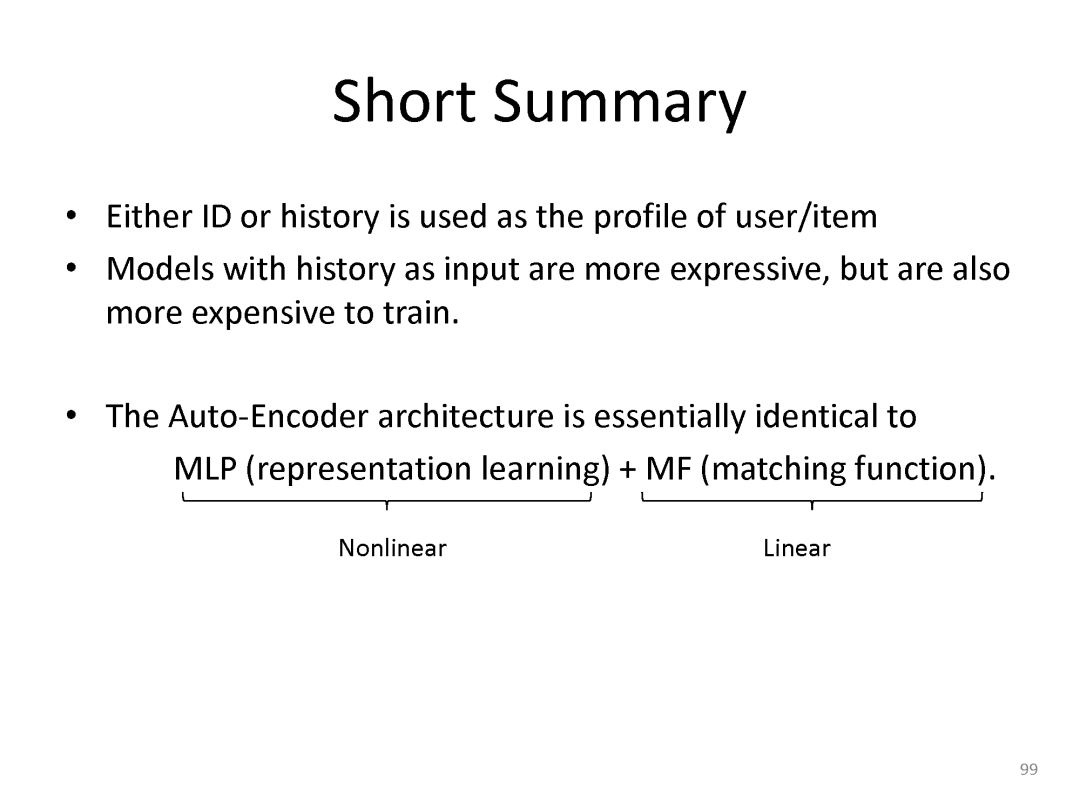

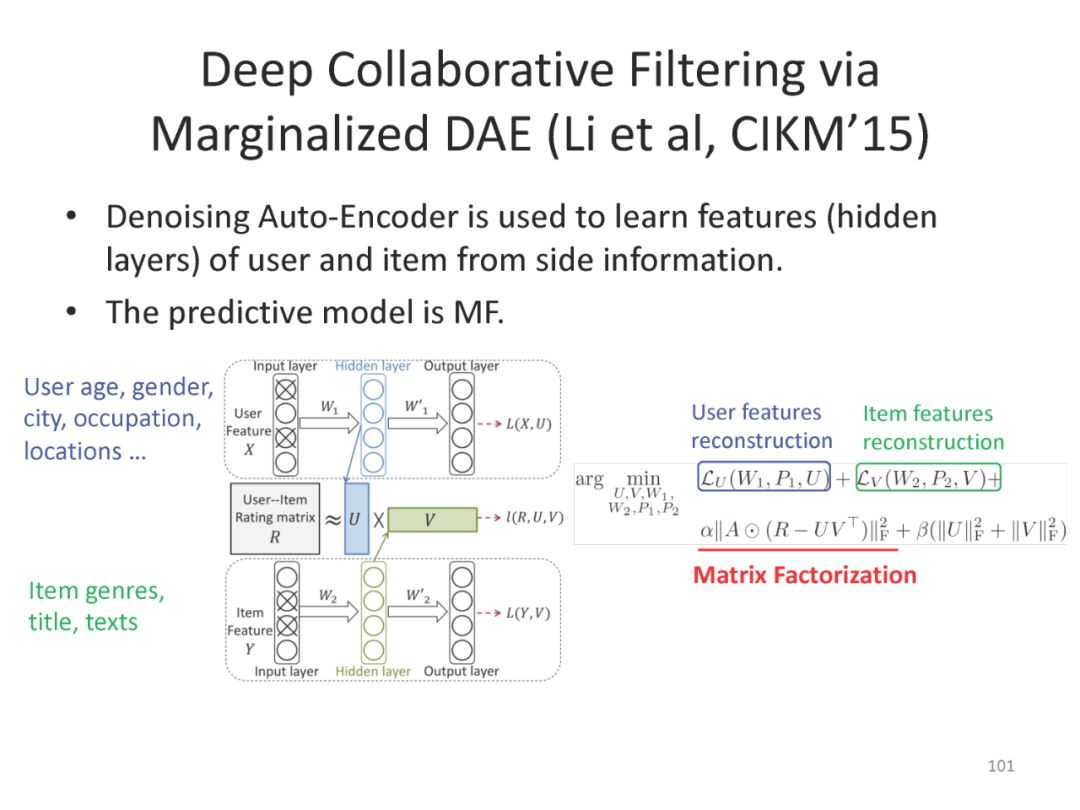

最后总结搜索和推荐两个应用都可以统一到matching视角下。

当前的挑战,也为之后的研究提供了很多思路。

参考链接:
http://www.wsdm-conference.org/2019/tutorials.php
http://www.hangli-hl.com/uploads/3/4/4/6/34465961/wsdm_2019_tutorial.pdf
-END-
专 · 知
专知《深度学习:算法到实战》课程全部完成!470+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

请加专知小助手微信(扫一扫如下二维码添加),咨询《深度学习:算法到实战》参团限时优惠报名~

欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程





