[预训练语言模型专题] XLNet:公平一战!多项任务效果超越BERT

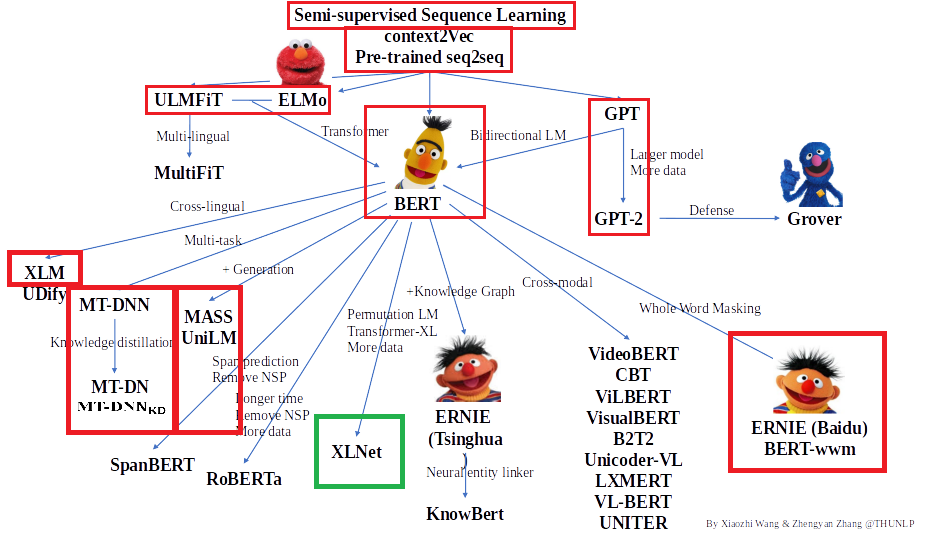
XLNet: Generalized Autoregressive Pretraining for Language Understanding(2019)
-
自回归语言模型(AR)
代表模型为ELMo和GPT,他们的语言模型任务是已知一段文本序列去建模后向或前向文本的概率分布。比如已知前t个文本的序列,来获得t位置文本的条件概率分布。它由回归分析发展而来,而这里预测的是该文本自己,所以被称为自回归。由这种定义,自回归语言模型是仅能建模单向的文本的概率分布,无法有效地深层双向的context。但众所周知,双向信息对预训练语言模型是很重要的,这也是自回归语言模型的一大问题。
-
自编码语言模型(AE)
代表模型为BERT,自编码语言模型的目的就不是去直接地估计下一段文本的条件密度,而是从被掩盖或残缺的文本中来重新构建原始的文本。像BERT,原始文本中的一定比例token会被mask掉,然后训练模型从被mask掉的文本中重现原来的文本。因为并非用条件概率密度估计作为目标,BERT就可以同时利用上下文的信息来重构原始文本,带来了极大的收益。但是BERT的一个问题是在预训练的时候,输入文本因为任务的原因,含有不少[MASK] token,但是在finetune的时候是没有的,导致了pretrain-finetune discrepancy。同时,BERT的mask策略导致它假设每个被预测(掩蔽的)词 在给定未屏蔽的 词 的情况下彼此独立,这在很多时间是不成立的,掩盖的词之前常常也会有相关联系。
对于这两种训练模式的优缺点,本文提出了XLNet,一种通用的自回归训练方法,权衡了两者的优点,回避了他们各自的不足,主要的思路是两点:
-
相比于AR模型任务中用前向或者后向的极大似然来建模。XLNet对 所有可能的分解顺序排列进行最大对数似然的优化。通过这种操作,每个位置能看到的context都可以包含左边和右边的tokens。每个位置能够学到所有位置的上下文信息,以此实现双向建模。 -
作为AR语言模型的一种,XLNet 不依赖于数据重建,所以不会像BERT一样有预训练和finetune的差别。同时,自训练目标很自然地利用乘法原则,获得所预测token的联合概率,从而避免了BERT中的被屏蔽词独立假设。
同时,XLNet还做了一些额外的改进:
-
基于AR语言模型的最新进展,XLNet在预训练中融入了Transformer-xl的片段循环机制及相对位置编码,提升了任务地效果,特别是对比较长的文本。 -
直接将Transformer或者Transformer-xl应用于重排列的语言模型效果不好,目标也比较模糊,所以XLNET重新调整了Transformer(-XL)使模糊性消除。
在可比较的实验设置上,XLNet在GLUE上多个自然语言理解数据集上,得到了比BERT更好的结果。
Objective: Permutation Language Modeling
经过上面的比较,AR语言模型和BERT各有各的优点,如何取长补短得到更好的语言模型呢?XLNet借鉴和提出了一种混合排列的语言模型目标。比如说,对于一个长为T的序列x,它有T!种不同的排列方式。如果模型参数是所有顺序共享的,那模型就能从不同的方向接受序列的信息。
比如说,Zt是序列的一种排序,那么这种排序下的模型目标是
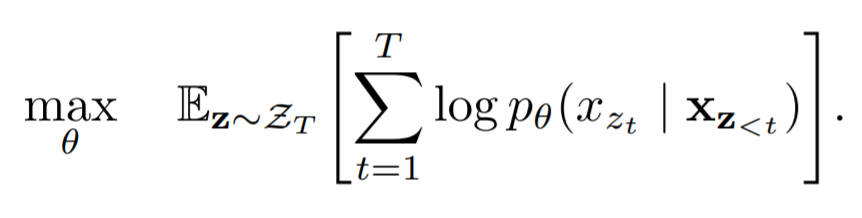
一旦我们采样出一种排序方式Zt,就可以形成一个似然的优化目标。因为所有的顺序都可能出现,所以模型能够学到序列两个方向上所有的信息。同时,因为是AR框架的训练目标,它自然地避免了独立性假设和预训练和finetune时数据的不一致性。
实际上,本文提出的这种训练目标仅仅是改变了因式的顺序,而非序列的顺序。换句话说,作者保持了原来的序列顺序和位置编码,只是在Transformers中使用了合适的attention mask达成了因式的顺序。这种方式是必要的,因为在finetune时,模型只会根据序列的自然顺序进行编码。
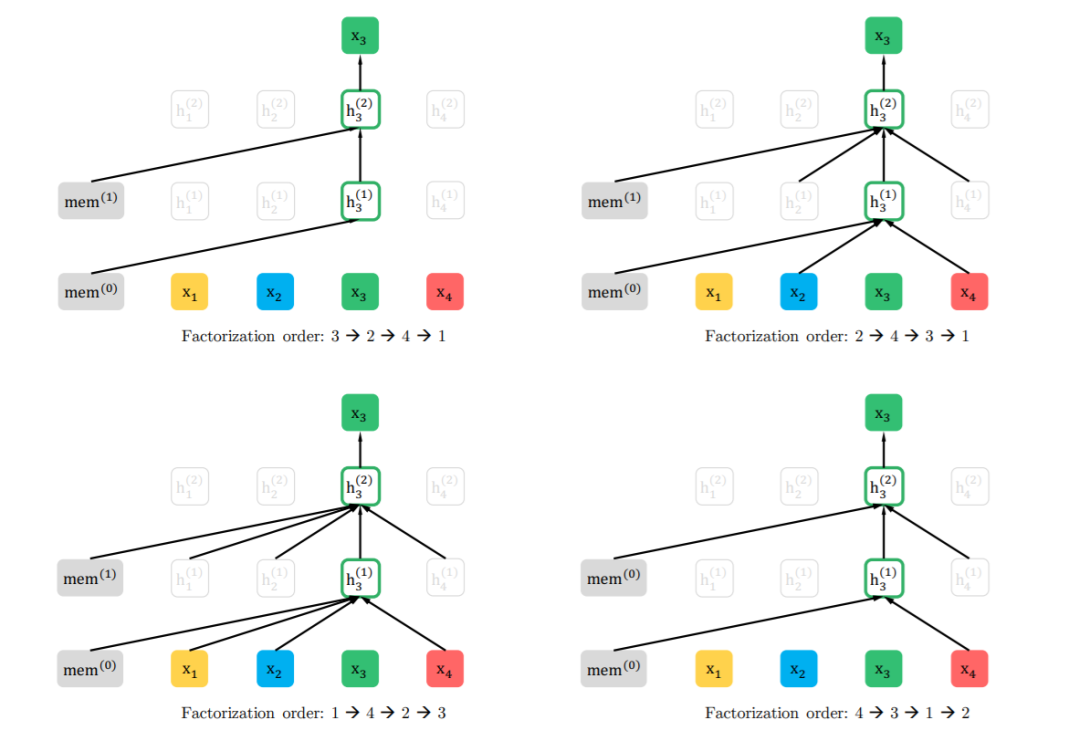
Architecture: Two-Stream Self-Attention for Target-Aware Representations
这种语言模型方式很好,但是在标准的Transformer上使用可能效果不佳,文中附录中举了一个例子。如果有两种不同的排列zt1和zt2,满足
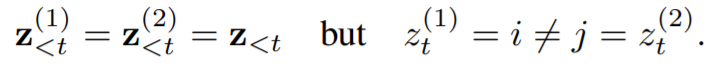
根据原本的极大似然计算方式,下面两个式子的结果应该是一样的,实际上,根据所预测target不同,其真实的分布必然应该是不同的。
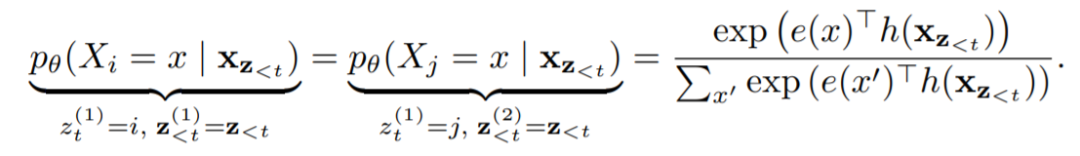
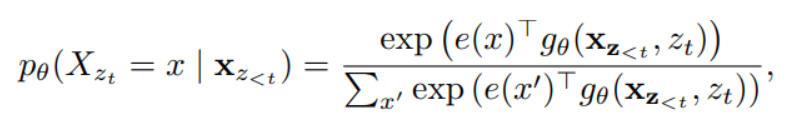
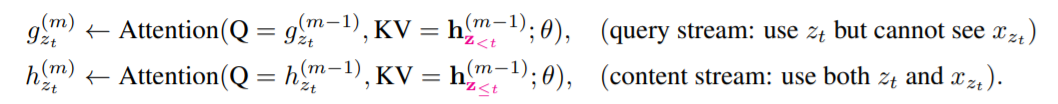
Incorporating Ideas from Transformer-XL
本文借鉴了不少Transformer-XL中的方法,而且以"XL"命名。这些方法主要包括相对位置编码和片段循环机制。有关内容可以参考我们关于Transformer-XL的推送。下图为XLNet中片段循环的公式。
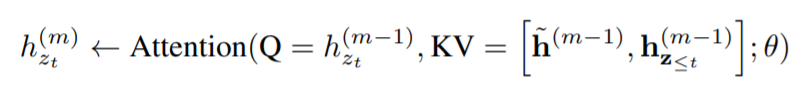
模型细节
最后,XLNet使用了很多数据来预训练,包括BooksCorpus,Engligh Wikipedia, Giga5,ClueWeb 2012-B,Common Crawl总共大概158G左右的文本,这个比BERT用的就多了不少。尺寸最大的XLNET是和BERT-large同一个大小,在512TPU v3 chips上训练了500k步,batchsize 8192, 大概训练了5.5天。同时,为了和BERT进行公平比较,作者也训练了XLNET在BooksCorpus,Engligh Wikipedia上的模型进行相同设置下的PK。结果如下:

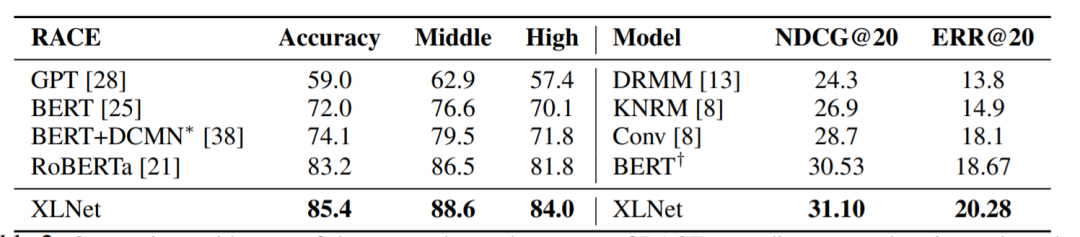
再看在阅读理解数据集上结果,XLNet也领先于两者。
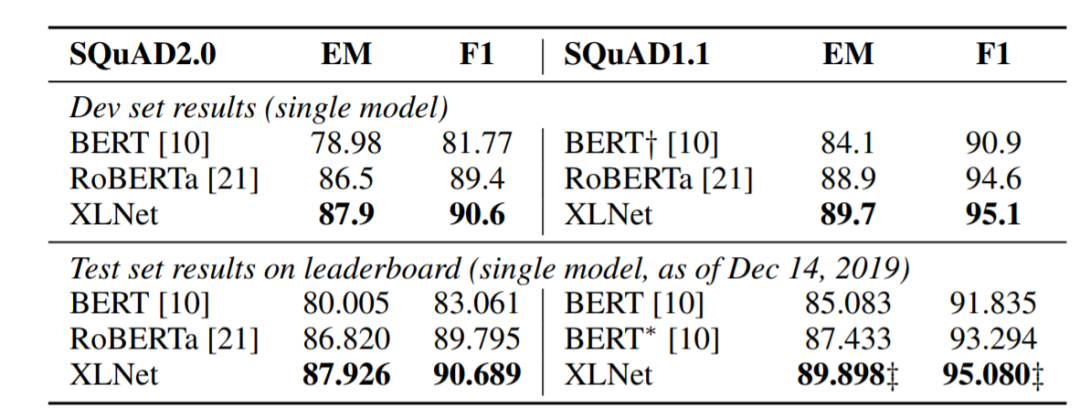
总的而言,XLNet使用了重排列的语言模型目标,结合了AR模型和AE模型的优点,同时XLNet继承了Transformer-XL的片段循环机制和相对编码特性,对文本长时序列进行了更好地处理,在很多任务上超过了之前的模型。
未完待续
本期的论文就给大家分享到这里,感谢大家的阅读和支持,下期我们会给大家带来其他预训练语言模型的介绍,敬请大家期待!
推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。




