不放过任何细节 “火眼金睛”Tiny Faces算法简介
编者按:在CVPR 2017上,Peiyun Hu和Deva Ramanan提出了识别小型物体的方法。本文作者Alexandre Attia和Sharone Dayan对其进行了详细的介绍,并在此基础上进行扩展,不仅做到了图像识别,还对识别出的对象进行了统计。以下是论智对原文的编译。
去年四月,CMU的Peiyun Hu和Deva Ramanan发表了一篇名为Finding Tiny Faces的论文,其中提出了一种新型的寻找小目标物体的方法,该方法基于三个要素:标度不变(Scale Invariance)、图像分辨率(Image resolution)和上下文语境推理(Contextual reasoning)。此外,该算法还是基于“中心凹”(foveal)描述,即模糊外围图像进行编码并提供足够的上下文信息,模仿人类视觉。
这一问题目前仍是公开的挑战,我们希望将这一方法应用于不同的实验中。因此,本文除了介绍该方法外,还会专注于现实中的挑战:不只是发现小物体,还要进行计算以及其他拓展的功能。代码已发布在GitHub上:https://github.com/alexattia/ExtendedTinyFaces
具体方法
就算是人类,想在一张照片中找出所有出镜的人都不是一件容易的事,更何况是机器。因此,我们需要确定如何才能最好地编码上下文。对于语境建模,论文中使用固定大小(291px)的感受野(receptive field)。然后从深度模型有效的中心凹描述中提取“超列”特征,定义模型。该技术在更大的感受野中,既能捕捉高分辨率的细节,也能找到粗糙的低分辨率图像。
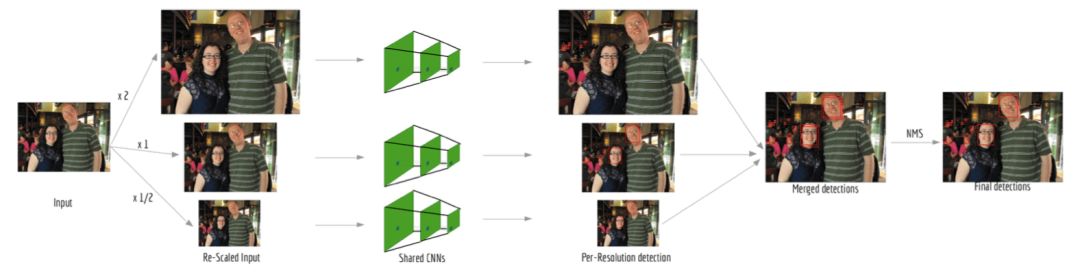
上图是模型的结构。图像输入后被重新缩放,比例特定的检测器用来保证比例固定。然后,将缩放的图像输入卷积神经网络中,预测每分辨率的映射。最后,在原始分辨率下应用非最大抑制(NMS)去除重叠的边界框,得到最终的结果。
此外,该算法的性能受到图像分辨率的影响。确实,我们在实验时缩小了原始图像,并绘制生成了平均Jaccard相似度和检测到的人脸数量。最终得出结论:缩放越小,人脸检测的效果越差。
另外,我们还测试了Tiny Faces算法在模糊人脸上的表现,最终发现,该算法在检测模糊人脸方面比一般方法的表现差得多。
最后,我们将Tiny Faces算法与Faster R-CNN、MT-CNN、Haar Cascades和HOG在WIDERFACE数据集下做了对比,结果如下表:
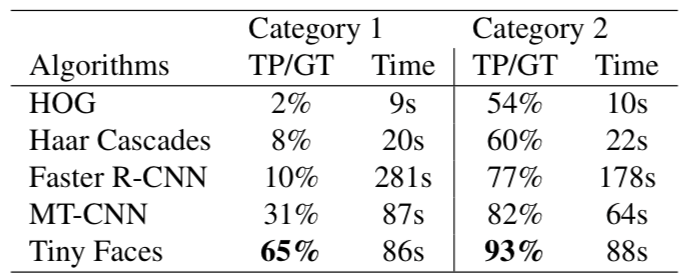
可以看出Tiny Faces算法比其他算法表现得更好,尤其在人脸越多的图中,结果越好。
计算图中人数
计算公共场合中的人数可能是一项艰巨的任务,我们试着把它实现自动化。因此,我们计划用Python构建一个模型,检测和统计视频中的人数。大致流程是:检测脸部、定位、排除重复的计数、统计。
场景的选择是一段音乐视频,我们从中截取了两个片段(每段大概5秒),并对其进行手动标注。为了每个人脸只计算一次,我们必须识别每张人脸,然后在下一帧匹配他们。为此,我们应用了Tiny Faces算法来寻找所有的人脸。在每一帧,我们都先对人脸的位置进行预测,然后再跨帧进行匹配。为了让匹配的过程更容易,我们创建了一个人脸嵌入(face embeddings):将每张图片包裹起来,使人脸始终朝向同一方向。
接着就是将预测人脸与检测到的人脸进行匹配。为了训练模型进行人脸预测,我们首先需要增强数据集。由于视频中的人的位置在两帧之间不会有太大的差别,我们可以使用预测的边界框坐标作为接下来两个框架中的一个人脸。然后,我们使用数据增强技术,例如使用imgaug Python库在每个RGB通道中添加高斯噪声和随机值。最后,我们每张脸部获得10个不同的图像,作为训练集的正面样本。
至于负面样本,我们随机选择了另外十张人脸图像。在每帧训练多个二元分类器(每张人脸一个)之后,我们在同一邻近区域(600px的正方形区域)预测了下一帧中与之最相似的人脸。最终,如下图所示,我们在另一帧中得到了最相像的面孔。

最后,就到了计算人数的步骤了。随着视频的播放,人脸的数量在不断增加。事实上,对于分析的每一帧,我们计算检测到的人数,同时(用人脸匹配)减去已经看到过的人数,所以有效人数就是每一帧新检测到的人数总和。结果如下表:

结语
通过深入分析Tiny Faces的原理,我们对其有了大致了解。不过,虽然其目的是检测小型物体,但现阶段只是应用于人脸识别上,而我们认为这一方法可以应用到其他领域,例如检测乳腺影像中的硬块,带来更多福利。最后是Tiny Faces生成的结果案例,真的是不放过每一个角落啊!


原文地址:arxiv.org/pdf/1801.06504.pdf




