PyTorch-专知-链路化知识-4、< 快速理解系列 (三): 图文 代码, 让你快速理解 GAN >
4、< 快速理解系列(三): 图文 代码, 让你快速理解GAN>
生成对抗网络 ( GAN )
GAN的思想与训练方法
GAN[Goodfellow Ian,GAN]启发自博弈论中的二人零和博弈(two-player game),由[Goodfellow et al, NIPS 2014]开创性地提出。在二人零和博弈中,两位博弈方的利益之和为零或一个常数,即一方有所得,另一方必有所失。GAN模型中的两位博弈方分别由生成式模型(generative model)和判别式模型(discriminative model)充当。生成模型G捕捉样本数据的分布,判别模型是一个二分类器,估计一个样本来自于训练数据(而非生成数据)的概率。G和D一般都是非线性映射函数,例如多层感知机、卷积神经网络等。如图2-1所示,左图是一个判别式模型,当输入训练数据x时,期待输出高概率(接近1);右图下半部分是生成模型,输入是一些服从某一简单分布(例如高斯分布)的随机噪声z,输出是与训练图像相同尺寸的生成图像。向判别模型D输入生成样本,对于D来说期望输出低概率(判断为生成样本),对于生成模型G来说要尽量欺骗D,使判别模型输出高概率(误判为真实样本),从而形成竞争与对抗。
模型一览
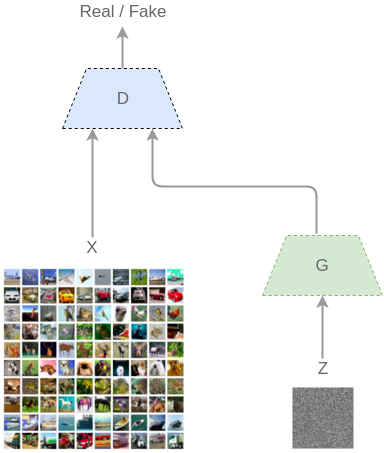
生成对抗网络同时训练两个模型, 叫做生成器(Generator 图中G)和判断器(Discriminator 图中D). 生成器竭尽全力模仿真实分布生成数据; 判断器竭尽全力区分出真实样本和生成器生成的模仿样本. 直到判断器无法区分出真实样本和模仿样本为止.
通过这种方式, 损失函数被蕴含在判断器中了. 我们不再需要思考损失函数应该如何设定, 只要关注判断器输出损失就可以了.
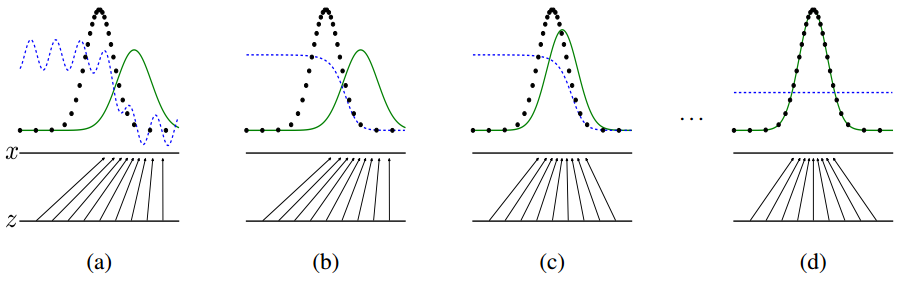
(a)图中真实分布和生成器的分布比较接近, 但是判定器很容易区分出二者生成的样本. (b)图中判定器又经过训练加强判断, 注意判定分布. (c)图是生成器调整分布, 更好地欺骗判定器. (d)图是不断优化, 直到生成器非常逼近真实分布, 而且判定器无法区分.
下图是Ian J. Goodfellow等人论文中在MNIST和TFD数据上训练出的对抗模型生成的样本:

最右边一列是真实数据集中最接近的邻居样本, 证明生成模型的有效性. 生成右边导数第二列和真实样本非常接近, 但是确是对抗网络随机生成的图片. 可见, 对抗网络对于随机生成一些图片干扰很在行, 这些干扰并不影响人造样本和真实样本的相似性.
import torch
import torch.nn as nn
from torchvision import datasets
from torchvision import transforms
from torchvision.utils import save_image
from torch.autograd import Variable
def get_variable(x):
x = Variable(x)
return x.cuda() if torch.cuda.is_available() else x
def denorm(x):
out = (x + 1) / 2
return out.clamp(0, 1)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5),
std=(0.5, 0.5, 0.5))])
mnist = datasets.MNIST(root='./mnist/',
train=True,
transform=transform,
download=True)
data_loader = torch.utils.data.DataLoader(dataset=mnist,
batch_size=100,
shuffle=True)
# 判别器
D = nn.Sequential(
nn.Linear(784, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 1),
nn.Sigmoid())
# 生成器
G = nn.Sequential(
nn.Linear(64, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 784),
nn.Tanh())
if torch.cuda.is_available():
D.cuda()
G.cuda()
loss_func = nn.BCELoss()
d_optimizer = torch.optim.Adam(D.parameters(), lr=0.0003)
g_optimizer = torch.optim.Adam(G.parameters(), lr=0.0003)
for epoch in range(200):
for i, (images, _) in enumerate(data_loader):
batch_size = images.size(0)
# reshape 成 (batch_size, 28*28)
images = get_variable(images.view(batch_size, -1))
real_labels = get_variable(torch.ones(batch_size)) # 真实数据 label 为1
fake_labels = get_variable(torch.zeros(batch_size)) # 假数据 label 为0
# ============= Train the discriminator =============#
# 判别真实数据,计算损失
outputs = D(images)
d_loss_real = loss_func(outputs, real_labels)
real_score = outputs
# 生成假数据
z = get_variable(torch.randn(batch_size, 64))
fake_images = G(z)
# 判别生成的数据,计算损失
outputs = D(fake_images)
d_loss_fake = loss_func(outputs, fake_labels)
fake_score = outputs
# 优化判别器
d_loss = d_loss_real + d_loss_fake
D.zero_grad()
d_loss.backward()
d_optimizer.step()
# =============== Train the generator ===============#
# 生成假数据
z = get_variable(torch.randn(batch_size, 64))
fake_images = G(z)
# 用判别器计算损失
outputs = D(fake_images)
g_loss = loss_func(outputs, real_labels)
# 优化生成器
D.zero_grad()
G.zero_grad()
g_loss.backward()
g_optimizer.step()
if (i + 1) % 300 == 0:
print('Epoch [%d/%d], Step[%d/%d], d_loss: %.4f, '
'g_loss: %.4f, 真实数据平均得分: %.2f, 假数据平均得分: %.2f'
% (epoch, 200, i + 1, 600, d_loss.data[0], g_loss.data[0],
real_score.data.mean(), fake_score.data.mean()))
# 保存一下真实数据
if (epoch + 1) == 1:
images = images.view(images.size(0), 1, 28, 28)
save_image(denorm(images.data), './mnist/real_images.png')
# 保存生成数据
fake_images = fake_images.view(fake_images.size(0), 1, 28, 28)
save_image(denorm(fake_images.data), './mnist/fake_images-%d.png' % (epoch + 1))
# 保存模型参数
torch.save(G.state_dict(), './generator.pkl')
torch.save(D.state_dict(), './discriminator.pkl')
对PyTorch教程感兴趣的同学,欢迎进入我们的专知PyTorch主题群一起交流、学习、讨论,扫一扫如下群二维码即可进入(先加微信小助手weixinhao: Rancho_Fang,注明PyTorch)。

展开全文
