【论文推荐】最新六篇机器翻译相关论文—跨语言推理、单语数据、可扩展工具包、不确定性、合成
【导读】专知内容组整理了最近六篇机器翻译(Machine Translation)相关文章,为大家进行介绍,欢迎查看!
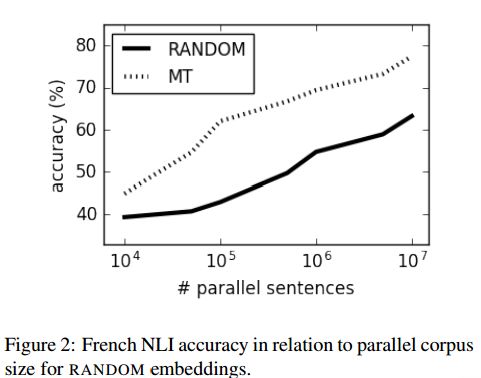
1. Baselines and test data for cross-lingual inference(跨语言推理的基准方法和测试数据)
作者:Željko Agić,Natalie Schluter
摘要:The recent years have seen a revival of interest in textual entailment, sparked by i) the emergence of powerful deep neural network learners for natural language processing and ii) the timely development of large-scale evaluation datasets such as SNLI. Recast as natural language inference, the problem now amounts to detecting the relation between pairs of statements: they either contradict or entail one another, or they are mutually neutral. Current research in natural language inference is effectively exclusive to English. In this paper, we propose to advance the research in SNLI-style natural language inference toward multilingual evaluation. To that end, we provide test data for four major languages: Arabic, French, Spanish, and Russian. We experiment with a set of baselines. Our systems are based on cross-lingual word embeddings and machine translation. While our best system scores an average accuracy of just over 75%, we focus largely on enabling further research in multilingual inference.
期刊:arXiv, 2018年3月3日
网址:
http://www.zhuanzhi.ai/document/4b58e5327c50fa25df9f3d2a8ef69e4d
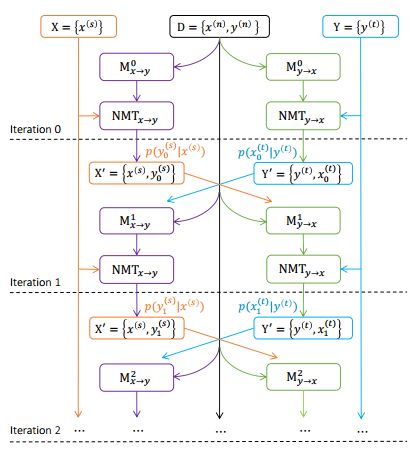
2. Joint Training for Neural Machine Translation Models with Monolingual Data(神经机器翻译模型与单语数据的联合训练)
作者:Zhirui Zhang,Shujie Liu,Mu Li,Ming Zhou,Enhong Chen
摘要:Monolingual data have been demonstrated to be helpful in improving translation quality of both statistical machine translation (SMT) systems and neural machine translation (NMT) systems, especially in resource-poor or domain adaptation tasks where parallel data are not rich enough. In this paper, we propose a novel approach to better leveraging monolingual data for neural machine translation by jointly learning source-to-target and target-to-source NMT models for a language pair with a joint EM optimization method. The training process starts with two initial NMT models pre-trained on parallel data for each direction, and these two models are iteratively updated by incrementally decreasing translation losses on training data. In each iteration step, both NMT models are first used to translate monolingual data from one language to the other, forming pseudo-training data of the other NMT model. Then two new NMT models are learnt from parallel data together with the pseudo training data. Both NMT models are expected to be improved and better pseudo-training data can be generated in next step. Experiment results on Chinese-English and English-German translation tasks show that our approach can simultaneously improve translation quality of source-to-target and target-to-source models, significantly outperforming strong baseline systems which are enhanced with monolingual data for model training including back-translation.
期刊:arXiv, 2018年3月1日
网址:
http://www.zhuanzhi.ai/document/6c13d35eadfdec3f27e352a36a677b43
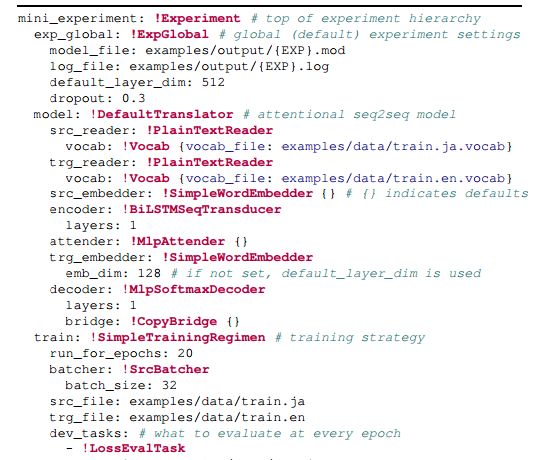
3. XNMT: The eXtensible Neural Machine Translation Toolkit(XNMT:可扩展的神经机器翻译工具包)
作者:Graham Neubig,Matthias Sperber,Xinyi Wang,Matthieu Felix,Austin Matthews,Sarguna Padmanabhan,Ye Qi,Devendra Singh Sachan,Philip Arthur,Pierre Godard,John Hewitt,Rachid Riad,Liming Wang
摘要:This paper describes XNMT, the eXtensible Neural Machine Translation toolkit. XNMT distin- guishes itself from other open-source NMT toolkits by its focus on modular code design, with the purpose of enabling fast iteration in research and replicable, reliable results. In this paper we describe the design of XNMT and its experiment configuration system, and demonstrate its utility on the tasks of machine translation, speech recognition, and multi-tasked machine translation/parsing. XNMT is available open-source at https://github.com/neulab/xnmt
期刊:arXiv, 2018年3月1日
网址:
http://www.zhuanzhi.ai/document/ed48d507e460508c475439c40eb5f0e0
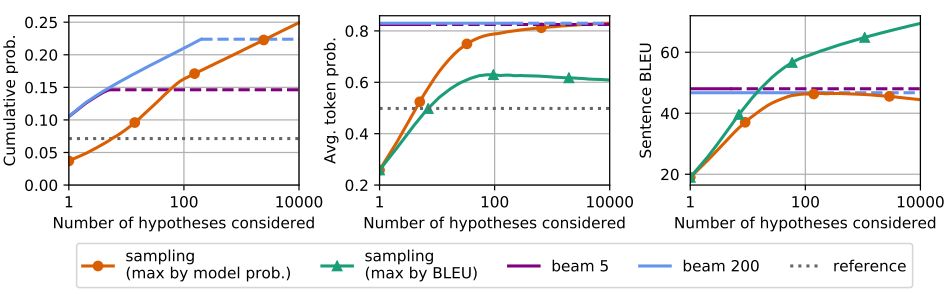
4. Analyzing Uncertainty in Neural Machine Translation(分析神经机器翻译中的不确定性)
作者:Myle Ott,Michael Auli,David Granger,Marc'Aurelio Ranzato
摘要:Machine translation is a popular test bed for research in neural sequence-to-sequence models but despite much recent research, there is still a lack of understanding of these models. Practitioners report performance degradation with large beams, the under-estimation of rare words and a lack of diversity in the final translations. Our study relates some of these issues to the inherent uncertainty of the task, due to the existence of multiple valid translations for a single source sentence, and to the extrinsic uncertainty caused by noisy training data. We propose tools and metrics to assess how uncertainty in the data is captured by the model distribution and how it affects search strategies that generate translations. Our results show that search works remarkably well but that the models tend to spread too much probability mass over the hypothesis space. Next, we propose tools to assess model calibration and show how to easily fix some shortcomings of current models. We release both code and multiple human reference translations for two popular benchmarks.
期刊:arXiv, 2018年3月1日
网址:
http://www.zhuanzhi.ai/document/990277c476def6ecd1d3bdb72787529f
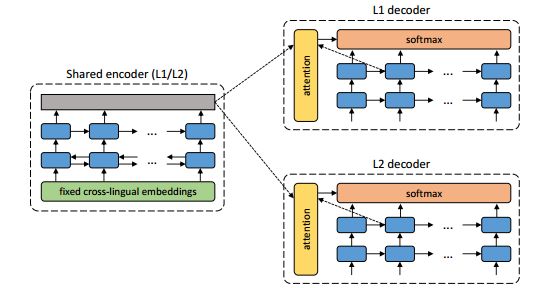
5. Unsupervised Neural Machine Translation(无监督神经机器翻译)
作者:Mikel Artetxe,Gorka Labaka,Eneko Agirre,Kyunghyun Cho
摘要:In spite of the recent success of neural machine translation (NMT) in standard benchmarks, the lack of large parallel corpora poses a major practical problem for many language pairs. There have been several proposals to alleviate this issue with, for instance, triangulation and semi-supervised learning techniques, but they still require a strong cross-lingual signal. In this work, we completely remove the need of parallel data and propose a novel method to train an NMT system in a completely unsupervised manner, relying on nothing but monolingual corpora. Our model builds upon the recent work on unsupervised embedding mappings, and consists of a slightly modified attentional encoder-decoder model that can be trained on monolingual corpora alone using a combination of denoising and backtranslation. Despite the simplicity of the approach, our system obtains 15.56 and 10.21 BLEU points in WMT 2014 French-to-English and German-to-English translation. The model can also profit from small parallel corpora, and attains 21.81 and 15.24 points when combined with 100,000 parallel sentences, respectively. Our implementation is released as an open source project.
期刊:arXiv, 2018年2月27日
网址:
http://www.zhuanzhi.ai/document/c35c1947e05f4d2fcd2e92bfc124e7f1
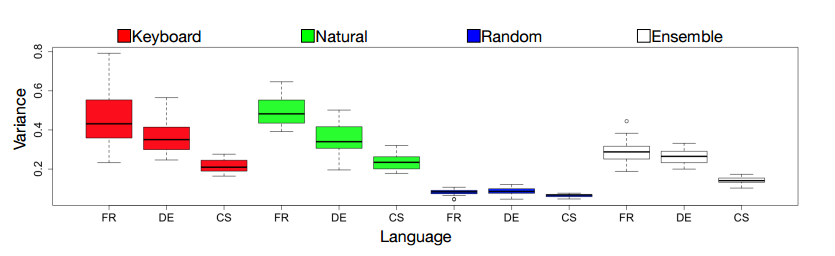
6. Synthetic and Natural Noise Both Break Neural Machine Translation(合成的和自然的噪声都破坏了神经机器翻译)
作者:Yonatan Belinkov,Yonatan Bisk
摘要:Character-based neural machine translation (NMT) models alleviate out-of-vocabulary issues, learn morphology, and move us closer to completely end-to-end translation systems. Unfortunately, they are also very brittle and easily falter when presented with noisy data. In this paper, we confront NMT models with synthetic and natural sources of noise. We find that state-of-the-art models fail to translate even moderately noisy texts that humans have no trouble comprehending. We explore two approaches to increase model robustness: structure-invariant word representations and robust training on noisy texts. We find that a model based on a character convolutional neural network is able to simultaneously learn representations robust to multiple kinds of noise.
期刊:arXiv, 2018年2月25日
网址:
http://www.zhuanzhi.ai/document/3f7e7158db67cf4ceef0107c26cc96f8
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!
展开全文



