条件随机场 (CRF 入门)——工具包介绍
七、 CRF工具包的使用
==================
上一篇文章我们举了一个例子,介绍如何使用CRF解决问题,不过没有给出代码实现,因为CRF思想虽然不难,实现起来工作量还是挺大的。在平时的学习和研究中,使用CRF工具包是一个性价比很高的选择。
CRF++是一个比较小巧的工具,并且具有跨平台性,代码量也不大,之前有人做过实验,发现在各种不同的CRF工具包中,CRF++虽然速度比较慢,但是效果最好,因此受到了广泛的应用。网上可以搜到CRF++的链接,也可以从我这里下载——链接:http://pan.baidu.com/s/1bpJB81D 密码:dgsg。
下载好之后直接解压即可。
解压之后会发现其中有三个文件夹:doc,example,sdk。
doc文件夹:就是官方主页的内容。
example文件夹:有四个任务的训练数据、测试数据和模板文件。
sdk文件夹:CRF++的头文件和静态链接库。
另外还有散装的文件:crf_learn.exe:CRF++的训练程序。 crf_test.exe:CRF++的预测程序 libcrfpp.dll:训练程序和预测程序需要使用的静态链接库。
实际上,需要使用的就是crf_learn.exe,crf_test.exe和libcrfpp.dll,这三个文件。
和许多机器学习工具包一样,CRF++的使用分为两个过程,一个是训练过程,一个是测试过程。我们先用example文件夹中的例子做一下示范。
比如basenp吧,其中原有4个文件:exec.sh;template;test.data;train.data。
template为特征模版;test.data为测试数据;train.data为训练数据。关于它们具体格式和内容,待会详细介绍。
将crf_learn.exe,crf_test.exe和libcrfpp.dll这三个文件复制到这个文件夹basenp里。
cmd
cd进入该文件夹
crf_learn template train.data model 训练数据
crf_test -m model test.data >output.txt 测试数据
第一个命令的意思是,利用模板template,训练数据train.data进行训练,训练的结果保存到模型model中。
第二条命令的意思是,使用模型model在测试数据test.data上进行测试,并将测试结果输出到output.txt中。
使用起来非常简单,不是吗?事实上这两个命令可以有很多的拓展,方便我们适应更多的情况。具体的拓展可以在本文的末尾看到,这里就先略过不提。
数据格式
先来看看工具需要的训练数据和测试数据的格式:

如上所示,”He reckons the current account deficit will narrow to only #1.8 billion in September .”代表一个训练句子x,而CRF++要求将这样的句子拆成每一个词一行并且是固定列数的数据,其中列除了原始输入,还可以包含一些其他信息,比如上面的例子第二列就包含了POS信息,最后一列是Label信息,也就是标准答案y。而不同的训练序列与序列之间的相隔,就靠一个空白行来区分。
特征模版
CRF++训练的时候,要求我们提供特征模版,什么是特征模版呢,先来看如下图片:
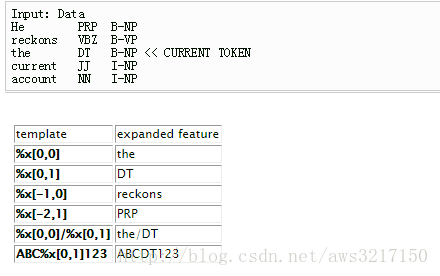
“%x[row, column]” 代表获得当前指向位置向上或向下偏移|row|行,并指向第column列的值。比如上图中,当前指向位置为 “the DT B-NP”,那么”%x[0,0]”代表获得当前指向偏移0行,第0列的值,也就是”the”,而”%x[0,1]”代表获得当前指向偏移0行,第1列的值,也就是”DT”,”%x[-2,1]”则代表获得当前指向向上偏移2行,第1列的值,也就是”PRP”,如此类推。
CRF++中主要有两种特征模版,Unigram和Bigram 模版,注意Unigram和Bigram是相对于输出序列而言,而不是相对于输入序列。对于”U01:%x[0,1]”这样一个模版,上面例子的输入数据会产生如下的特征函数:

假如输出序列的集合大小为:L,那么训练数据的每一行都会产生L个特征函数,假如输入序列长度为N,那么一个Unigram模版将会产生N∗L个特征函数。类似的,一个这样的Bigram模版”B01:%x[0,1]”,会考虑当前输出标签还有上一个输出标签,类似的会产生如下特征函数:

这样组合下将会产生N∗L∗L个特征函数。
测试结果
最终在output.txt中的测试结果格式如下:
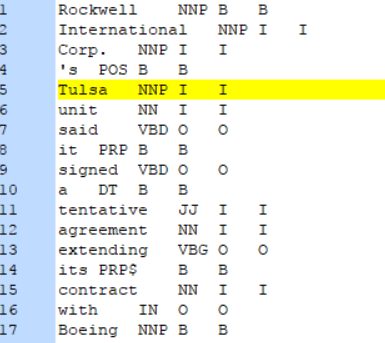
可以看到,前面几列和测试数据一模一样,而最后一列就是我们的模型输出了,非常简单明了。
附:
训练命令:
% crf_learn template train.data model
这个训练过程的时间、迭代次数等信息会输出到控制台上(感觉上是crf_learn程序的输出信息到标准输出流上了),如果想保存这些信息,我们可以将这些标准输出流到文件上,命令格式如下:
% crf_learn template_file train_filemodel_file >> train_info_file
有四个主要的参数可以调整:
-a CRF-L2 or CRF-L1
规范化算法选择。默认是CRF-L2。一般来说L2算法效果要比L1算法稍微好一点,虽然L1算法中非零特征的数值要比L2中大幅度的小。
-c float
这个参数设置CRF的hyper-parameter。c的数值越大,CRF拟合训练数据的程度越高。这个参数可以调整过度拟合和不拟合之间的平衡度。这个参数可以通过交叉验证等方法寻找较优的参数。
-f NUM
这个参数设置特征的cut-off threshold。CRF++使用训练数据中至少NUM次出现的特征。默认值为1。当使用CRF++到大规模数据时,只出现一次的特征可能会有几百万,这个选项就会在这样的情况下起到作用。
-p NUM
如果电脑有多个CPU,那么那么可以通过多线程提升训练速度。NUM是线程数量。
带两个参数的命令行例子:
% crf_learn -f 3 -c 1.5 template_filetrain_file model_file
测试命令:
命令行:
% crf_learn template train.data model
这个训练过程的时间、迭代次数等信息会输出到控制台上(感觉上是crf_learn程序的输出信息到标准输出流上了),如果想保存这些信息,我们可以将这些标准输出流到文件上,命令格式如下:
% crf_learn template_file train_filemodel_file >> train_info_file
有四个主要的参数可以调整:
-a CRF-L2 or CRF-L1
规范化算法选择。默认是CRF-L2。一般来说L2算法效果要比L1算法稍微好一点,虽然L1算法中非零特征的数值要比L2中大幅度的小。
-c float
这个参数设置CRF的hyper-parameter。c的数值越大,CRF拟合训练数据的程度越高。这个参数可以调整过度拟合和不拟合之间的平衡度。这个参数可以通过交叉验证等方法寻找较优的参数。
-f NUM
这个参数设置特征的cut-off threshold。CRF++使用训练数据中至少NUM次出现的特征。默认值为1。当使用CRF++到大规模数据时,只出现一次的特征可能会有几百万,这个选项就会在这样的情况下起到作用。
-p NUM
如果电脑有多个CPU,那么那么可以通过多线程提升训练速度。NUM是线程数量。
带两个参数的命令行例子:
% crf_learn -f 3 -c 1.5 template_filetrain_file model_file
Reference:
《统计学习方法》李航
http://blog.csdn.net/aws3217150/article/details/69212445
http://jingyan.baidu.com/article/39810a23e81f84b636fda62d.html
展开全文
