深度学习目标检测从入门到精通:第一篇
【导读】近日,CV-Tricks.com发布一篇文章,总结了近年来目标检测的各种方法。目标检测可谓是近年来计算机视觉领域热门的研究领域,也具有广阔的应用前景,如自动驾驶等。本文首先系统解释了图像分类和目标检测概念,然后介绍了七种最经典的目标检测方法。其中包括传统的基于特征的目标检测方法,更多的是基于深度学习的目标检测模型,包括近年来目标检测领域中最炙手可热的Faster R-CNN,YOLO,SSD等各种算法。本文向初学者一步步从浅到深介绍各种模型,通过阅读本文,相信你会对目标检测有系统的理解。

Zero to Hero: Guide to Object Detection using Deep Learning: Faster R-CNN,YOLO,SSD
从零到多:使用深度学习的目标检测指南:Faster R-CNN,YOLO,SSD
在这篇文章中,我将解释目标检测和Faster R-CNN,YOLO,SSD等各种算法。 我们将从初学者的层面入手,一直到最新的目标检测算法,了解每种算法的思想,方法和闪光点。
▌什么是图像分类?
图像分类是输入一张图像并预测图像中的目标。例如,当我们建立一个猫狗分类器时,我们输入猫或狗的图像,并预测它们的类别:

如果猫和狗都出现在图像中,你会怎么做?

我们的模型会预测什么?为了解决这个问题,我们可以训练一个多标签分类器来预测这两个类(狗和猫)。但是,我们仍然不知道猫或狗的位置。在图像中识别目标(给定类)位置的问题称为定位。但是,如果目标类不确定,我们不仅要确定位置,还要预测每个目标的类别。
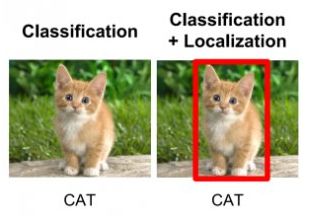
类别与目标的位置一起预测称为目标检测。代替从图像中预测目标的类别,我们现在必须预测类别以及包含该目标的矩形(称为bounding box)。它需要4个变量来唯一标识一个矩形。因此,对于图像中每个目标的实例,我们应该预测以下变量:
class_name, (类别)
bounding_box_top_left_x_coordinate, (左上方x轴坐标)
bounding_box_top_left_y_coordinate, (左上方y轴坐标)
bounding_box_width,(bounding box的宽度)
bounding_box_height,(bounding box的高度)
就像多标签图像分类问题一样,我们可以进行多分类目标检测问题,即在一个图像中检测多种类别物体:
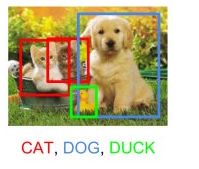
在下面的章节中,我将介绍所有业界流行的目标检测方法。从Viola和Jones于2001年提出的Haar Cascades开始,有很多方法来进行目标检测。但是,我们将聚焦在研究使用神经网络和深度学习这些最先进的方法上。
目标检测被建模成一个分类问题,其中我们从输入图像中获取固定大小的窗口,平滑窗口在所有可能的位置将这些窗口进行图像分类。

每个窗口作为一个样本,使用分类器进行预测,该分类器预测窗口中的目标的类别(如果什么都没有则为背景)。因此,我们知道图像中的目标的类别和位置。 听起来很简单! 那么还有一些问题。你怎么知道窗口的大小,以便它总是包含图像? 看例子:

正如你所看到的,目标大小可以不同。解决这个问题,可以通过缩放图像来创建图像金字塔。想法是我们在多个尺度上调整图像的尺寸,并且我们依靠这样一个事实:我们选择的窗口大小完全包含了某个调整过尺寸的图像中的目标。最常见的情况是,图像被下采样(缩小),直到某些通常条件达到最小尺寸。 在这些图像上,运行固定大小的窗口检测器。 在这样的金字塔上有多达64层也是很常见的。 现在,所有这些窗口被送到分类器以检测感兴趣的目标。这将帮助我们解决大小和位置的问题。
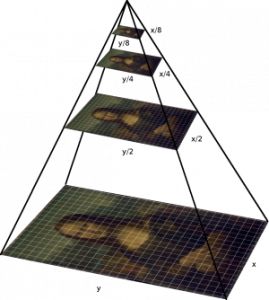
还有一个问题,纵横比。许多物体可以以不同的形状呈现,如坐在一起的人将具有与站立的人或睡觉的人不同的纵横比。 我们稍后会在这篇文章中介绍。 RCNN,Faster-RCNN,SSD等目标检测有多种方法,为什么有这么多的方法,每个方法的显著特点是什么? 我们来看一下:
1. 使用Hog Features方向梯度直方图特征进行目标检测
在计算机视觉史上的一篇开创性论文中,NavneetDalal和Bill Triggs在2005年介绍了面向梯度的直方图(Histogram of Oriented Gradients,HOG)特征。方向梯度直方图特征在计算上是省时的,并且适用于许多现实中的问题。 在金字塔上运行滑动窗口获得的每个窗口上,我们计算提供给SVM(支持向量机)的Hog特征以创建分类器。我们能够在视频上实时运行,以进行行人检测,人脸检测以及其他许多目标检测。
2.基于区域的卷积神经网络(R-CNN)
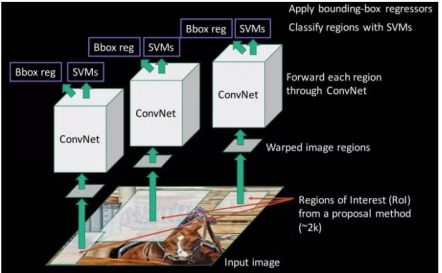
由于我们已经将目标检测建模为分类问题,成功取决于分类的准确性。深度学习的兴起之后,显而易见的想法是用更准确的基于卷积神经网络的分类器代替基于HOG分类器。但是,有一个问题。CNN太慢,计算上非常昂贵。在滑动窗口检测器产生的很多patch上运行CNN是不可能的。R-CNN通过使用称为选择性搜索的目标提议算法( Selective Search)来解决这个问题,该算法减少了送给分类器的边界框的数量,每次差不多接近2000个建议区域。选择性搜索使用局部关键特征,如纹理,强度,颜色和/或内部度量等来生成目标的所有可能的位置。现在,我们可以把这些产生的区域喂给我们的基于CNN的分类器。请记住,CNN的全连接部分需要一个固定大小的输入,所以我们调整(不保留宽高比)所有生成的框到一个固定的大小(224×224的VGG),并馈送到CNN部分。因此,R-CNN有三个重要部分:
1.运行Selective Search (选择性搜索)来生成可能的目标。
2.将1中得到的这些patch提供给CNN,然后用SVM预测每个patch的类别。
3.通过分别训练 bounding box回归来优化patch。
3.空间金字塔池(SPP-net)
然而,RCNN非常缓慢,因为通过 Selective search得到的2000个目标区域在进入CNN网络中运算需要大量的时间。SPP-Net试图解决这个问题。使用SPP-net,我们只计算一次整个图像的CNN表示,并且可以使用它来计算由 Selective search生成的每个patch的CNN表示。这可以通过仅仅在对应于该区域最后一个卷积层的特征映射上执行池化操作来完成。对应的区域卷积层的矩形截面可以通过考虑中间层的下采样进行卷积层区域映射计算得到(在VGG的情况下简单地将坐标除以16)。
还有一个挑战:我们需要为CNN的全连接层产生固定大小的输入,所以SPP使用了更多的技巧。它在最后的卷积层之后使用空间金字塔(spatial pooling ),而不是传统上使用的最大池化(max-pooling)。SPP层将任意大小的区域划分为恒定数量的bins,并且在每个bin上执行最大池化(max-pooling)。由于bins的数量保持不变,所以如下图所示产生恒定的尺寸矢量。
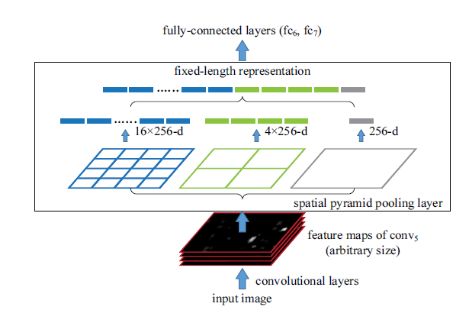
然而,SPP网络有一个很大的缺点,通过空间金字塔层进行反向传播是微不足道的。 因此,网络只调整了网络的全连接部分。我们将在后面看到SPP-Net为更流行的Fast RCNN铺平了道路。
4. Fast R-CNN
Fast R-CNN使用了SPP-net和RCNN的思想,并解决了SPP-net中的关键问题,即它们可以进行端到端训练。为了通过空间池化来传播梯度,它使用了一个简单的反向传播计算,与最大池化(max-pooling)梯度计算非常相似,区别在于池化区域重叠,因此一个单元可以从多个区域抽取梯度。
Fast RCNN还做了一件事,它在神经网络训练本身中加入了bounding box 回归。所以现在网络上有两个输出,即分类输出和 bounding box 回归输出。多任务目标函数是Fast-rcnn的一个显著特点,它不再需要分别训练网络进行分类和定位。 由于CNN的端到端学习,这两个改变减少了整体训练时间,并且相对于SPP网络提高了准确性。
5. Faster R-CNN
Faster R-CNN有什么改进?它是如何实现更快的?Fast RCNN中最慢的部分是Selective Search或 Edge boxes。Faster RCNN用称为区域建议网络RPN(Region Proposal Network)一个非常小的卷积网络来替代selective search来生成兴趣区域。
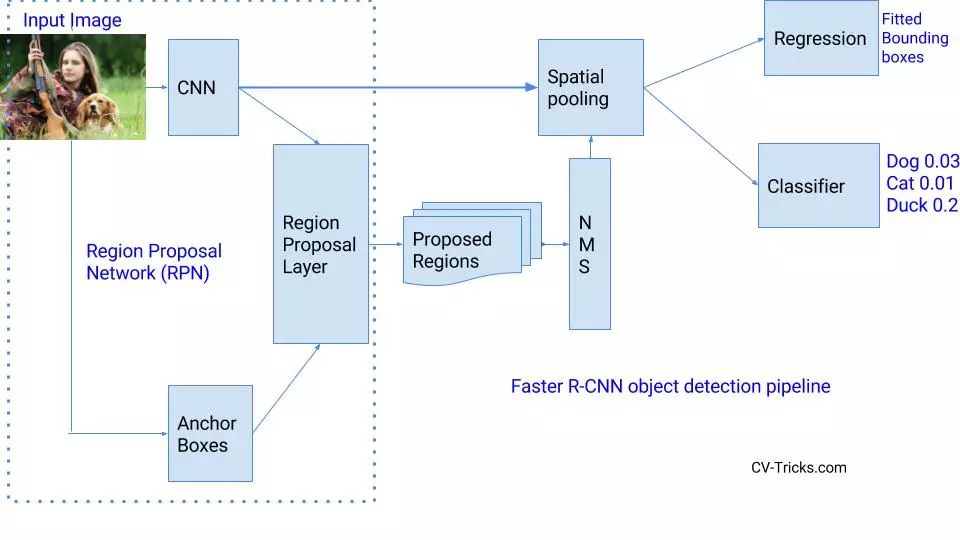
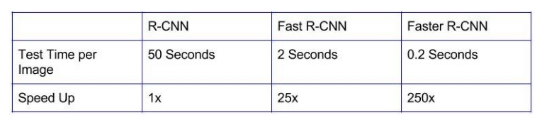
为了应对长宽比和物体尺寸的变化,Faster R-CNN引入了锚框(anchor boxes)的思想。在每个位置,原始论文使用128x128,256×256和512×512比例的三种锚框。同样,对于宽高比,它使用三种宽高比:1:1,2:1和1:2。所以,在每个位置我们有总共9个boxes,RPN预测这9个boxes是背景或前景的概率。我们应用 bounding box回归来改进每个位置的锚框。因此,RPN给出了各种大小的bounding boxes和其相应每个类的概率。像Fast-RCNN一样,可以通过应用空间池化来进一步传递不同大小的边界框。 剩下的网络与Fast-RCNN相似。 . Faster-RCNN比Fast-RCNN快10倍,在VOC-2007数据集上准确率一样。 这就是为什么Faster-RCNN一直是最精确的目标检测算法之一。 这是RCNN各种版本之间的速度比较。
基于回归的目标检测方法
到目前为止,所有讨论的方法都是通过建立一个管道(pipeline )产生很多建议区域,然后将这些得到的建议区域进行分类/回归操作,将检测作为分类问题来处理。但是,有几种方法是将检测作为回归问题。其中两个最流行的是YOLO和SSD。 这些检测方法也被称为single shot 检测方法(一步法)。我们来看看它们:
6. YOLO(You only Look Once)
对于YOLO来说,检测是一个简单的回归问题,它需要输入图像并学习类概率和bounding box 坐标。听起来很简单?
YOLO将每个图像划分为S×S的网格,预测每个网格的N个边界框和置信度。置信度反映了边界框的准确性以及边界框是否包含一个目标(不管是什么类)。YOLO还预测训练中所有类的每个框的分类分数。你可以通过结合两个类的方法来计算每个类出现在预测框中的概率。
预测出了SxSxN个 boxes。然而,这些框中的大部分都具有低置信度分数。如果我们设置一个阈值(如30%的置信度)可以删除其中的大部分,如下面的例子所示
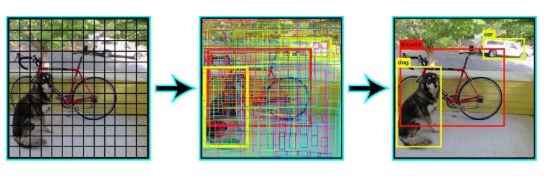
注意,在运行时,我们只在CNN上运行一次图像。 因此,YOLO速度超快,可以实时运行。 另一个关键的区别是,YOLO一次看到完整的图像,而不是以前方法中只查看生成的建议区域。所以,这种上下文信息有助于避免错误。 然而,YOLO的一个限制是它在一个网格中只能预测一种类别,因此不适用于预测小的目标。
7. Single Shot Detector(SSD)
Single Shot Detector在速度和准确度之间取得了良好的平衡。SSD仅在输入图像上运行一个卷积网络并计算特征映射。现在,我们在这个特征映射上运行一个3×3大小的卷积核来预测边界框和分类概率。SSD也使用类似于Faster-RCNN的各种宽高比的anchor boxes ,并学习偏移而不是学习box。为了处理这个尺度,SSD在多个卷积层之后预测边界框。 由于每个卷积层以不同的比例操作,因此能够检测各种比例的目标。
这有很多算法。你应该使用哪一个?目前,如果您对准确率很狂热,则选择Faster RCNN。 但是,如果你计算资源紧缺(可能在Nvidia Jetsons上运行),SSD是一个更好的建议。 最后,如果精度不是太高,但是想要超快速度,YOLO将会是一个很好的选择。下图是对速度与精度之间平衡的一个示意图:

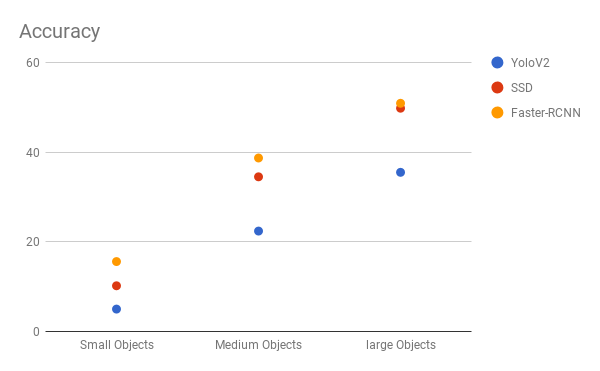
SSD似乎是一个不错的选择,因为我们可以在视频上运行它,而且精度的折衷很少。 但是,可能并不那么简单,请查看此图表,它比较了SSD,YOLO和Faster-RCNN在各种大小物体上的性能。 在大尺寸下,SSD似乎与Faster-RCNN类似。 但是,当物体尺寸较小时,我们以精度来衡量,其差距就会扩大。
选择正确的目标检测方法是至关重要的,取决于你正试图解决的问题和设置。目标检测是计算机视觉许多实际应用的基础,例如自动驾驶汽车,安防和监控以及许多工业应用。希望这篇文章给你一些思路,帮助你理解每个流行的目标检测算法背后的原理。
参考链接:
http://cv-tricks.com/object-detection/faster-r-cnn-yolo-ssd/
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!
展开全文



