图像分类入门 3-图像分类的基本方法
深度学习模型
深度学习模型是另一类物体分类算法,其基本思想是通过有监督或者无监督的方式学习层次化的特征表达,来对物体进行从底层到高层的描述.主流的深度学习模型包括自动编码器(Auto-encoder)、受限波尔兹曼机(Restricted Boltzmann Machine,RBM)、深度信念网络(Deep Belief Nets,DBN)、卷积神经网络(Convolutional Neural Networks,CNN)、生物启发式模型等.
- 自动编码器:自动编码器(Auto-encoder)是20世纪80年代提出的一种特殊的神经网络结构,并且在数据降维、特征提取等方面得到广泛应用.自动编码器由编码器和解码器组成,编码器将数据输入变换到隐藏层表达,解码器则负责从隐藏层恢复原始输入.隐藏层单元数目通常少于数据输入维度,起着类似“瓶颈”的作用,保持数据中最重要的信息,从而实现数据降维与特征编码.自动编码器是基于特征重构的无监督特征学习单元,加入不同的约束,可以得到不同的变化,包括去噪自动编码器(Denoising Autoencoders)、稀疏自动编码器(Sparse Autoencoders)等,这些方法在数字手写 识别、图像分类等任务上取得了非常好的结果.
- 受限玻尔兹曼机是一种无向二分图模型,是 一种典型的基于能量的模型(Energy Based Models,EBM).之所以称为“受限”,是指在可视层和隐藏层之间有连接,而在可视层内部和隐藏层内部不存在连接.受限玻尔兹曼机的这种特殊结构,使得它具有很好的条件独立性,即给定隐藏层单元,可视层单元之间是独立的,反之亦然.这个特性使得它可以实现同时对一层内的单元进行并行Gibbs采样.受限玻尔兹曼机通常采用对比散度(Contrastive Divergence,CD)算法进行模型学习.受限玻尔兹曼机作为一种无监督的单层特征学习单元,类似于前面提到的特征编码算法,事实上加了稀疏约束的受限玻尔兹曼机可以学到类似稀疏编码那样的Gabor 滤波器模式.
深度信念网络(DBN)是一种层次化的无 向图模型.DBN的基本单元是RBM(Restricted Boltzmann Machine),首先先以原始输入为可视层, 训练一个单层的RBM,然后固定第一层RBM权重,以RBM隐藏层单元的响应作为新的可视层,训练下一层的RBM,以此类推.通过这种贪婪式的监督训练,可以使整个DBN模型得到一个比较好的初始值,然后可以加入标签信息,通过产生式或者判别式方式,对整个网络进行有监督的精调,进一步改善网络性能.DBN的多层结构,使得它能够学习得到层次化的特征表达,实现自动特征抽象,而无监督预训练过程则极大改善了深度神经网络在数据量不够时严重的局部极值问题.Hinton等人通过这种方式,成功将其应用于手写数字识别、语音识别、基于内容检索等领域.
卷积神经网络(CNN)最早出现在20世纪 80年代,最初应用于数字手写识别,取得了一定的成功.然而,由于受硬件的约束,卷积神经网络的高强度计算消耗使得它很难应用到实际尺寸的目标识别任务上.Hubel和Wiesel在猫视觉系统研究工作的基础上提出了简单、复杂细胞理论,设计出来一 种人工神经网络,之后发展成为卷积神经网络.卷积神经网络主要包括卷积层和汇聚层,卷积层通过用固定大小的滤波器与整个图像进行卷积,来模拟Hubel和Wiesel提出的简单细胞.汇聚层则是一种降采样操作,通过取卷积得到的特征图中局部区块的最大值、平均值来达到降采样的目的,并在这个过程中获得一定的不变性.汇聚层用来模拟Hubel和Wiesel理论中的复杂细胞.在每层的响应之后通常还会有几个非线性变换,如sigmoid、tanh、relu等, 使得整个网络的表达能力得到增强.在网络的最后通常会增加若干全连通层和一个分类器,如 softmax分类器、RBF分类器等.卷积神经网络中卷积层的滤波器是各个位置共享的,因而可以大大降低参数的规模,这对防止模型过于复杂是非常有益的,另一方面,卷积操作保持了图像的空间信息,因而特别适合于对图像进行表达.
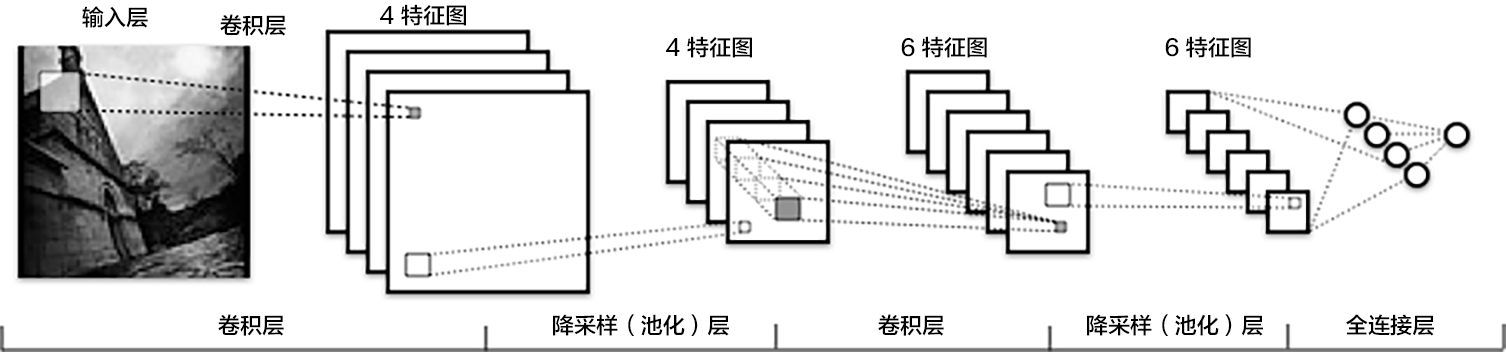
CNN网络示例
- 卷积层(convolution layer): 执行卷积操作提取底层到高层的特征,发掘出图片局部关联性质和空间不变性质。
- 池化层(pooling layer): 执行降采样操作。通过取卷积输出特征图中局部区块的最大值(max-pooling)或者均值(avg-pooling)。降采样也是图像处理中常见的一种操作,可以过滤掉一些不重要的高频信息。
- 全连接层(fully-connected layer,或者fc layer): 输入层到隐藏层的神经元是全部连接的。
- 非线性变化: 卷积层、全连接层后面一般都会接非线性变化层,例如Sigmoid、Tanh、ReLu等来增强网络的表达能力,在CNN里最常使用的为ReLu激活函数。
- Dropout [10] : 在模型训练阶段随机让一些隐层节点权重不工作,提高网络的泛化能力,一定程度上防止过拟合。
下面是卷积神经网络领域中比较有名的几种结构:
LeNet: 第一个成功的卷积神经网络应用,是Yann LeCun在上世纪90年代实现的。当然,最著名还是被应用在识别数字和邮政编码等的LeNet结构。
AlexNet:AlexNet卷积神经网络在计算机视觉领域中受到欢迎,它由Alex Krizhevsky,Ilya Sutskever和Geoff Hinton实现。AlexNet在2012年的ImageNet ILSVRC 竞赛中夺冠,性能远远超出第二名(16%的top5错误率,第二名是26%的top5错误率)。这个网络的结构和LeNet非常类似,但是更深更大,并且使用了层叠的卷积层来获取特征(之前通常是只用一个卷积层并且在其后马上跟着一个汇聚层)。
GoogLeNet:ILSVRC 2014的胜利者是谷歌的Szeged等实现的卷积神经网络。它主要的贡献就是实现了一个奠基模块,它能够显著地减少网络中参数的数量(AlexNet中有60M,该网络中只有4M)。还有,这个论文中没有使用卷积神经网络顶部使用全连接层,而是使用了一个平均汇聚,把大量不是很重要的参数都去除掉了。GooLeNet还有几种改进的版本,最新的一个是Inception-v4。
VGGNet:ILSVRC 2014的第二名是Karen Simonyan和 Andrew Zisserman实现的卷积神经网络,现在称其为VGGNet。它主要的贡献是展示出网络的深度是算法优良性能的关键部分。他们最好的网络包含了16个卷积/全连接层。网络的结构非常一致,从头到尾全部使用的是3x3的卷积和2x2的汇聚。他们的预训练模型是可以在网络上获得并在Caffe中使用的。VGGNet不好的一点是它耗费更多计算资源,并且使用了更多的参数,导致更多的内存占用(140M)。其中绝大多数的参数都是来自于第一个全连接层。后来发现这些全连接层即使被去除,对于性能也没有什么影响,这样就显著降低了参数数量。
ResNet:残差网络(Residual Network)是ILSVRC2015的胜利者,由何恺明等实现。它使用了特殊的跳跃链接,大量使用了批量归一化(batch normalization)。这个结构同样在最后没有使用全连接层。读者可以查看何恺明的的演讲(视频,PPT),以及一些使用Torch重现网络的实验。ResNet当前最好的卷积神经网络模型(2016年五月)。何开明等最近的工作是对原始结构做一些优化,可以看论文Identity Mappings in Deep Residual Networks,2016年3月发表。
两类模型的联系和区别
这里我们将最为流行的词包模型与卷积神经网络模型进行对比,发现两者其实是极为相似的.在词包模型中,对底层特征进行特征编码的过程,实际上近似等价于卷积神经网络中的卷积层,而汇聚层所进行的操作也与词包模型中的汇聚操作一样.不同之处在于,词包模型实际上相当于只包含了一个卷积层和一个汇聚层,且模型采用无监督方式进行特征表达学习,而卷积神经网络则包含了更多层的简单、复杂细胞,可以进行更为复杂的特征变换,并且其学习过程是有监督过程的,滤波器权重可以根据数据与任务不断进行调整,从而学习到更有意义的特征表达.从这个角度来看,卷积神经网络具有更为强大的特征表达能力,因此它在图像识别任务中的出色性能就很容易解释了.
展开全文



